Launch production-grade architectures using Pinecone's vector database in minutes with the AWS Reference Architecture
Pinecone’s vector database scales to billions of vectors and returns queries in milliseconds.
We’ve heard from customers that our many open-source Jupyter notebooks and example applications are ideal for hands-on learning and exploring new AI techniques, but it’s less clear how to go to production with AI applications leveraging Pinecone’s vector database at scale.
So today, we’re going beyond examples and open-sourcing our AWS Reference Architecture, defined via Infrastructure as Code with Pulumi. In minutes, users can deploy high-scale systems using Pinecone in their AWS accounts.
You can also read our technical walkthrough post on the Reference Architecture here.
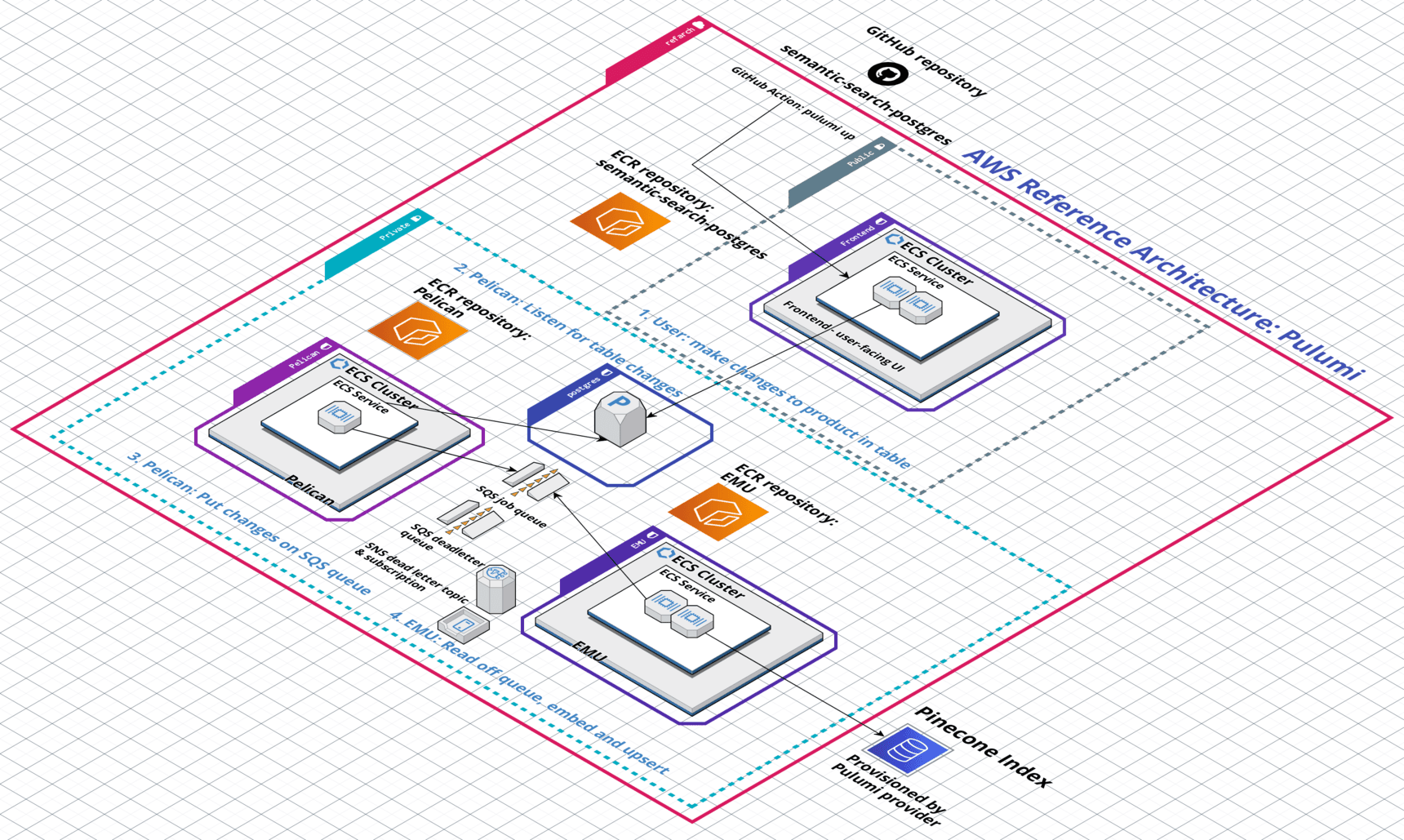
The Reference Architecture has been tested with batches ranging from 10,000 to 1 million records. It is the fastest way to deploy production-ready systems leveraging Pinecone’s vector database at scale.
Try it out!
The Pinecone AWS Reference Architecture is open-source and free to use. We have a quick start guide in the README focused on getting the system up and running in your AWS account as quickly as possible.
Launching the Pinecone AWS Reference Architecture requires setting three environment variables you can get from a free Pinecone account and then running `pulumi up.` The Reference Architecture takes around 14 and a half minutes to deploy fully.
The Pinecone open-source team is standing by to support users, answer questions, and respond to any issues.
What is the Pinecone AWS Reference Architecture?
The Pinecone AWS Reference Architecture is a fully open-source, distributed system defined in Pulumi and written in TypeScript.
You can run the system to understand our best practices and recommendations, modify the code to your needs, and re-deploy a custom system to help you get your applications into production more quickly.
The Pinecone AWS Reference Architecture encodes best practices for both AWS and Pinecone.
It demonstrates a high-scale distributed system that uses a queue to fan out work as well as networking and security group separation of infrastructure, ECS services for the frontend and backend microservices, and autoscaling configured to expand the worker pool up and down elastically in response to system load.
What does the Pinecone AWS Reference Architecture help you do?
The Pinecone AWS Reference Architecture is the ideal starting point for teams building production systems using Pinecone’s vector database for high-scale use cases.
Vector databases are core infrastructure for Generative AI, and the Pinecone AWS Reference Architecture is the fastest way to deploy a scalable cloud-native architecture.
Since the architecture is defined as code, users can modify it to their specific needs or requirements quickly without having to start from scratch.
Pinecone’s vector database can scale to billions of vectors, and the AWS Reference Architecture uses a job queue and automatically scales workers out and in to elastically process spiking workloads.
The architecture can be used as written or modified in TypeScript to fit any use case that requires processing a large amount of data.
Pinecone provides an easy-to-use API for all vector database operations, including creating new indexes, upserting embeddings, and querying for nearest neighbor results.
Pinecone’s AWS Reference Architecture includes three microservices written in TypeScript using the latest Pinecone Node.js SDK to demonstrate how to provision, query, and instantly update Pinecone indexes.

They’re ideal for learning or modifying to get your use case into production more quickly.
For a more detailed explanation of the Reference Architecture’s components and how they fit together, see our technical walkthrough.
Give it a shot!
In addition to the guides included in the Pinecone AWS Reference Architecture GitHub repository, we also have a complete YouTube video series which includes:
- Setup and initial configuration, required tool installation
- Deploying the Reference Architecture
- Understanding what is deployed
- Autoscaling
- Deploying a jump host to interact with private resources such as the RDS database
- Destroying the deployed Reference Architecture
Was this article helpful?