Introducing cascading retrieval: Unifying dense and sparse with reranking
We're excited to announce new cascading retrieval capabilities, further advancing AI search applications. These enhancements make it seamless to combine dense retrieval, sparse retrieval, and reranking into a unified search pipeline, delivering unparalleled precision, performance, and ease of use. With these updates, Pinecone solidifies its position as the most comprehensive platform for modern AI retrieval.
Our research team has shown that this approach yields up to 48% better performance — and 24% better, on average. These outcomes are made possible by three new capabilities:
- Sparse-only vector index type
- Sparse vector embedding model: pinecone-sparse-english-v0
- State-of-the-art rerankers: cohere-rerank-3.5 and pinecone-rerank-v0
The pros and cons of dense and sparse retrieval
Dense retrieval has become a foundation of modern search systems due to its ability to capture the semantics of unstructured data. Likewise, dense embedding models excel at understanding the meaning and context of queries and documents, enabling powerful semantic search.
However, these same models often face challenges with exact matches for specific entities, keywords, or proper nouns — elements that can be critical for keyword or lexical search use cases.
Sparse or lexical retrieval systems, including techniques like TF-IDF (Term Frequency-Inverse Document Frequency) and BM25, operate differently. Instead of relying on semantics, these methods focus on term frequency distribution, making them highly effective when precision and exact keyword matches are essential. This is especially true in scenarios involving domain-specific terminology.
Yet, despite their precision, lexical methods have notable limitations, too—including the ability to understand semantic relationships, such as synonyms or paraphrases, that dense embeddings handle intuitively. For instance, a query for “buying a car” might not retrieve documents containing “purchasing an automobile” because the exact terms don’t overlap.
Until now, developers have had to choose one approach or the other, resulting in tradeoffs and performance gaps.
Unlocking the best of both worlds
Pinecone’s new capabilities allow systems to seamlessly combine dense and sparse retrieval, enabling search utilities that capture both semantic understanding and precise keyword matches. Reranking can then be employed to refine the results by evaluating candidates from both methods and assigning a unified relevance score. This cascaded approach ensures precise, contextually relevant results in even the most complex search scenarios.
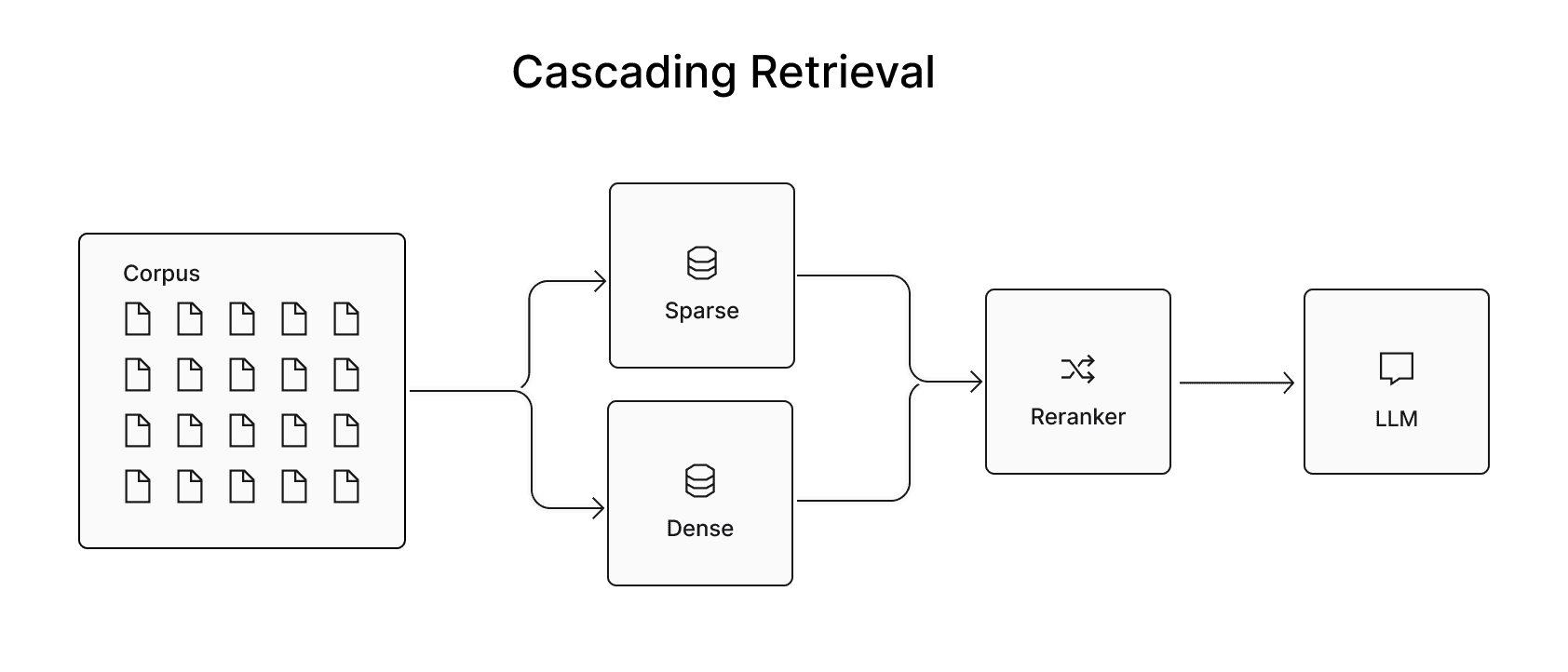
Sparse vector index type for enhanced retrieval
Pinecone has long supported sparse retrieval in serverless indexes, initially combining dense and sparse methods through sparse boosting. Although effective in many scenarios, this hybrid strategy occasionally missed relevant results in keyword-heavy or entity-specific queries.
To address these gaps, we’re introducing sparse-only indexes. Available in early access, these indexes enable direct indexing and retrieval of sparse vectors, supporting traditional methods like BM25 and learned sparse models such as pinecone-sparse-english-v0. By separating dense and sparse workflows, users gain greater control over retrieval strategies, optimizing results for specific use cases.
Our preliminary benchmarks suggest that sparse-only indexes significantly improve performance over sparse-boosting. We will release detailed benchmarks on database performance and retrieval quality soon.
Sparse vector embedding model: pinecone-sparse-english-v0
Alongside the sparse vector index type, we’re also introducing pinecone-sparse-english-v0, a sparse embedding model designed for high-precision, efficient retrieval. Fully integrated into Pinecone’s infrastructure, it streamlines the development of performant search applications with state-of-the-art sparse retrieval capabilities.
Key innovations
Built on the innovations of the DeepImpact architecture[1], the model directly estimates the lexical importance of tokens by leveraging their context. This approach is in contrast with traditional retrieval models like BM25, which rely solely on term frequency.
To illustrate the importance of this difference, consider the term score for the word “does” in the following sentences:

While BM25 assigns similar weights to “does” across these contexts, pinecone-sparse-english-v0 distinguishes their contextual importance, delivering more relevant results [2]. BM25 also struggles in scenarios with short texts, where term frequency lacks variation, leading to suboptimal scoring. On benchmarks, pinecone-sparse-english-v0 outperforms BM25, delivering:
Up to 44% (average 23%) better normalized discounted cumulative gain (NDCG)@10 on Text REtrieval Conference (TREC) Deep Learning Tracks
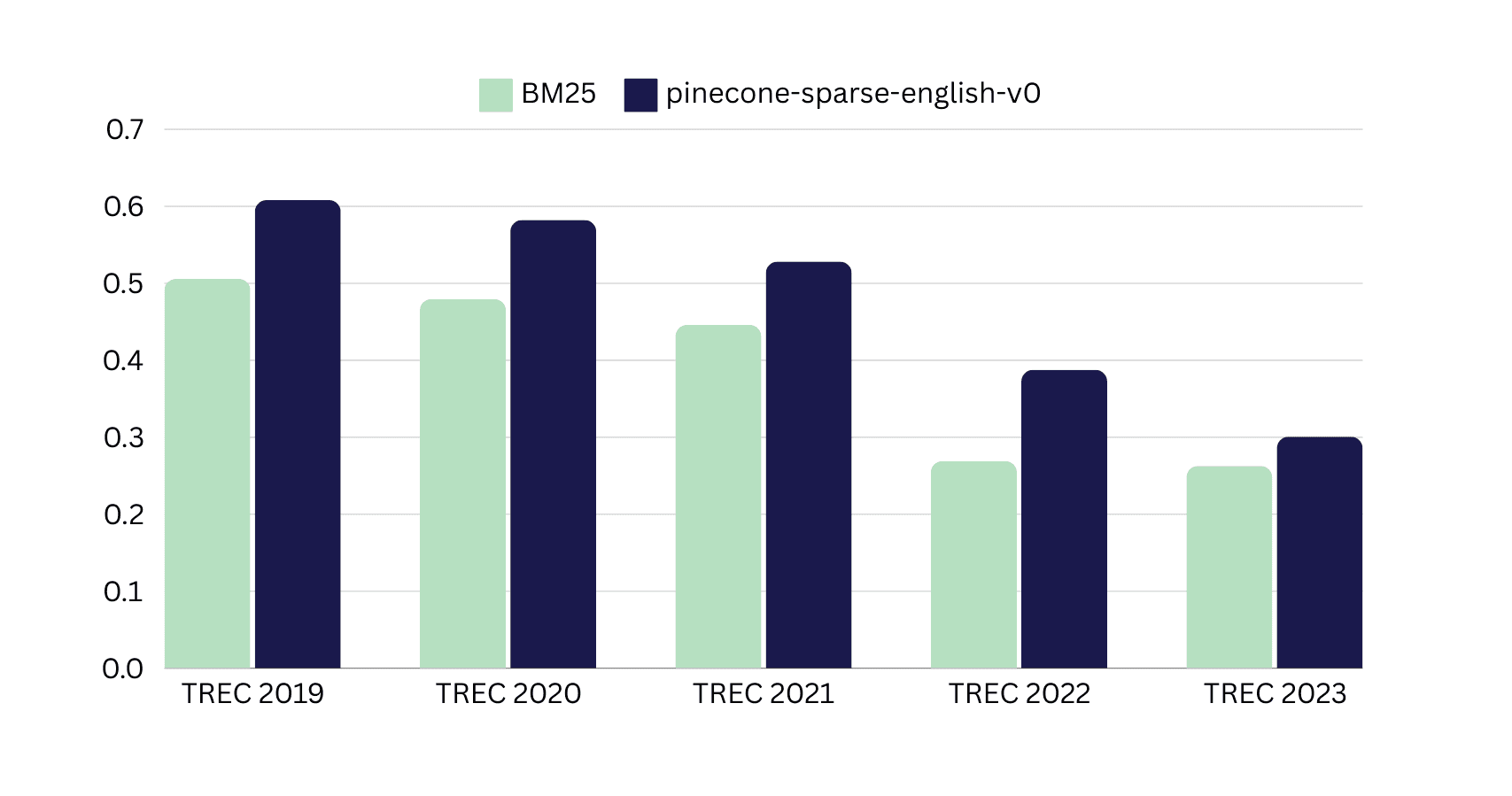
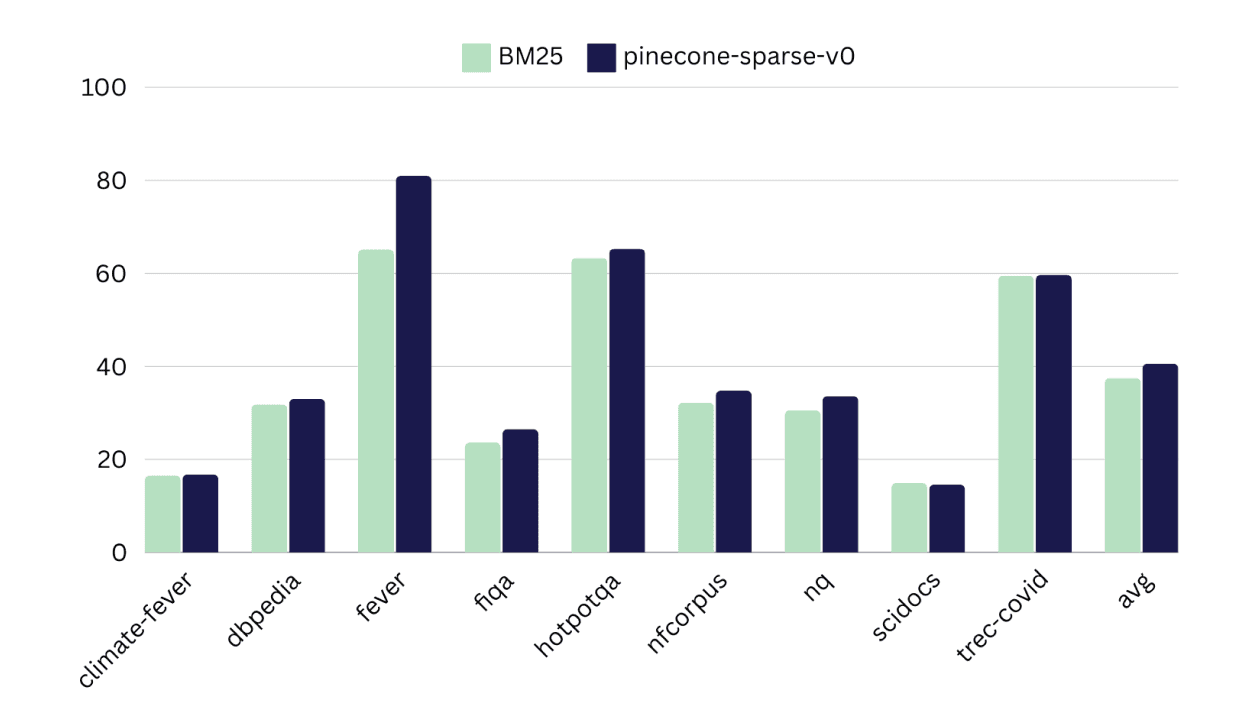
An improvement up to 24% (8% on average) on BEIR
Advantages over other sparse models
The new pinecone-sparse-english-v0 introduces two key innovations that set it apart from models like SPLADE or BGE-M3, enhancing both precision and efficiency:
- Whole-word tokenization for precision
- Model-free queries for speed
Improving precision with whole-word tokenization
Unlike wordpiece tokenization, which fragments terms like “nvidia” into subtokens (e.g., n + ##vid + ##ia), this model uses whole-word tokenization to preserve terms as complete units. It also dynamically generates content-dependent vocabularies, adapting to domain-specific language without relying on static subtokens. This approach improves retrieval for structured queries, such as part numbers or stock tickers, while avoiding irrelevant term expansions common in other sparse models.
Increasing speed with model-free queries
Importantly, pinecone-sparse-english-v0 also eliminates runtime inference during query encoding. Instead, it directly tokenizes and retrieves results, reducing end-to-end latency and infrastructure costs. This model-free approach accelerates response times, making it ideal for real-time applications requiring speed and scalability.
Getting started with Pinecone’s sparse embedding model
You can get started with pinecone-sparse-english-v0 today. To understand how the model is embedding your data, you can toggle on returning the tokens the sparse vector represents.
from pinecone import Pinecone
pc = Pinecone("API-KEY")
pc.inference.embed(
model="pinecone-sparse-english-v0",
inputs=["what is NVIDIA share price"],
parameters={
"input_type": "passage", # or query
"return_tokens": True,
}
)
# Response
...
{
"vector_type": "sparse",
"sparse_values": [0, 2.2207031, 5.3007812, 0, 0.32226562],
"sparse_indices": [767227209, 1181836714, 1639424278, 2021799277, 3888873998],
"sparse_tokens": ["what", "share", "nvidia", "is", "price"]
}Pushing performance results with rerankers
Rerankers refine initial candidate results provided by dense and sparse retrieval methods by scoring query-document pairs based on relevance. This process reorders the results to ensure that only the most relevant information is passed to downstream systems, such as large language models (LLMs). By reducing noise, minimizing hallucinations, and lowering token usage, reranking not only improves end-to-end system quality but also reduces costs.
Using rerankers to combine dense and sparse on BEIR datasets delivers an average improvement of 12% over dense or sparse retrieval alone, and 8% better than score fusion [3].
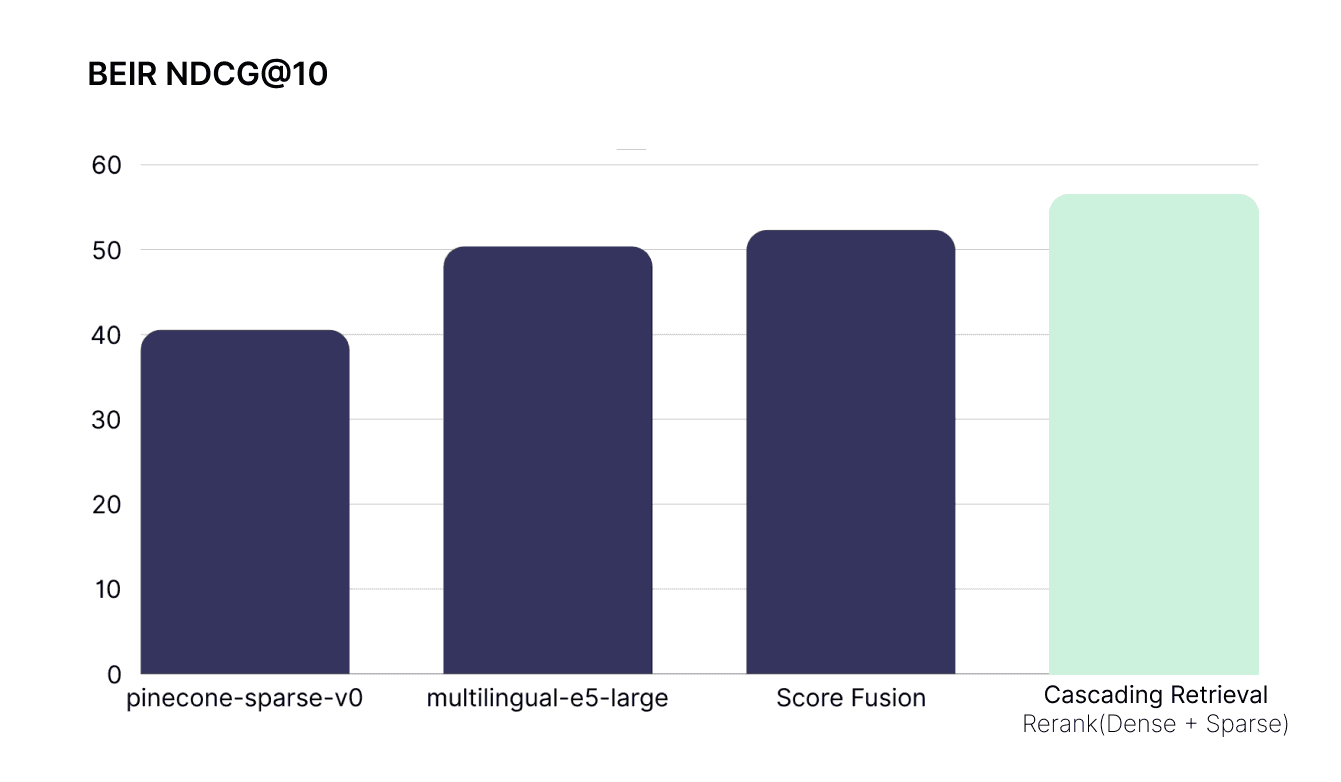
On TREC using rerankers increase performance by up to 48% with an average improvement of 24% over dense vector search.
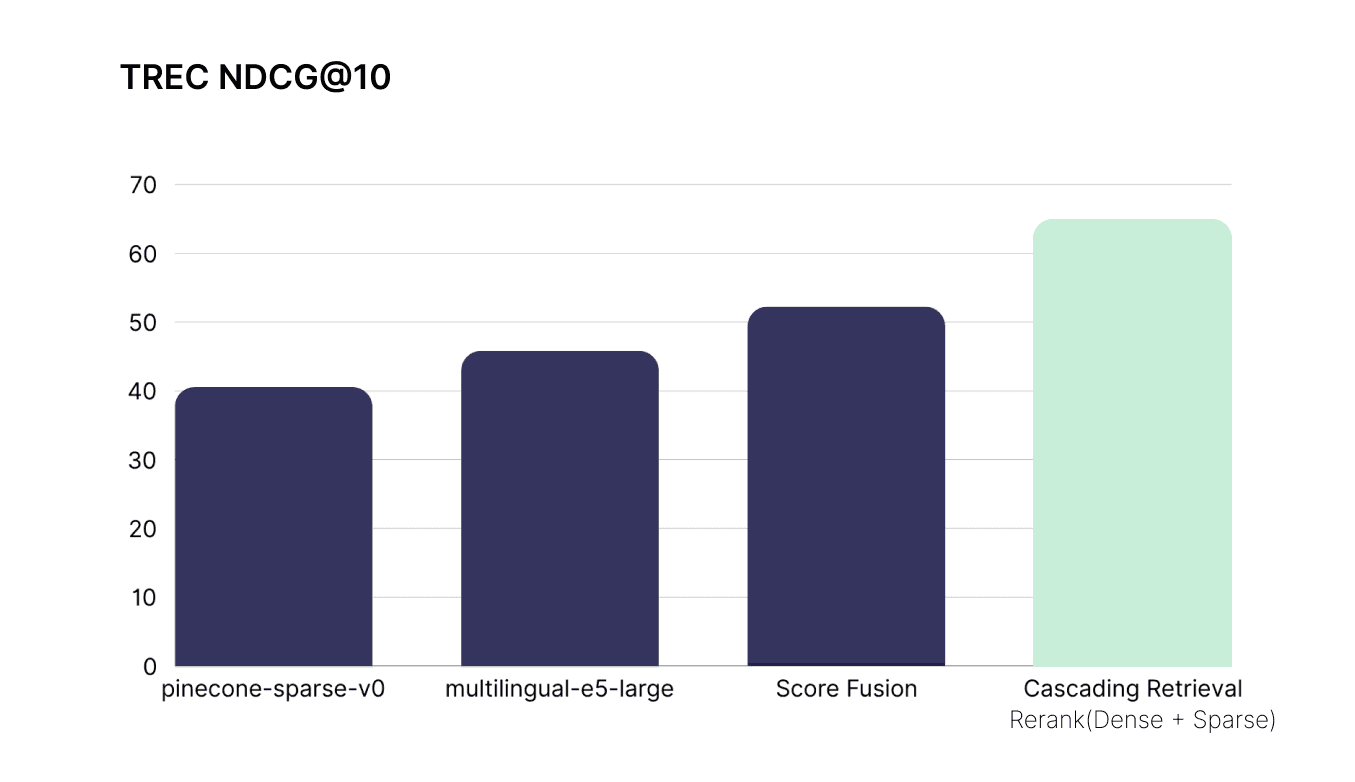
Pinecone now hosts multiple leading proprietary and OSS rerankers, including cohere-rerank-3.5 and pinecone-rerank-v0, which can be accessed through our API.
from pinecone import Pinecone
pc = Pinecone("API-KEY")
query = "what is NVIDIA share price"
sparse_dense_results = [...]
combined_results = pc.inference.rerank(
model="bge-reranker-v2-m3",
query=query,
documents=sparse_dense_results,
top_n=10,
return_documents=True,
parameters={
"truncate": "END"
}
)
print(query)
for r in combined_results.data:
print(r.score, r.document.text)
Building knowledgeable AI
Dense embeddings capture the semantic meaning of queries and documents, while sparse embeddings excel at precise keyword and entity matching. Together, they ensure broad yet accurate coverage. By using Pinecone’s vector database, you can efficiently retrieve candidates from dense and sparse indexes, addressing both semantic and lexical requirements in your queries. Sign up for the sparse index early access today.
Additional resources:
Appendix
- Based on research from Learning Passage Impacts for Inverted Indexes & DeeperImpact: Optimizing Sparse Learned Index Structures
- Previously noted by Mackenzie et al.
- Rank fusion was performed using CombSUM introduced by Fox and Shaw (1994).
Was this article helpful?

