Evolving Pinecone's architecture to meet the demands of Knowledgeable AI
Over the past year, we've seen a significant rise in demand for massive-scale knowledgeable AI applications as companies move from experimentation to production. In particular, this includes:
- Recommender systems requiring 1000s of queries per second
- Semantic search across over billions of documents
- Agentic systems requiring millions of independent agents operating simultaneously
To tackle these scaled workloads head-on, we've continued to evolve our serverless architecture originally released in January 2024, distilling the insights gained from thousands of customers running on it in production. The result is a next-generation vector database that delivers significant advancements:
- Predictable performance with the flexibility of a serverless architecture.
- Highly reliable freshness and the capability to immediately reflect write operations for all workloads.
- Cost effectiveness to run indexes with a large number of small namespaces.
Diverse workloads traditionally require different ANN algorithms
Traditionally, recommender systems have been treated as a “build once, serve many” form of indexing. Often, vector indexes for recommender workloads would be built in batch mode, taking hours. This means such indexes will be hours stale, but it also allows for heavy optimization of the serving index since it can be treated as static.
Graph algorithms like HNSW and Disk ANN are a good fit for this class of workloads. Graph-based indexes are challenging to update, but in this case, since index building happens offline, this isn’t such a big issue.
Furthermore, such indexes are often deployed on large machines with many cores (and high memory in the case of HNSW) and queries are batched as much as possible. Taken together, this configuration achieves the throughput for these relatively static workloads.
Semantic search workloads however are quite different. In these workloads, the corpora are generally far larger (100s of millions to billions of vectors) and require predictable low latency (O(100ms)) - but the throughput itself isn’t very high. They often employ heavy use of metadata filters. These workloads also care about freshness (i.e., whether Pinecone indexes reflect the most recent inserts and deletes) and see moderate to high update rates to their corpora.
This means that graph indexes aren’t best suited for these workloads. Nor are these workloads best served by vertically scaled machines.
Rather, they benefit from indexing techniques that can fall back to local SSD, as well as metadata filtering techniques that can leverage local SSD as much as possible.
And finally, agentic workloads have a very different characteristic compared to the above. They often have small to moderate sized corpora (often fewer than a million vectors) but a lot of namespaces (or tenants). Each tenant is small, and infrequently queried, but when a tenant is queried, the data is expected to be readily available and searched over.
Customers running workloads such as these expect certain features from Pinecone:
- Highly-accurate vector search out of the box so they can focus on their business use cases. (They do not want to become vector search experts and start tuning knobs, choosing algorithms, etc.)
- Freshness, elasticity, and the ability to ingest data. (They do not want to worry about hitting system limits, resharding, and resizing.)
- Predictable, low latencies. (Or, at least, simple, intuitive ways to reason about latencies.)
So how can we handle all these diverse workloads well, given the above constraints?
Key Architectural Innovations
Log structured Indexing
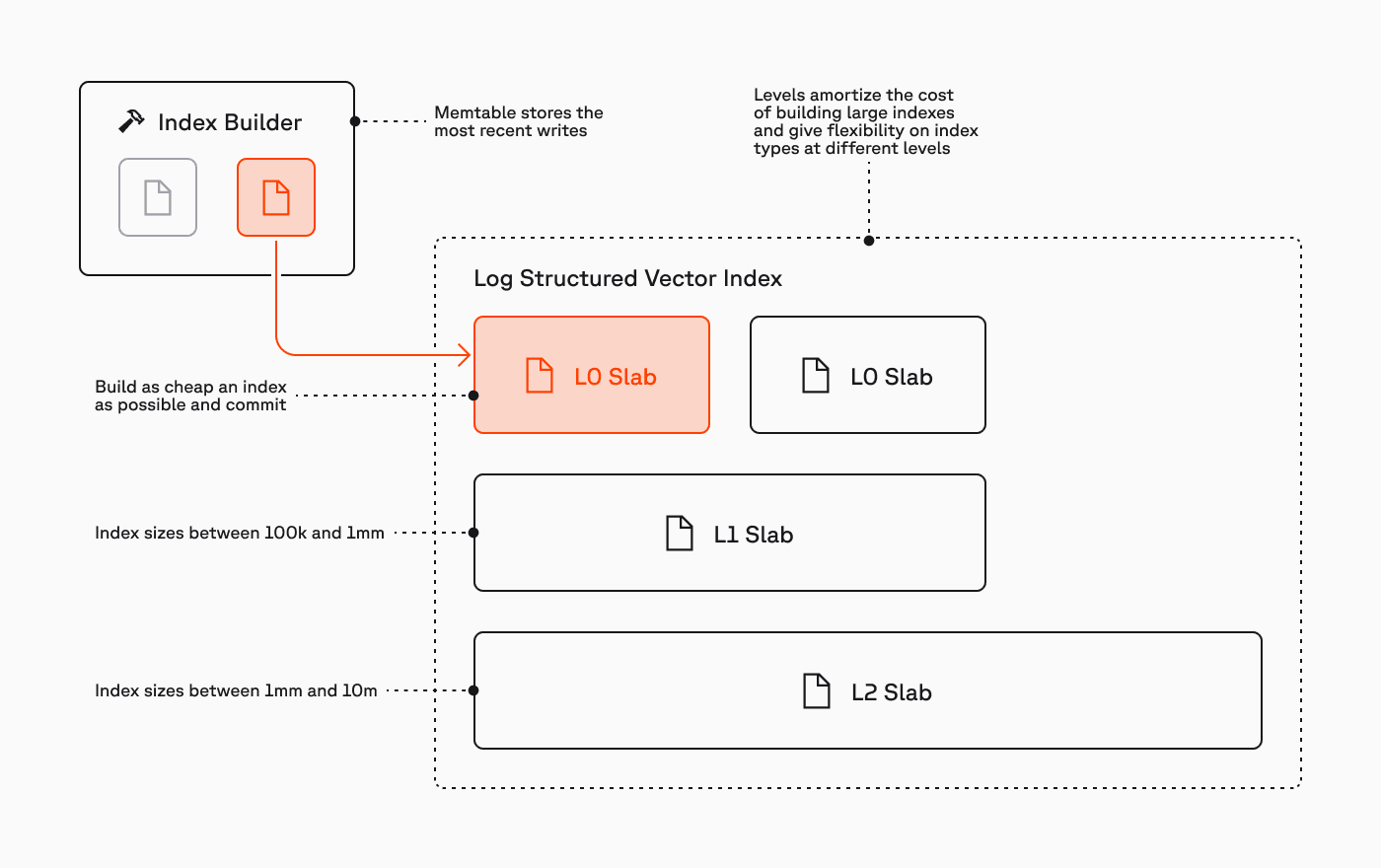
Indexes in Pinecone serverless are composed of files. A collection of files can be thought of as an index (or more precisely a namespace, if you are using namespaces to partition indexes within Pinecone). These files are immutable, and are produced by an index builder.
The index builder has two competing objectives: in order to be fresh, it needs to quickly index data into a file and send it over to the read path for it to be served. At the same time, it needs to opportunistically look to spend more time indexing, so that it can produce a more optimal index for serving. In order to balance these priorities systematically, we employ a log structured indexing scheme that is similar to how log structured key value stores work.
Each file (or “slab” as we call it), can be thought of as logically consisting of the data, the index, the metadata index, and some book-keeping information.
The index type is self describing: this means that everything needed to decode the index and serve it is fully contained in the slab itself regardless of the type of the index.
Writes are first recorded in an in-memory structure called a memtable, which periodically flushes to blob storage, creating an L0 slab once it reaches a predefined size threshold. Since the goal is to make the L0 slabs indexed and queryable as soon as possible, we employ fast indexing techniques like scalar quantization or random projections at this level.
As the number of slabs reaches a size threshold, compaction kicks in. During compaction, smaller slabs are merged into larger slabs, and it is here that we build more computationally intensive partition- or graph-based indexes. By doing so, we amortize the cost of index building through the lifetime of serving those slabs. Compaction for large slabs is handled out of band and coordinated through the index builder.
Freshness
This approach automatically provides high freshness and paves the way to enable strongly consistent reads in the coming months since all reads are routed through the memtable on the index builder. The index builder is always aware of the latest manifest and upon reads, it issues a query to the executors to perform search over all the valid slabs and return the results, which are then merged to return the final candidates.
Users will also still be able to run in an eventually consistent mode where the queries are routed directly to the executors. This can be faster and also ensures high availability at the expense of a small amount of staleness where that tradeoff makes sense.
Predictable caching
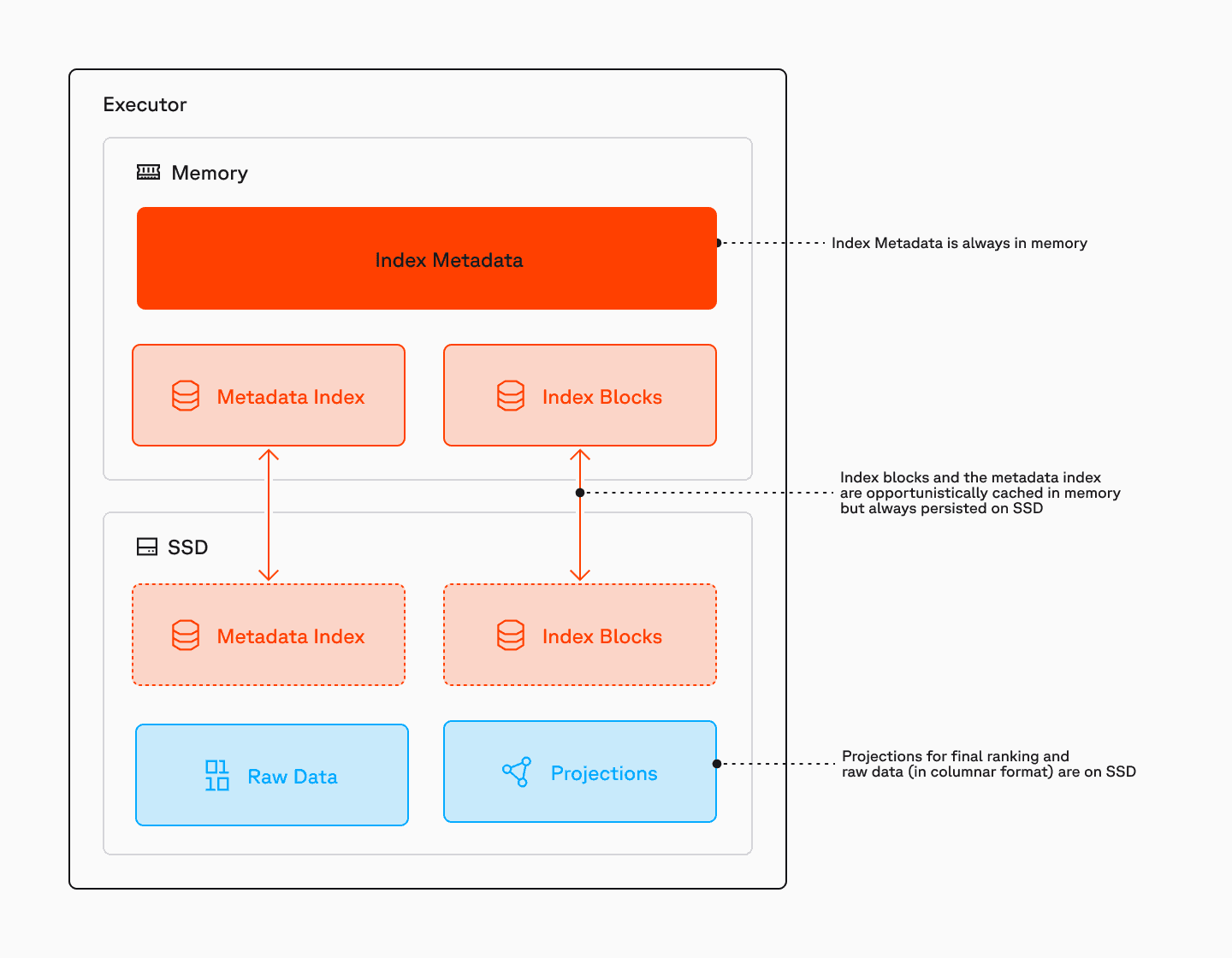
The index portion of the slab is always cached between local SSD and memory. This allows us to serve queries immediately, without having to wait for a warmup period for cold queries.
The index builder sends a prewarming request to the executors upon generating slabs. The executors cache the slab, but reserve the right to evict the raw data if it is not touched for a while. Since the raw data is only needed to return the values and metadata, this means that even if the data isn’t cached it only incurs a small penalty (~250ms) until the data is cached again.
This typically happens after a few queries are run: during this time, the queries will show as cold in their response, and once the queries are operating on cached data, they will indicate as such in their response.
In the upcoming months, we will offer a mode called provisioned capacity, where you can reserve a certain amount of read units for a given index. In this mode, your data is guaranteed to be cached as long as it fits within those limits.
Provisioned capacity is useful when you have predictable workloads and you need eager caching and low tail latencies without incurring the overhead of cold queries.
Cost effective at high QPS
Given slabs have a tremendous amount of flexibility in what indexing can be applied to a given slab, this allows us to finally bring recommender workloads to serverless (where previously this was not possible) while enabling freshness for such workloads for the first time.
Given slabs are immutable, we can easily build any type of index including those that are graph-based, without having to worry about updates. Updates are handled through the log structured indexing scheme as mentioned above. Likewise, freshness is guaranteed by routing queries through the memtable. This allows us to optimize for high QPS workloads by building specific types of indexes that can be cached in memory and local SSD. Such slabs are deployed on specialized nodes with high CPU and memory bandwidth.
The immutability of slabs also makes it easy to replicate for throughput purposes. All of this happens automatically under the hood and needs no user intervention.
This allows us to bring the flexibility of serverless to recommendation workloads. You no longer have to worry about periodically building indexes, or hot swapping indexes in production, or what to do with the freshness lag. You get freshness, high QPS and high recall without any of the maintenance overheads.
Disk-based Metadata Filtering
Disk-based metadata filtering is another new feature in this update of our serverless architecture. Metadata filtering is a hard problem for vector databases. Both graph indexes and clustering-based indexes like IVF often struggle with metadata filters.
To power high-cardinality filtering use cases like access control lists, we've pioneered significant advancements in our single-stage filtering engine. We adapted the concept of bitmap indices commonly used in data warehouses and applied them to vector search. Every slab has a metadata folder, which can be thought of as a bitmap file per field. Low cardinality bitmaps are cached if they are frequently used (within a memory budget). High cardinality bitmaps are efficiently streamed from disk to intersect with the vector index itself in order to efficiently filter rows while scanning.
Some benchmarks
Our latest architecture provides better tail latencies while delivering better performance across the board for the same amount of cluster compute as the serverless system.
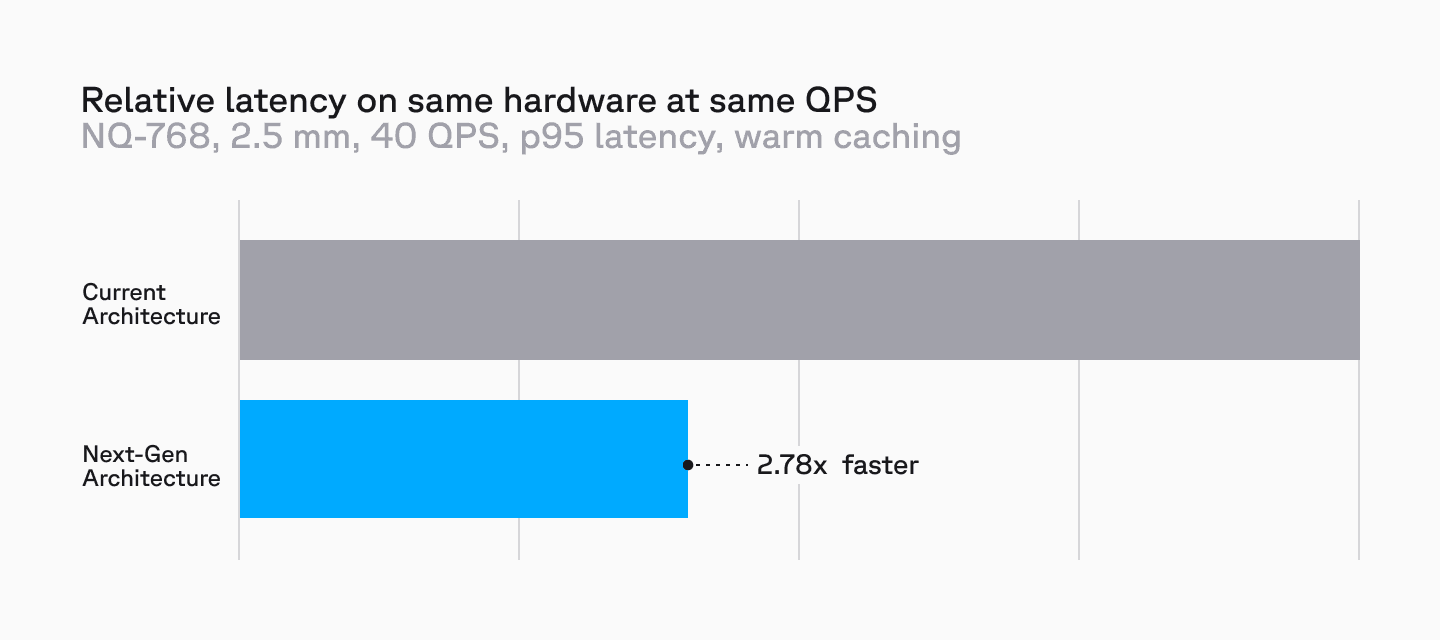
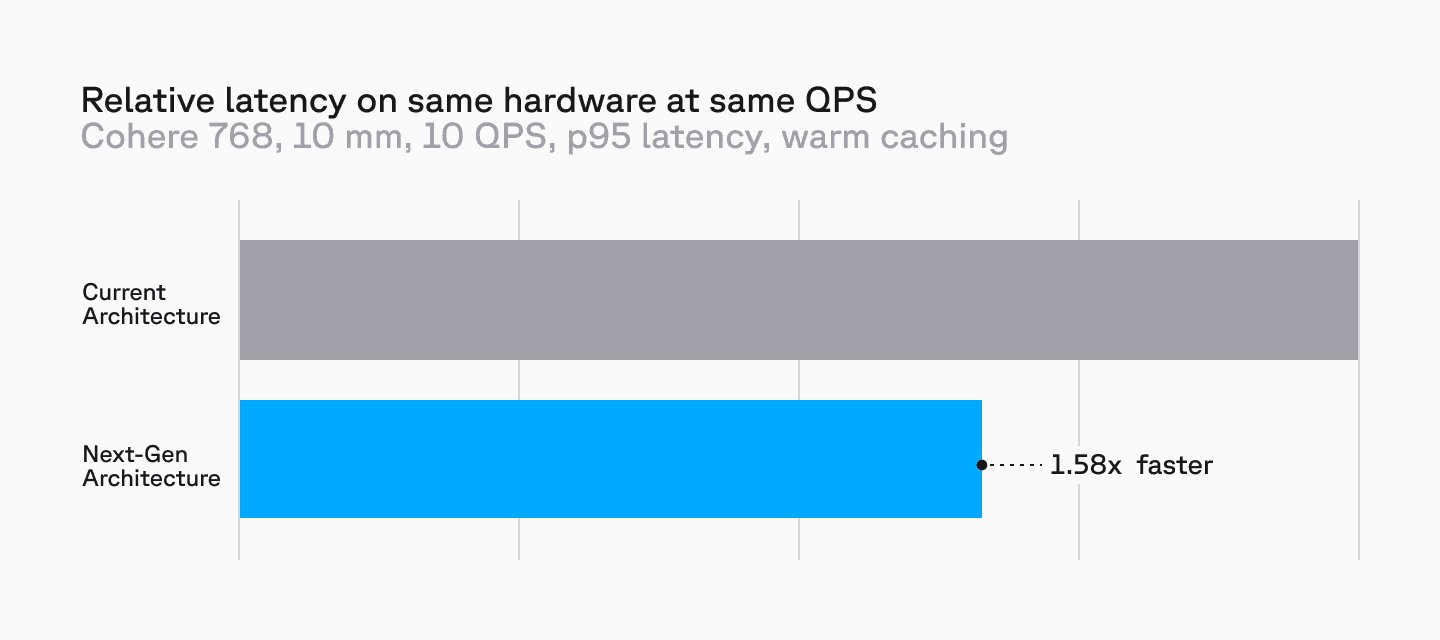
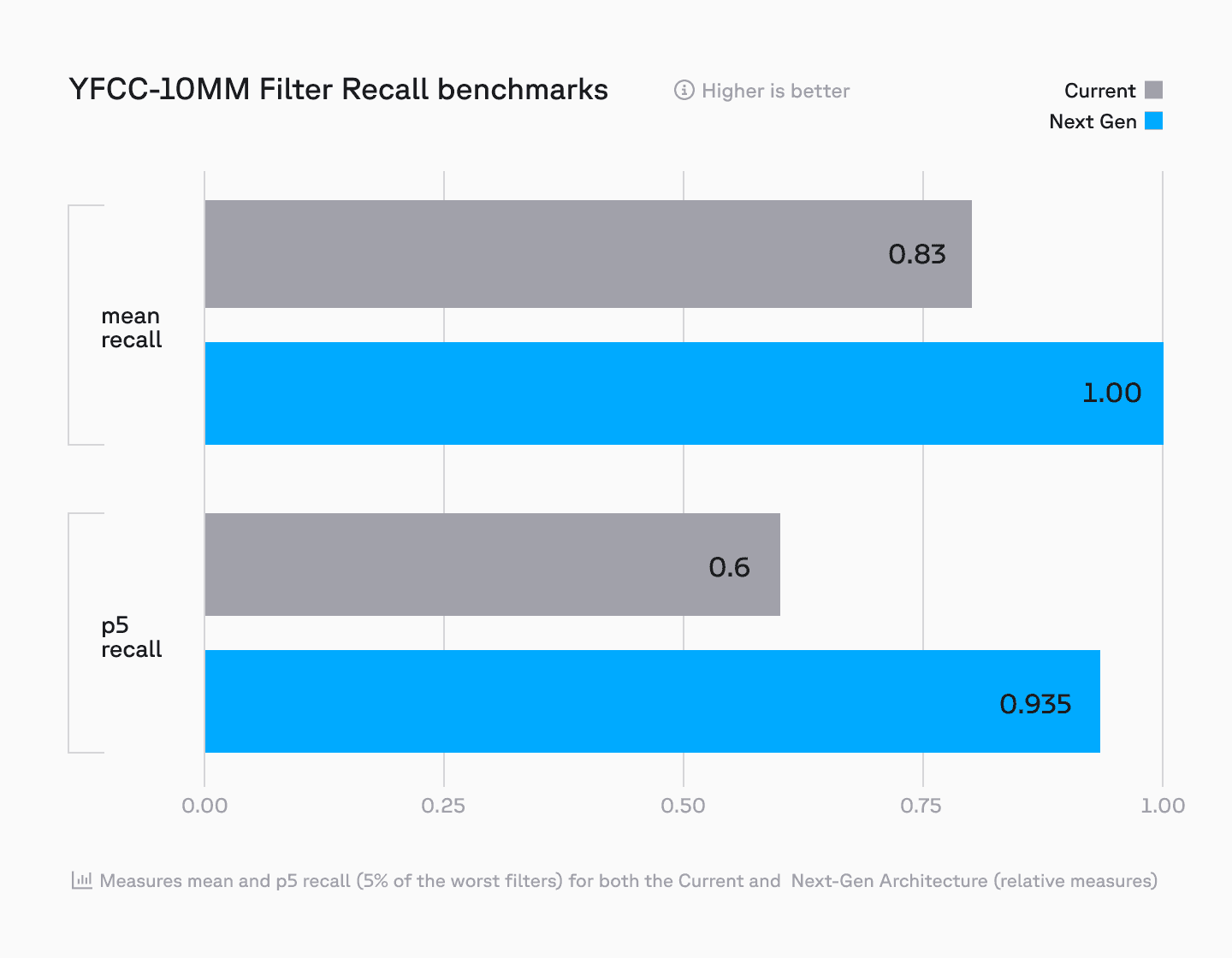
Disk-based metadata filters not only reduce memory usage and enable high cardinality filters to be applied efficiently, they also improve upon recall.
The Road Ahead
This iteration of our architecture represents a major step towards our commitment to deliver accurate, performant, and cost-effective retrieval for any scaled workload in production. But we're just getting started. On the immediate horizon, our next generation architecture enables us to:
- Support seamless and cost-effective scaling to 1000+ QPS through provisioned read capacity
- High performance sparse indexing for higher retrieval quality
- Millions of namespaces per index to support massively multi-tenant use cases
We'll update you with more benchmarks and features during our upcoming Launch Week, March 17-21. Over the coming months, we'll be rolling out these architectural advancements to all serverless users. The best part? It's completely hands-off – simply keep building and let Pinecone handle the rest.




