Vector search just got up to 10x faster, easier to set up, and vertically scalable
Pinecone is paving the way for developers to easily start and scale with vector search.
We created the first vector database to make it easy for engineers to build fast and scalable vector search into their cloud applications. In the past year, hundreds of companies like Gong, Clubhouse, and Expel added capabilities like semantic search, AI recommendations, image search, and AI threat detection to their applications using vector search with Pinecone.
Yet for teams who are new to vector search, some challenges remained:
- It was hard to determine the type and size of index needed for their data and performance needs.
- Supporting high throughput required a lot of hardware, which might’ve been cost-prohibitive.
- Scaling up indexes meant re-uploading data to a new index and interrupting service for the switch-over.
Not anymore. Today we’re excited to announce new features and performance improvements to Pinecone that make it easier and more cost-effective than ever for engineers to start and scale a vector database in production.
What’s new
As of today, these new features are available in Pinecone for all Standard, Enterprise, and Enterprise Dedicated users:
- Vertical Scaling: Scale your vector database with zero downtime
- Collections: Centrally store and reuse your vector embeddings and metadata to experiment with different index types and sizes.
- p2 pods: Achieve up to 10x better performance for high-traffic applications.
We are also announcing:
- Around 50% faster queries on p1 and s1 pods (varies by use case).
- 5x greater capacity on the Starter (free) plan, with the storage-optimized s1 pod now available on the plan.
- Updated pricing that will go into effect for new users starting September 1st, but not for existing customers.
Continue reading for more details, then get started today. Also register for our upcoming demo and read the hands-on walkthrough of these new features.
Vertical Scaling: Scale index capacity with zero downtime
Vertical scaling means no more migrating to bigger indexes or writing to an index already at storage capacity. This is going to be a huge timesaver for us.” — Isabella Fulford, Software Engineer at Mem Labs
The volume of data that a Pinecone index can hold is limited by the number of pods the index is running on. Previously, if your index grew beyond the available capacity you would need to create a new index with more pods, re-upload data to that index, then switch over traffic to the new index, or overprovision the number of pods and pay for unused capacity.
Either way, valuable resources — spend and engineering time — are taken away from more impactful areas of your business.
With vertical scaling, pod capacities can be doubled for a live index with zero downtime. Pods are now available in different sizes — x1, x2, x4, and x8 — so you can start with the exact capacity you need and easily scale your index. Your hourly cost for pods will change to match the new sizes, meaning you still only pay for what you use. See documentation for more detail.
Collections: Experiment with and store vector data in one place
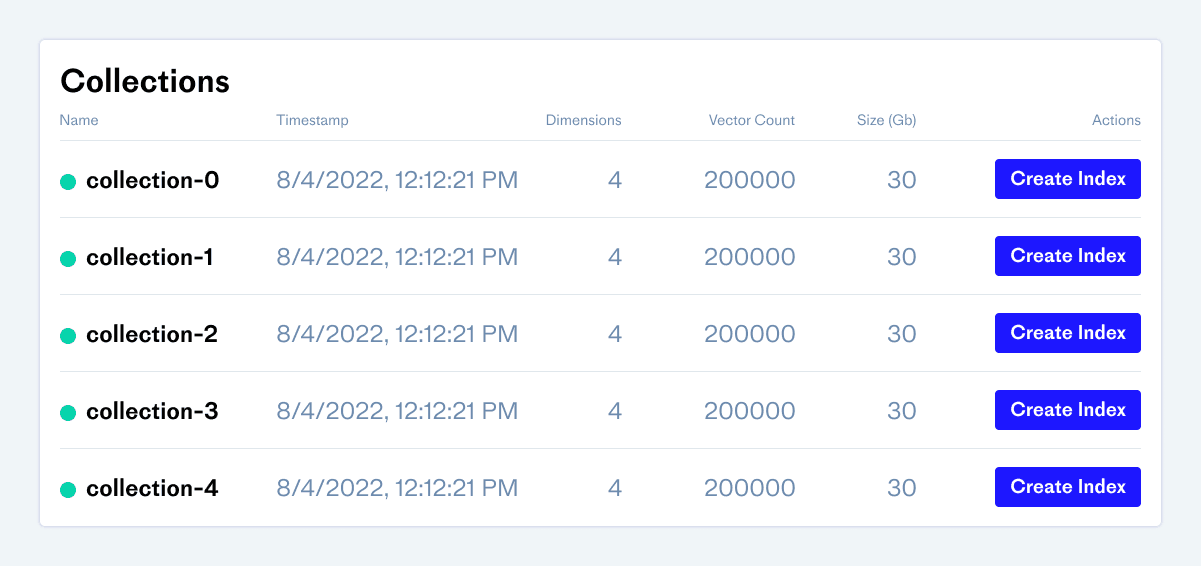
Users rely on Pinecone indexes to store their vector embeddings and associated metadata; they want it to be their source of truth. Before the addition of collections, actions such as temporarily shutting down or creating a new index would require re-uploading the original vector data from a different source. That meant users had to maintain an up-to-date copy of the data outside of Pinecone. Collections will alleviate this pain by providing users with a single source of truth for their vector data within Pinecone.
Today, we are launching the public preview of collections in all Pinecone environments. Users can save data (i.e. vectors and metadata) from an index as a snapshot, and create new indexes from any collection. Whether using collections for backing up and restoring indexes, testing different index types with the same data, or moving data to a new index, users can now do it all within Pinecone. In the near future, collections will allow users to import and export data to and from S3 or GCS blob storage, and write streaming and bulk data directly to collections.
Storage costs for collections will be $0.025/GB per month for all Standard, Enterprise, and Enterprise Dedicated users. Users on the Starter (free) plan can have one collection at no cost. See documentation for more detail.
p2 Pods: Purpose built for performance and high-throughput use cases
While p1 pods provide low search latencies with uniquely fast ingestion speeds, high recall (accuracy of results), and fast filtering, users with high-throughput applications such as social media apps or streaming services require much higher throughput above all else.
The new p2 pod type provides blazing fast search speeds under 10ms and throughput up to 200 queries per second (QPS) per replica.* That’s up to 10x lower latencies and higher throughput than the p1 pod type. It achieves this with a new graph-based index that trades off ingestion speed, filter performance, and recall in exchange for higher throughput. It still supports filtering, live index updates, and all other index operations.
Today, we are launching p2 pods as a public preview available in all Pinecone environments. If you currently use p1 pods with multiple replicas to achieve a high throughput, switching to p2 pods may dramatically lower your total costs. See documentation for more detail.
* Your performance may vary and we encourage you to test with your own data and follow our tips for performance tuning. Latencies are dependent on vector dimensionality, metadata size, metadata cardinality, network connection, cloud provider, and other factors.
Other updates
Faster indexes on s1 and p1 pods
Query speed and performance are only becoming more and more critical for vector search applications, especially for those consumer facing features. That’s why we significantly improved performance for s1 and p1 pods. Users of these pods will now achieve on average 50% lower latency and 50% higher throughput per replica.
The specific performance gain depends on your workload, so you might see a higher or lower difference than this. This change is in effect for all new indexes starting today, and will be rolled out to existing indexes in the coming weeks.
Starter plan to include s1 pods
Getting started with Pinecone is even easier with the addition of s1 pods to our Starter (free) plan. Previously, only p1 pods were available on the Starter plan.
As of today, users can choose between p1 and s1 pods and store 5x more vectors than before. This enhancement gives users the flexibility to more easily experiment with and fully realize the power of vector search with Pinecone.
Pricing update
The features and enhancements announced today provide meaningful cost saving opportunities for all existing and new Pinecone customers, notably:
- s1 and p1 pods now support 50% higher throughput for typical workloads, meaning fewer replicas are needed.
- The new p2 pods, while being more expensive on a per pod-hour basis, provide up to 10x greater throughput, meaning even fewer replicas are needed.
- Vertical scaling eliminates the need to overprovision at the start.
- Collections allow users to delete (and not be billed for) indexes when they’re not being used without losing data.
- Starter users can now store 5x more vectors for free with s1 pods.
Updated pricing for p1 and s1 pods will also go into effect for all new users as of September 1, 2022, starting at $0.096/hour and up depending on plan, pod size, and cloud environment.
Existing users on a paid plan with a running index as of August 31, 2022 will not be affected, and will retain their current rates for s1 and p1.
This means anyone not yet on a paid plan can lock in current rates by upgrading and launching at least a one-pod index by August 31, 2022. See the pricing page for more details or contact us with questions.
Get Started
Today’s releases make it even easier for engineers to start, test, and scale vector databases with greater flexibility, lower cost, and better performance. Get started today by launching your first vector database, contacting us for more information, or registering for the upcoming demo of these new features.
Was this article helpful?