Introducing import from object storage for more efficient data transfer to Pinecone serverless
Today we are introducing the ability to bulk import from object storage for Pinecone’s serverless infrastructure. This new capability makes ingesting large amounts of data more efficient for developers building accurate, secure, and scalable AI applications.
Build knowledgeable AI
Simplifying large scale data ingestion
Import from object storage provides a simple and efficient way of transferring and indexing your initial workload into Pinecone. This streamlines development if you want to run a POC at a large scale (e.g. 100M records), onboard a known or new tenant, experiment with new embedding models, or migrate an entire production workload from another data store to Pinecone.
With import from object storage, you get:
- Up to 6x lower cost: Save up to 6x in initial ingest costs compared to the equivalent upsert-based process. Experiment at production-scale knowing you won’t break the bank. For example, ingesting 10M records of 768-dimension will cost $30 with bulk import.
- Streamlined development: Ingest up to billions of records with significantly less overhead than the equivalent upsert-based process. As an asynchronous, long-running operation, there’s no need for performance tuning or monitoring the status of your import operation. Just set it and forget it; Pinecone will handle the rest.
Note: Imports are limited to 100M records at a time during public preview.
- Easier experimentation: Import from object storage enables your team to iterate faster and focus on ways to optimize performance. Experiment with new models, continuously fine-tune existing embedding models, or test out index configurations with minimal setup and operational overhead.
- Secure access and control: Data is read from a secure bucket in your object storage. This means you have control over who has access to your data, and you can revoke Pinecone’s access at any time.
from pinecone import Pinecone
pc = Pinecone(api_key='YOUR_API_KEY')
index = pc.Index("target_index")
index.start_import(
integration_id="secure-integration-id",
url="s3://bucket/path/to/dir/"
)Initiate a new import request from object storage (e.g. Amazon S3) with a few lines of code.
Experiment and build at production scale today
To get started, you first need to integrate your object store (e.g. Amazon S3) with Pinecone. Pinecone’s storage integrations let you store IAM credentials for your object store and can be set up or managed via the Pinecone console.
Import is done from a new API endpoint that supports Parquet source files. This makes it easy to ingest large datasets stored in object storage. These import operations are restricted to writing records into a new serverless namespace; you cannot import data into an existing namespace.
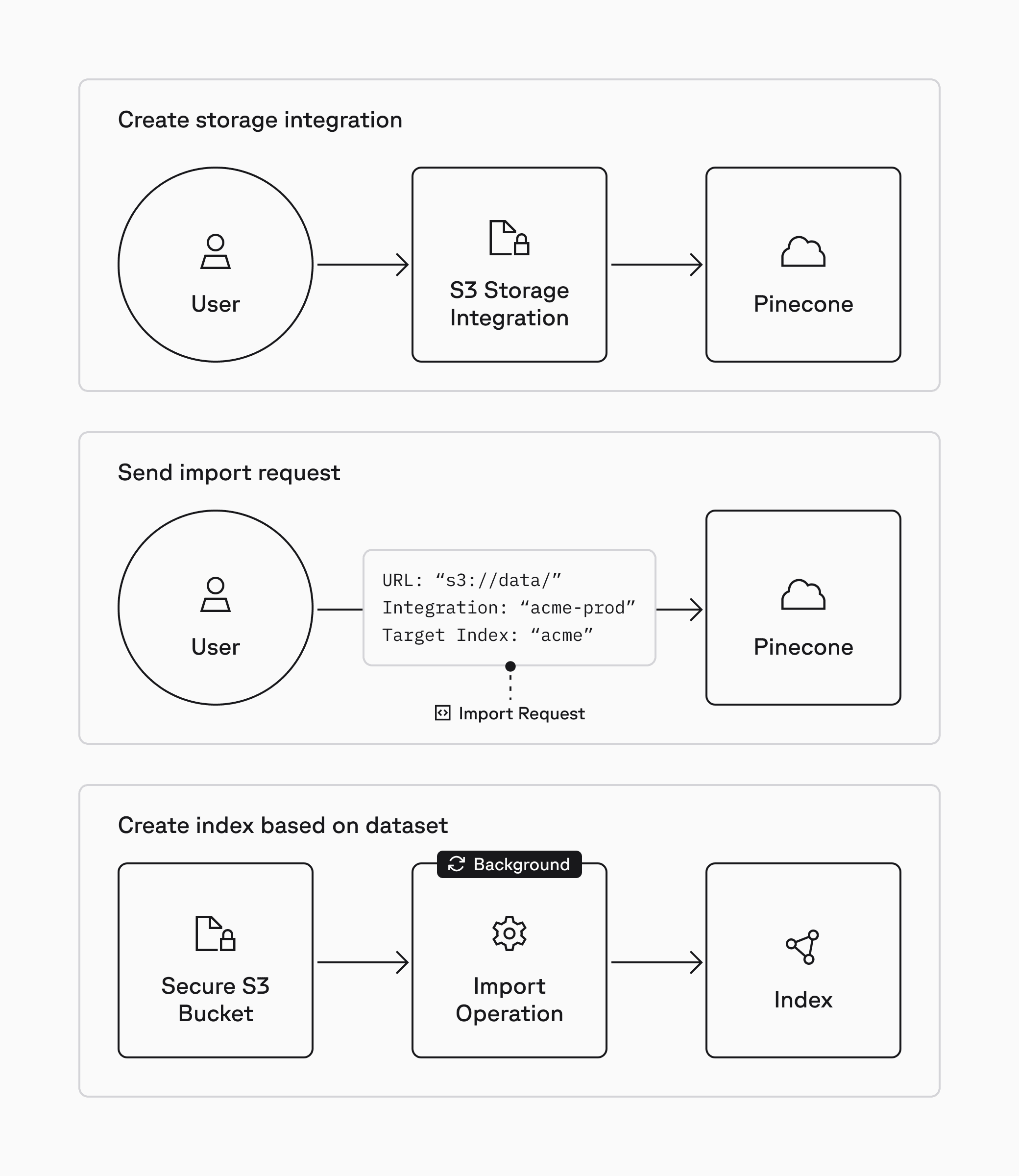
Import from object storage is now available in public preview for Standard and Enterprise users at a flat rate of $1.00/GB. It is currently limited to Amazon S3 for serverless AWS regions. Support for Google Cloud Storage (GCS) and Azure Blob Storage will follow in the coming months. See our documentation to learn more, test it out in our example notebook, and start building today.
Was this article helpful?