Introducing reranking to Pinecone Inference to simplify building accurate AI
Reranking capabilities are now available with Pinecone Inference, an API that provides instant access to fully-managed models hosted on Pinecone’s infrastructure. Embed, manage, query, and rerank with Pinecone via a single API to easily build accurate AI apps grounded in proprietary data faster.
Reranking is in public preview and currently supports the bge-reranker-v2-m3 model with more coming soon.
Start building with reranking
Increase accuracy while reducing hallucination and cost
A reranker is a type of model that scores documents by their semantic relevance to a query. Integrating rerankers into any vector retrieval system, including RAG applications, ensures efficient filtering, and the generative model uses only the most relevant data with fewer computational resources required, improving accuracy and reducing overall latency and cost.
The typical RAG pipeline involves multiple stages, each with its purpose. At each stage the number of documents and tokens decreases significantly allowing for more powerful methods to refine the results.
| Step | Input Tokens | Description |
|---|---|---|
| Retrieve | 25+Million | Identify documents that may be relevant to the search query using an efficient method like vector search. |
| Rerank | 12.5k | Score the retrieved documents and remove irrelevant ones according to relevance using a reranker. |
| Generate | 1200 | Generate a response based on the most relevant data using an LLM |
*Assuming a corpus of 250 tokens per document, 50 retrieved docs, and five passed to generate.
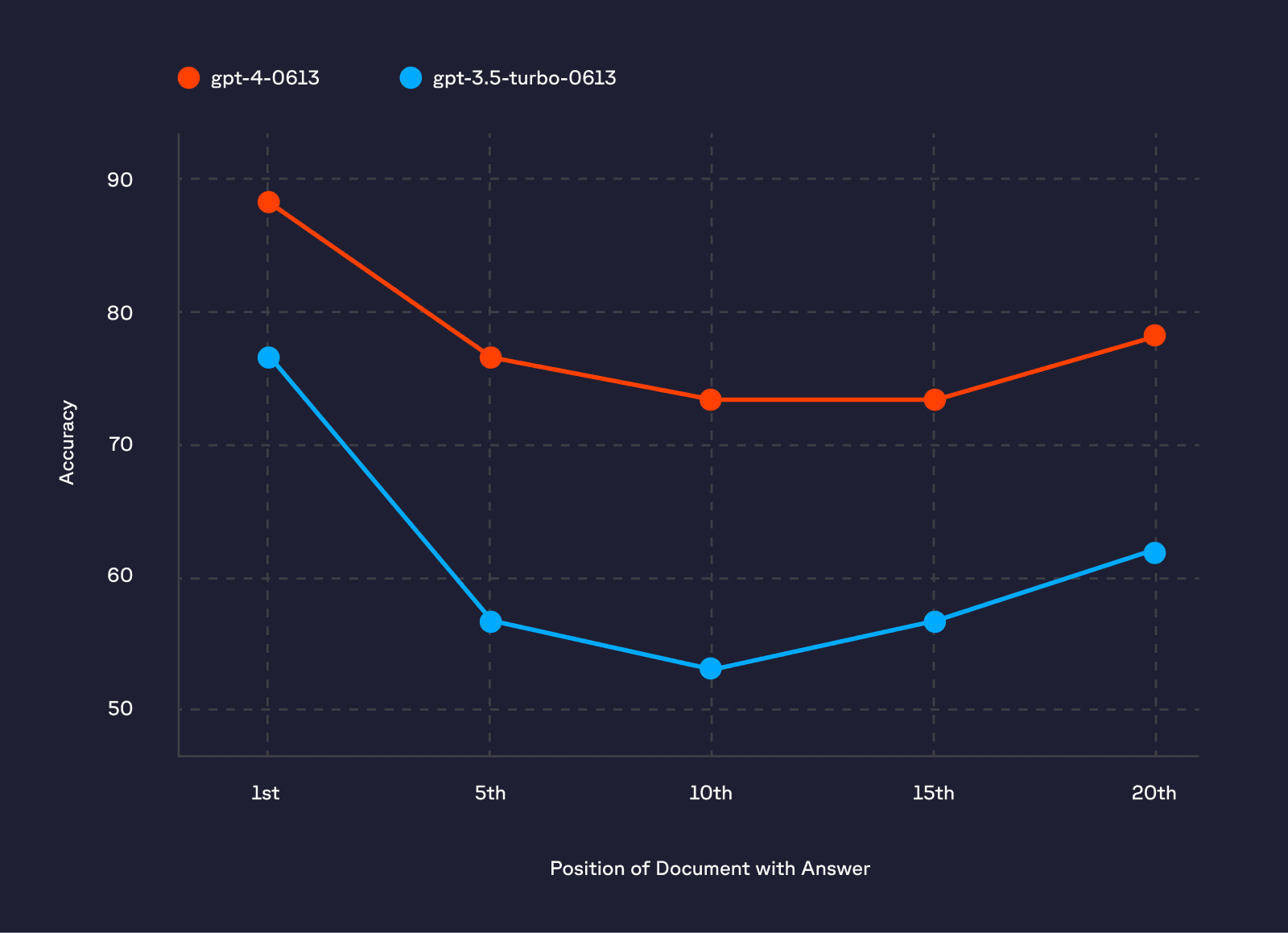
Even though LLMs have large context windows, providing more data does not necessarily increase answer accuracy; in many cases, it can reduce it—a phenomenon researchers call ‘Lost in the Middle.’ [1] When the document containing the answer is not placed near the beginning of the context, performance tends to decline. Reranking optimizes the order of the documents and removes irrelevant documents, thereby increasing the accuracy of the answers.
Despite the rapid decline in LLM costs over the past year, the expense of productionizing a pipeline can still be significant. Input tokens from the context passed to the LLM often drive up costs, even when they contribute little or no essential content for generation. Pinecone’s rerankers can reduce these costs by 85% when used with gpt4-o.
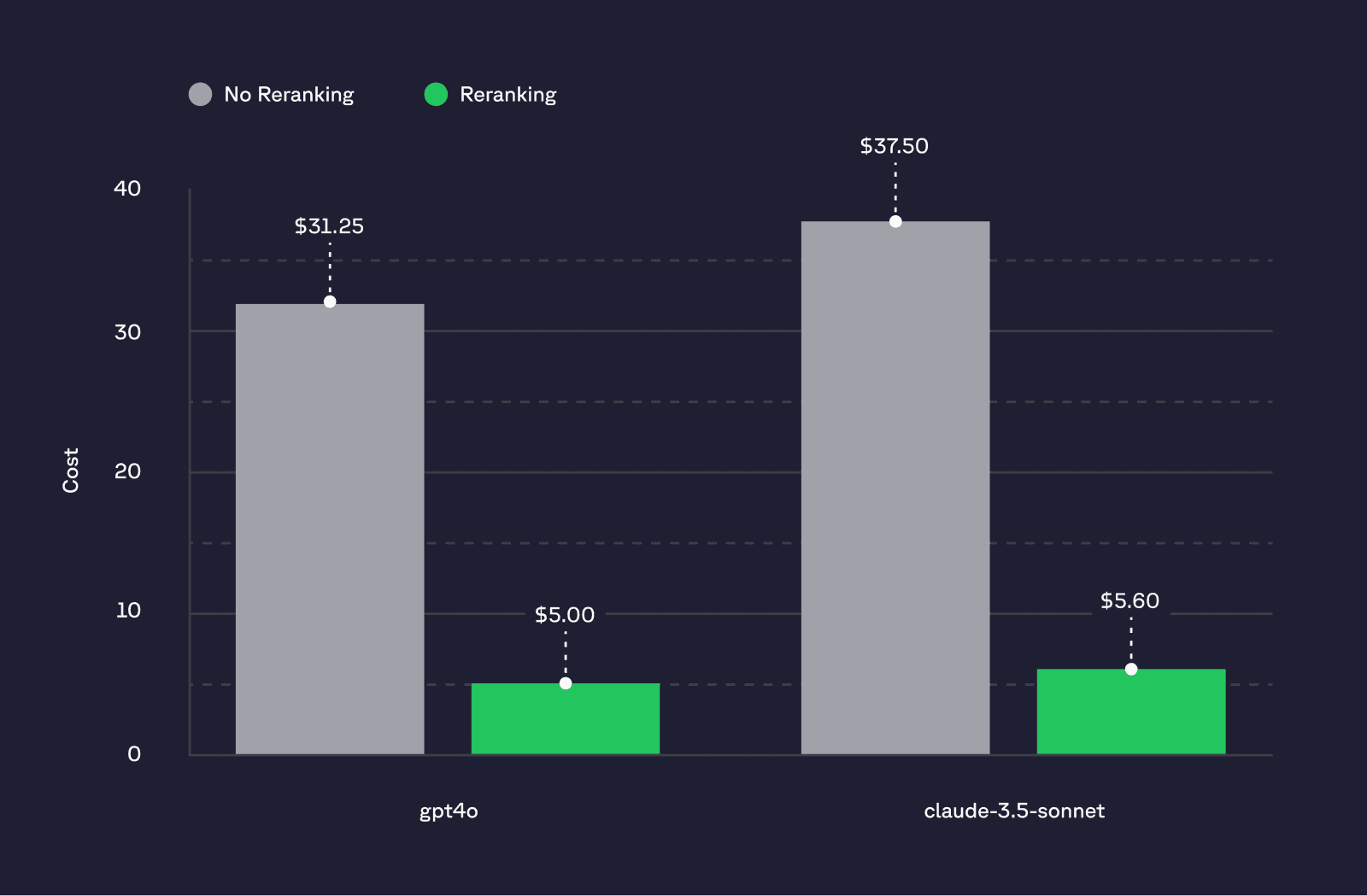
*Input cost for 1K searches assuming 50 documents with 250 tokens vs 5 documents with 250 tokens each.
Simplify your stack
Building AI has been more complex than necessary, requiring developers to maintain integrations and share sensitive data with numerous platforms. Pinecone Inference allows you to access state-of-the-art models for embedding and reranking alongside our vector database in a single integrated experience. No more juggling multiple tools and navigating different infrastructure bills. Use your time to build, improve, and ship knowledgeable AI apps.

How to get started
Today, reranking is available in API and in the Python SDK
pip install -U pineconeThe following code snippet demonstrates reranking a small set of docs.
from pinecone import Pinecone
pc = Pinecone("PINECONE-API-KEY")
query = "Tell me about Apple's products"
results = pc.inference.rerank(
model="bge-reranker-v2-m3",
query=query,
documents=[
"Apple is a popular fruit known for its sweetness and crisp texture.",
"Apple is known for its innovative products like the iPhone.",
"Many people enjoy eating apples as a healthy snack.",
"Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces.",
"An apple a day keeps the doctor away, as the saying goes.",
],
top_n=3,
return_documents=True,
)
print(query)
for r in results.data:
print(r.score, r.document.text)Try Reranking for free this month
Reranking with Pinecone Inference is now available in public preview for all users for free until August 31st. From September 1st, 2024, users pay $0.002 per request to bge-reranker-v2-m3.
Check out our guide and Colab notebook and start building more accurate AI applications with Reranking today.
Reference:
[1] N. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, P. Liang, Lost in the Middle: How Language Models Use Long Contexts (2023)
Was this article helpful?