Optimizing Pinecone for agents (and more)
Over the past year, demand for large-scale agentic workloads surged significantly. We observed these workloads, gained insights into their needs, and evolved our serverless architecture accordingly.
This post describes what we mean by agentic workloads, their patterns, and how our new system optimizes for them. We also describe how we improved performance for our search and recommendation systems workloads.
Starting this week, new users on Pinecone will run on our most advanced architecture. We will update the community as we roll this out to everyone. Companies with large-scale workloads who need access to the new architecture today are encouraged to reach out to us.
The rise of agentic workloads
As discussed by our CTO, Ram Sriharsha, in our recent blog post, we’ve observed a significant increase in agentic workloads across our customer base. These workloads differ fundamentally from traditional use cases, such as semantic search, in both their data structure and access patterns.
Unlike Search and Recommendation systems, agentic workloads typically involve:
- Millions of namespaces. Each can correspond to an individual user, a set of meetings or conversations, documents in a single folder, emails in one inbox, etc.
- Small namespace sizes. Typically, these namespaces are quite small, with fewer than 100k vectors in a namespace being quite common.
- Sporadic and bursty query patterns. Each individual namespace might not be accessed at all for hours, days, or months. And then, it might be queried ten or a hundred times in quick succession.
The technical challenge of agentic workloads
Supporting agentic workloads effectively in a vector database presents a unique set of technical challenges that require us to meaningfully evolve our architecture.
Millions of namespaces: With potentially millions of namespaces to manage, the system can afford very little overhead per namespace. This applies to both space efficiency, where manifests, queues, file handling, and other metadata must be extremely lightweight, and compute efficiency, where indexing must scale effectively across many small collections without excessive resource consumption.
Storage/compute disparity: Agentic workloads also create a vast disparity between storage and compute needs. While the aggregate storage requirements across all namespaces can be enormous, the compute needs for any single namespace at a given moment are relatively minimal since most namespaces are small and infrequently accessed.
At the same time, these workloads also offer some simplifications that we could leverage in our design.
Small collections: Since each namespace typically holds no more than 100k vectors (and usually many fewer), they don't require elaborate indexing structures that might be necessary for larger datasets. This can save on indexing compute time. Additionally, the system can fetch and cache small amounts of data from blob storage in real-time, providing more flexibility in storage allocation and a significant reduction in costs.
Architectural innovations
To effectively support these demanding workloads, we implemented several key architectural changes to Pinecone.
Write path changes
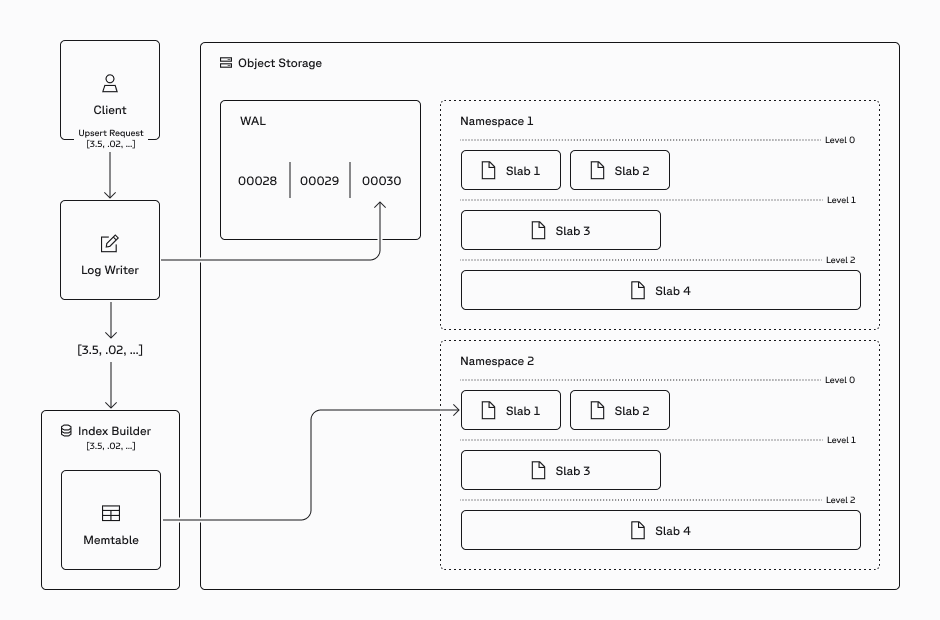
We completely redesigned our write path with an adaptive indexing approach based on log-structured merge trees. This approach allows us to handle both small, numerous collections and larger, more demanding workloads with appropriate optimizations for each.
For small slabs (i.e., small vectorsets), which are common in agentic workloads, we prioritize writing quickly with minimal overhead. This means virtually no compute is spent on complex indexing, and we maintain minimal storage overhead for index data structures. We employ fast indexing techniques like scalar quantization or random projections that provide good performance with minimal resource requirements.
As collections grow, larger slabs receive more elaborate indexing during compaction. When a set of slabs reaches a size threshold, it is merged into larger ones. During this process, we build more computationally intensive partition-based indexes that provide better performance at scale. This approach allows us to amortize indexing costs throughout the lifetime of serving these slabs, providing an optimal balance of performance and resource utilization.
By applying the right indexing strategy at the right scale, this adaptive approach efficiently delivers excellent performance across diverse workloads without requiring manual tuning or configuration.
Query path changes
We've also reimagined our query path to efficiently handle millions of namespaces without sacrificing performance or cost-effectiveness.
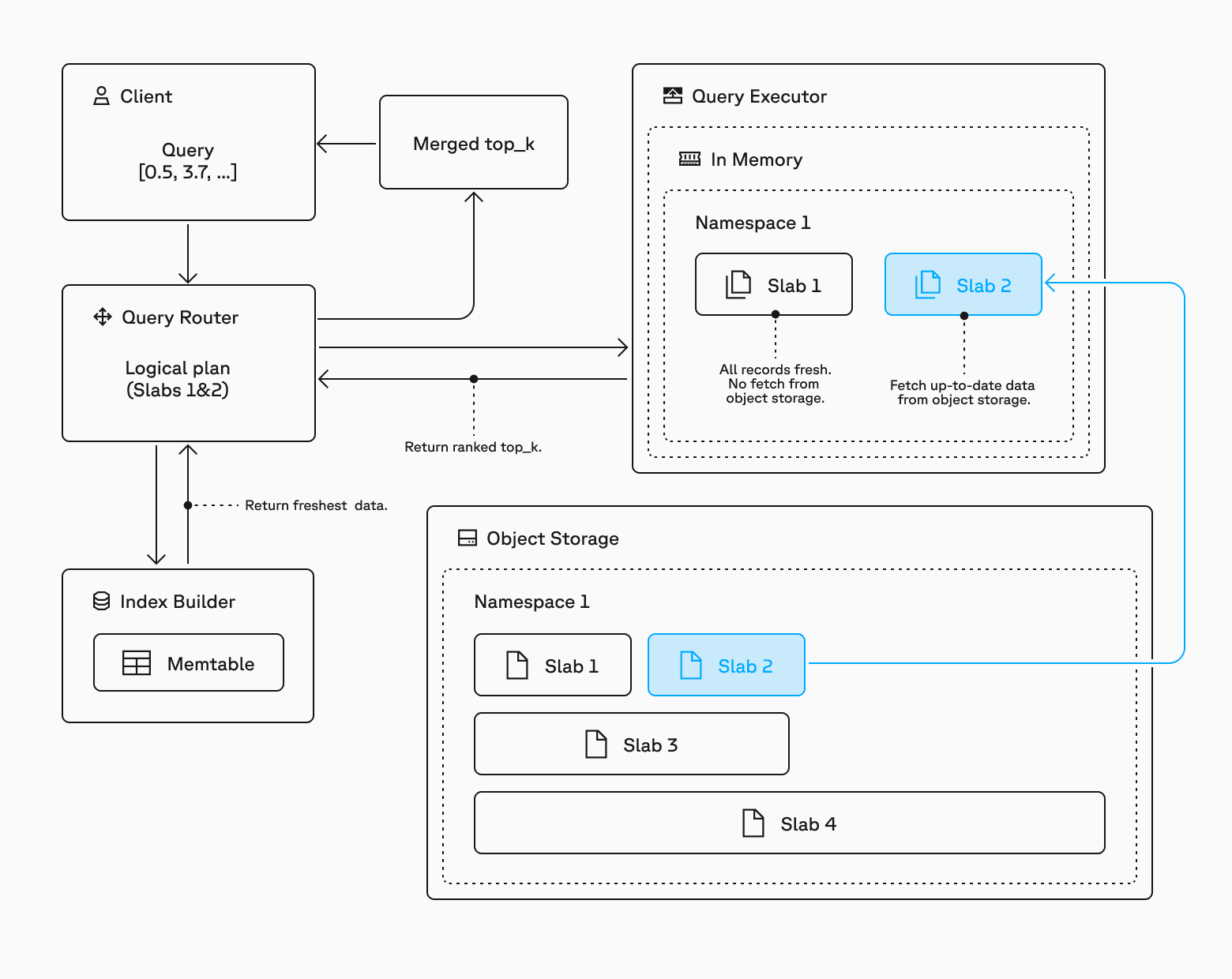
We completely persist data on blob storage for small namespaces, which represent the majority of agentic workloads. When a query arrives, relevant data is fetched and cached on-demand. This approach effectively decouples the amount of compute and SSD needed from the total data size, solving storage limitations for massive multi-tenant systems. Note that once the slab is cached, all subsequent queries are much faster because they don’t need to be fetched from blob storage.
Larger indexes take a hybrid approach where only index structures persist on SSD and RAM caches, with range queries to blob storage fetching raw data when needed. This balances performance requirements with cost constraints.
Our system also implements adaptive caching that automatically optimizes for different access patterns. Active namespaces are persisted higher in the storage stack, providing low latency for bursty query patterns. For small namespaces, fast linear scans deliver response times of approximately 10ms, ensuring an excellent user experience.
Improving search workloads too
Beyond agentic systems, we've also significantly enhanced our architecture for traditional search workloads with demanding requirements. These workloads often involve billions of vectors in a single namespace, require consistently low tail latencies, need support for complex and selective filtering, and increasingly demand lexical search capabilities alongside semantic search.
Enhanced metadata filtering
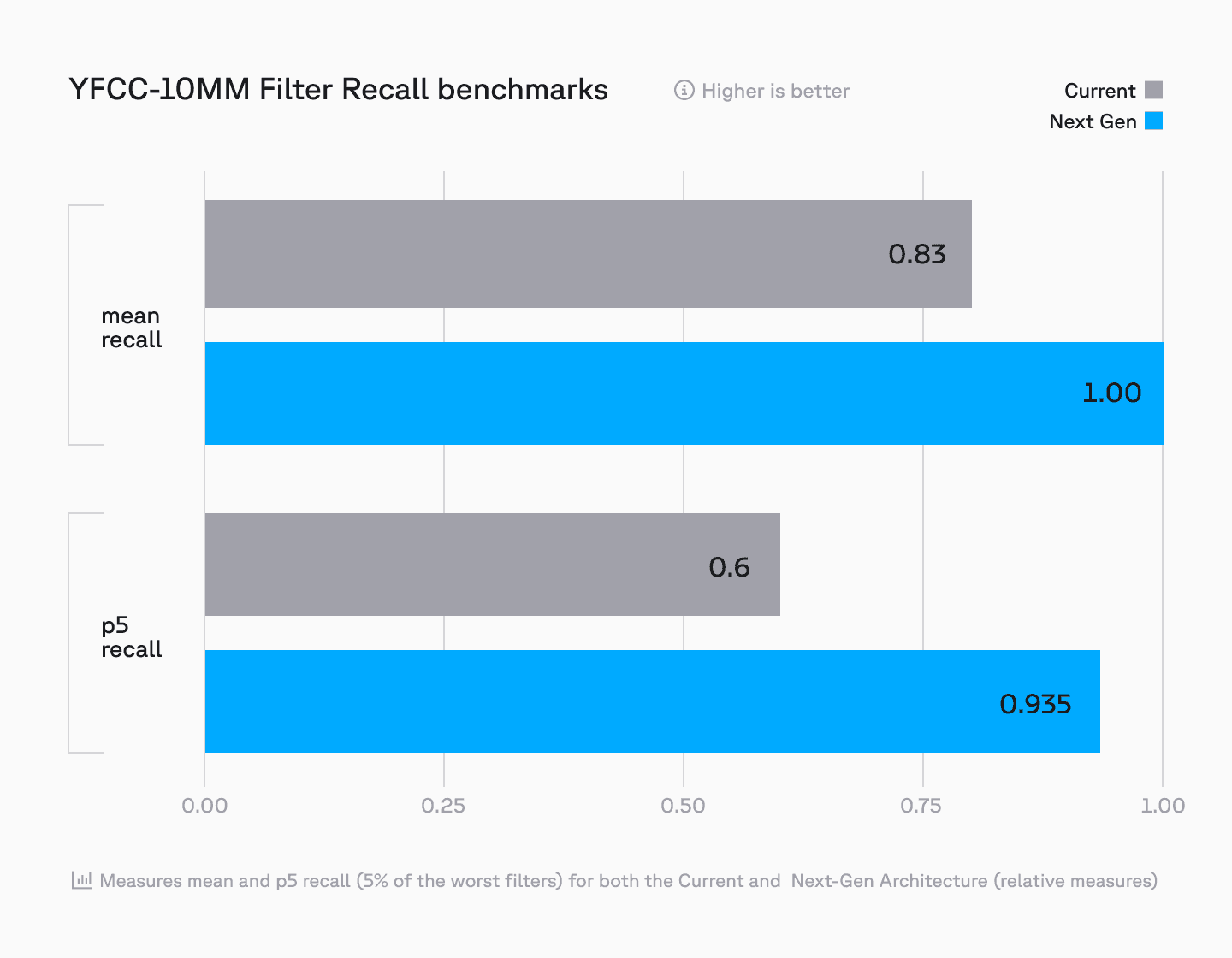
Metadata filtering is commonly used alongside vector search. It improves relevance by specifying which records to include or exclude from the search. Pinecone’s new disk-based metadata filtering allows for scaling metadata filtering while reducing the overall memory footprint. In addition to reducing memory usage, disk-based metadata filters enable high cardinality filters to be applied efficiently, improving recall.
High-performance sparse indexing for keyword search
We've introduced high-performance sparse-only indexes specifically optimized for keyword and lexical search use cases. These sparse indexes efficiently represent text data and complement semantic search powered by dense vectors.
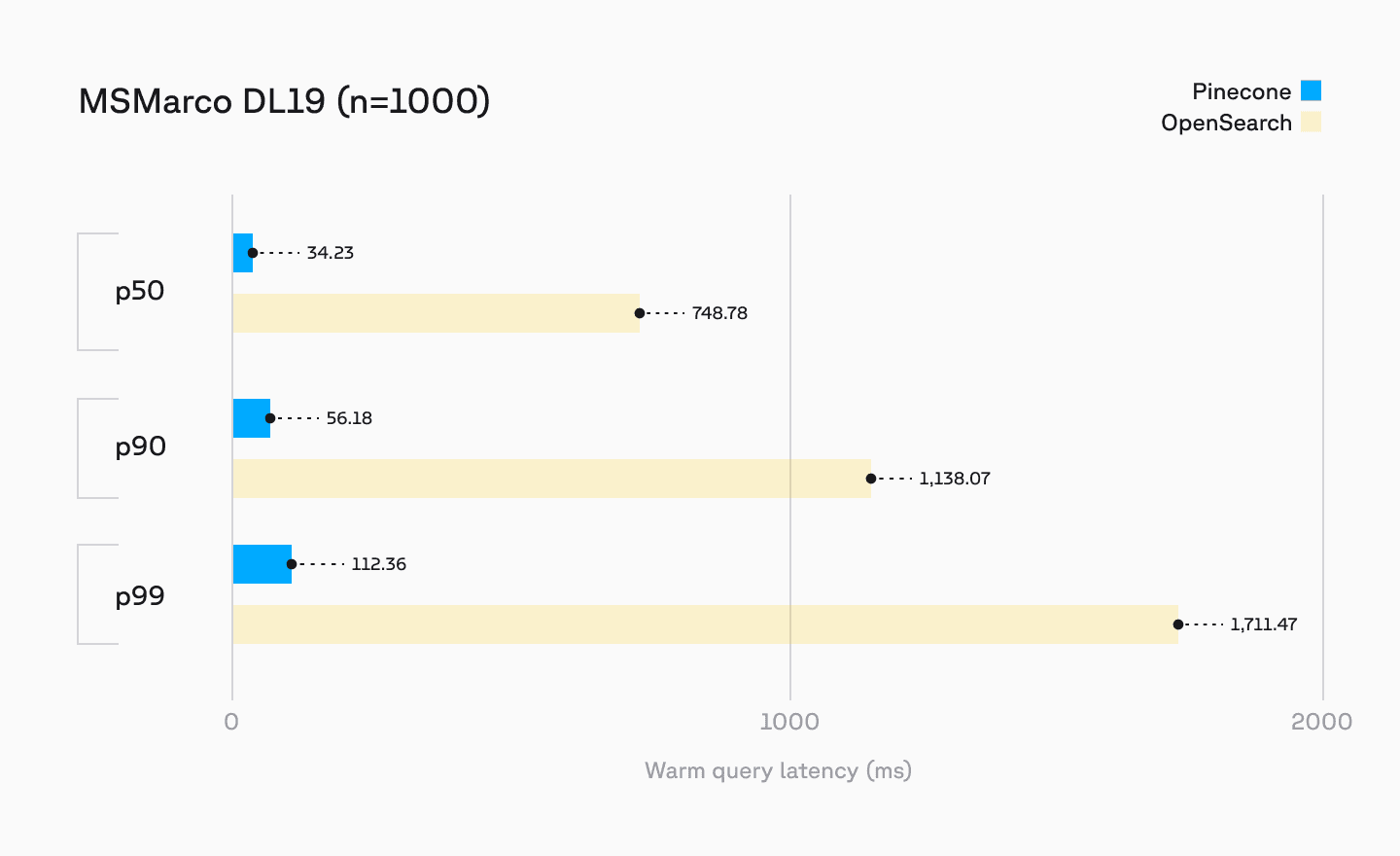
Pinecone's performance for sparse search outperforms existing search systems such as OpenSearch. Using sparse embeddings produced by the pinecone-sparse-english-v0 model for the MS Marco DL19 dataset of 8.9M vectors, we performed the following benchmarks on an OpenSearch cluster running a single r7g.large.search node. We compared these to the newly available Pinecone sparse vector index type running on similar hardware.
Improved support for recommender systems
Finally, we've optimized our architecture to handle the unique demands of high-throughput recommender system workloads. These systems typically require processing thousands of queries per second across medium-sized namespaces (often containing tens of millions of vectors) while maintaining consistently low latency at scale.
Our solution implements automatic replication at high QPS without requiring manual index management. Soon, we'll introduce provisioned capacity options for even more predictable performance. We've also optimized our underlying algorithms, including IVF and Fast Scan implementations, to deliver exceptional throughput for these demanding workloads.
Pinecone serverless provides low latency even when operating at scales over 100M vectors, at query levels exceeding 1000 QPS. We benchmarked on a real-world use case – recommendations based on user-generated reviews at a 100m record scale. Here we compared Pinecone serverless against an OpenSearch cluster comprised of 6 r5.12xlarge nodes, with 48 vCPU and 384 GB of memory per node. This cluster translates to roughly twice the size of the Pinecone instance, with Pinecone serverless still showing better performance on an absolute scale.
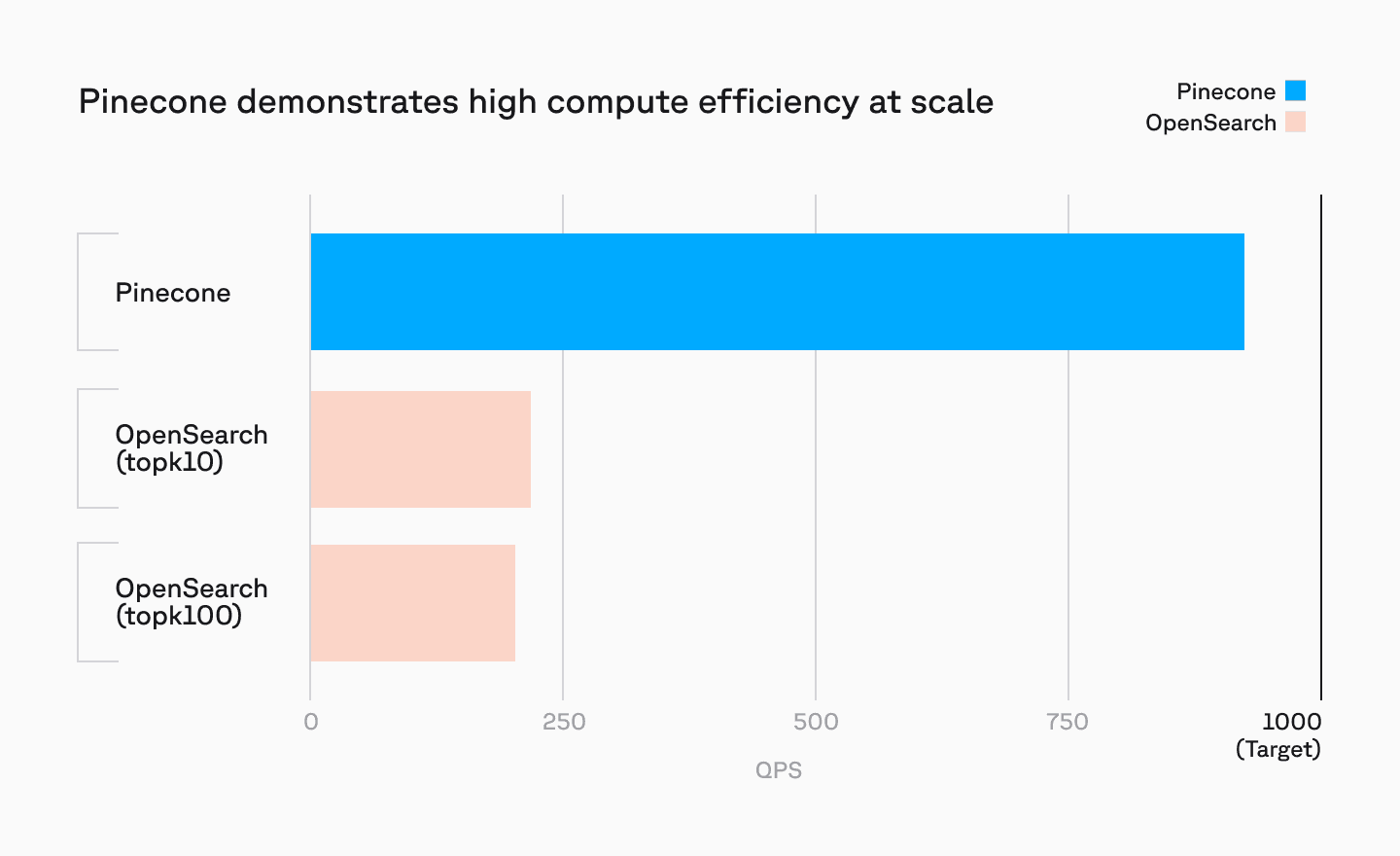
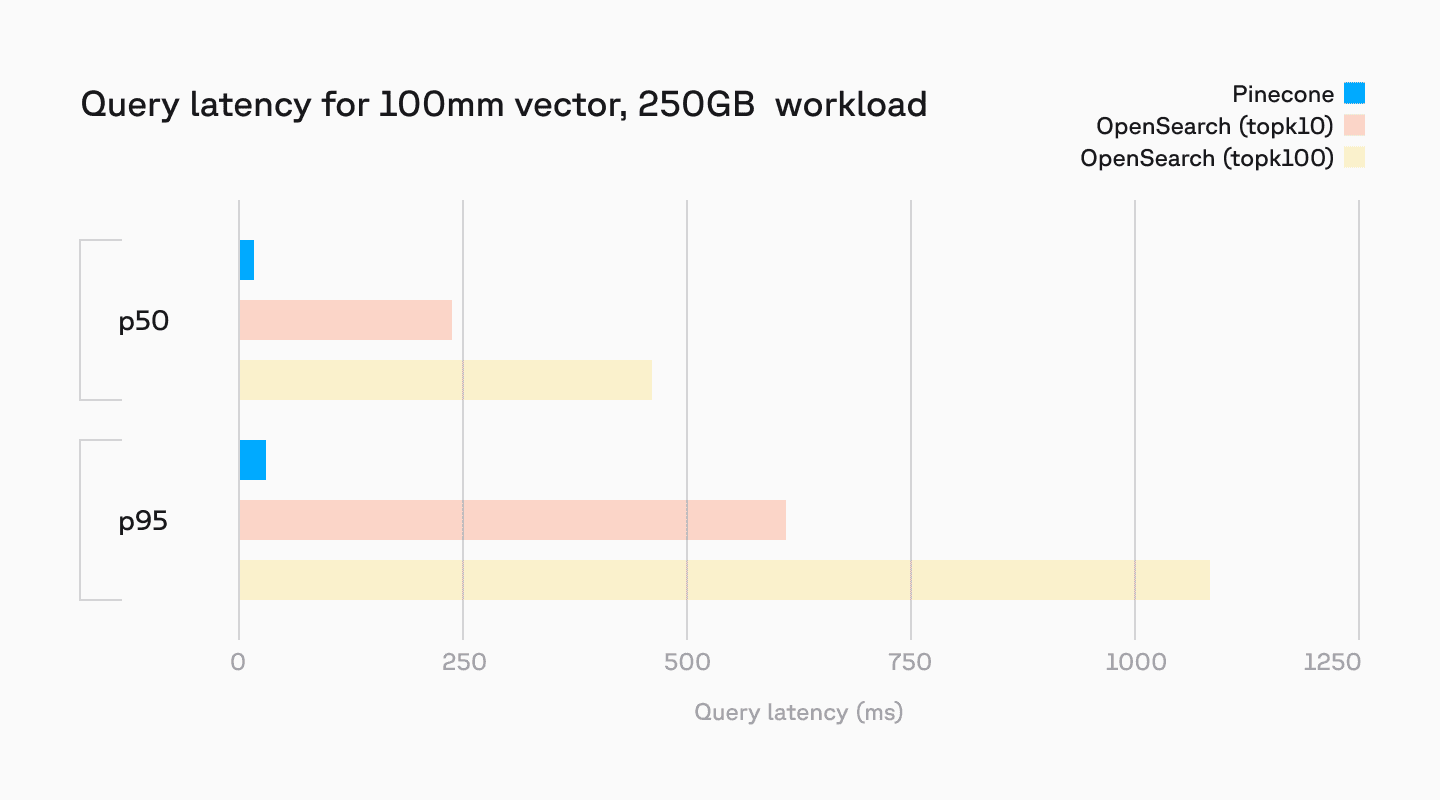
Achieving similar scale and performance as Pinecone serverless would require OpenSearch clusters scaled 10x to 100x. Pinecone handles this natively at scales from thousands to billions of vectors.
Start building today
Our latest serverless architecture is rolling out this week to new users and to existing users over the next month.
In the coming months, we'll introduce additional capabilities including delete by metadata operations, expanded provisioned read capacity options, and increased namespace limits. Please contact us if you’re interested in early access to these features.
Was this article helpful?