Retrieval Inference for scale and performance
Accurate retrieval involves multiple steps, including embedding generation, vector search, and reranking. Each step involves trade-offs among accuracy, efficiency, and complexity. At Pinecone, we're building an inference system to run state of the art models to match the capabilities of the vector database. This post explores how our optimized embedding and reranking inference uniquely enhances retrieval quality, simplifies the developer experience, and reduces the operational footprint of modern retrieval applications.
Understanding Retrieval Inference
Retrieval inference operates differently from traditional LLM inference. While LLMs primarily generate text from prompts, retrieval inference focuses on the needs of transforming data for embedding and reranking.
Embedding Generation
Embedding models convert data into numerical vectors that capture semantic meaning. In production environments, these models typically handle two distinct workloads:
- Document Processing: Converting your content library into vectors for indexing. This typically involves processing longer text segments (200-600 tokens) and can be done as a batch operation.
- Query Processing: Transforming user queries into the same vector space in real-time. These are usually shorter (around 20 tokens) but require consistent, low-latency responses.
Reranking
Reranking refines search quality by taking a closer look at initial results. After vector search identifies potential matches, reranking models examine each query-document pair together, considering contextual relationships that vector similarity alone might miss. This deeper analysis improves result accuracy, though it requires additional computation time. Effective retrieval systems carefully consider this trade-off between relevance and performance.
When embedding generation and reranking are viewed as components of a unified retrieval inference system, opportunities emerge for optimizations that might otherwise be overlooked when these processes are managed separately.
How Pinecone optimizes Retrieval Inference
Pinecone optimizes retrieval inference by carefully tuning models, hardware, and serving infrastructure to handle distinct workloads effectively.
Model optimization with NVIDIA TensorRT
To optimize model performance, Pinecone develops specialized inference profiles tailored to embedding and reranking workloads. These profiles consider the specific architecture, size, and performance objectives of each model. We leverage NVIDIA TensorRT to enhance performance through techniques like
- Kernel Tuning: Selecting optimal CUDA kernels based on hardware and tensor shapes.
- Layer Fusion: Merging consecutive operations (e.g., matrix multiplications with activation functions)
- Dynamic Tensor Optimization: Adjusting computation dynamically based on input length to minimize unnecessary padding.
- Precision Reduction: Reducing numerical precision (e.g., from FP32 to FP16 or INT8) to enhance performance with minimal impact on accuracy.
Hardware selection significantly impacts performance. For each model we test multiple GPU configurations (e.g., NVIDIA T4, L4, A10, L40s) to identify optimal combinations of cost and performance. By decoupling query and passage workloads, we can independently select hardware that best suits each workload, resulting in notable improvements in both latency and throughput compared to baseline models.
The impact of these optimizations is demonstrated by our results with the bge-reranker-v2-m3 model. Reducing precision from FP32 to FP16 nearly doubled throughput, and converting from FP16 ONNX to a TensorRT-optimized engine delivered an additional 60% improvement. Combined, these steps increased throughput by almost 3X compared to the original FP32 baseline.
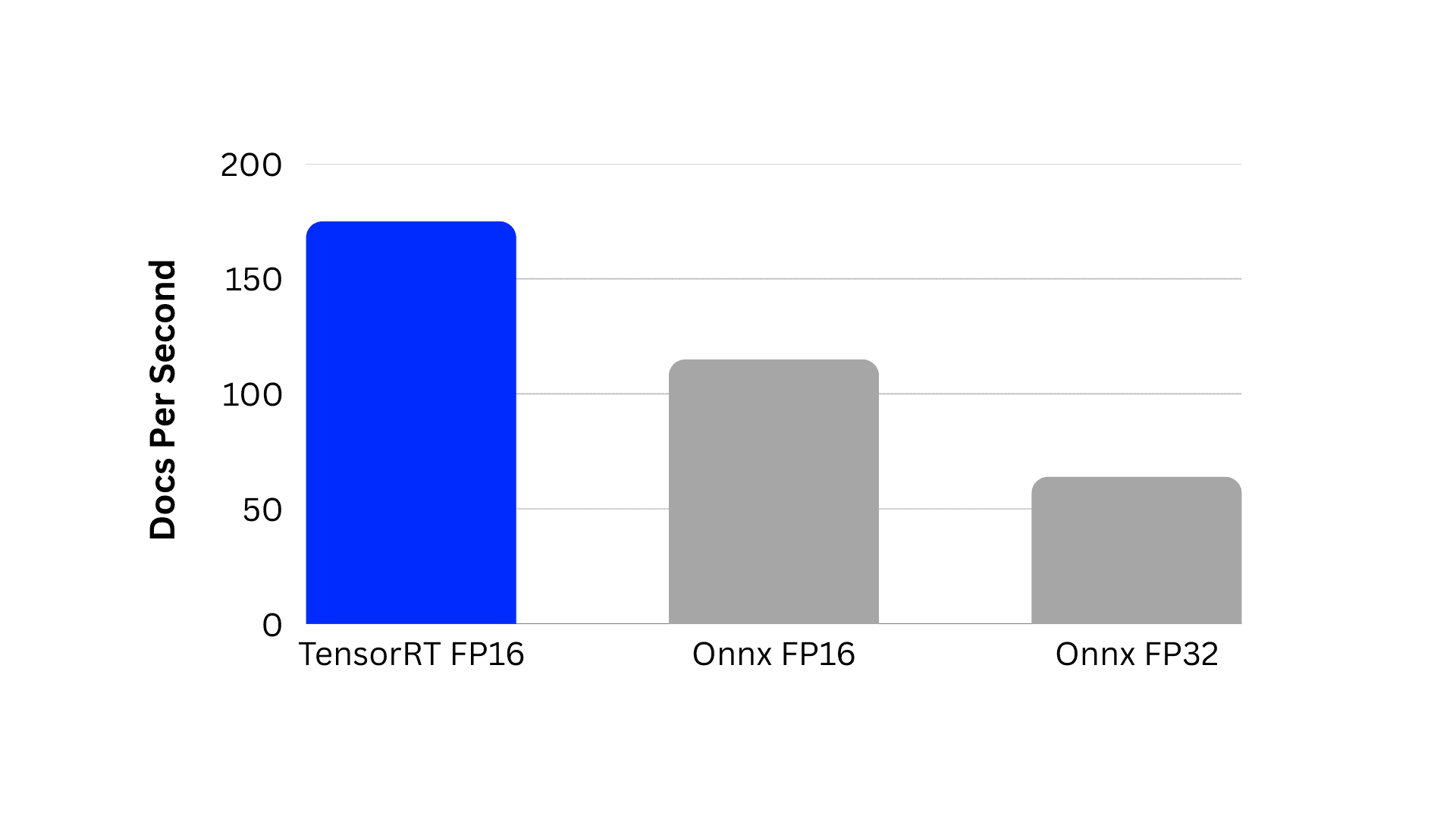
Maximizing GPU utilization with Triton dynamic batching
Once models are optimized, we deploy them using NVIDIA Triton Inference Server on Kubernetes. Triton's dynamic batching significantly enhances GPU utilization by efficiently consolidating numerous smaller inference requests into larger, more resource-effective batches.
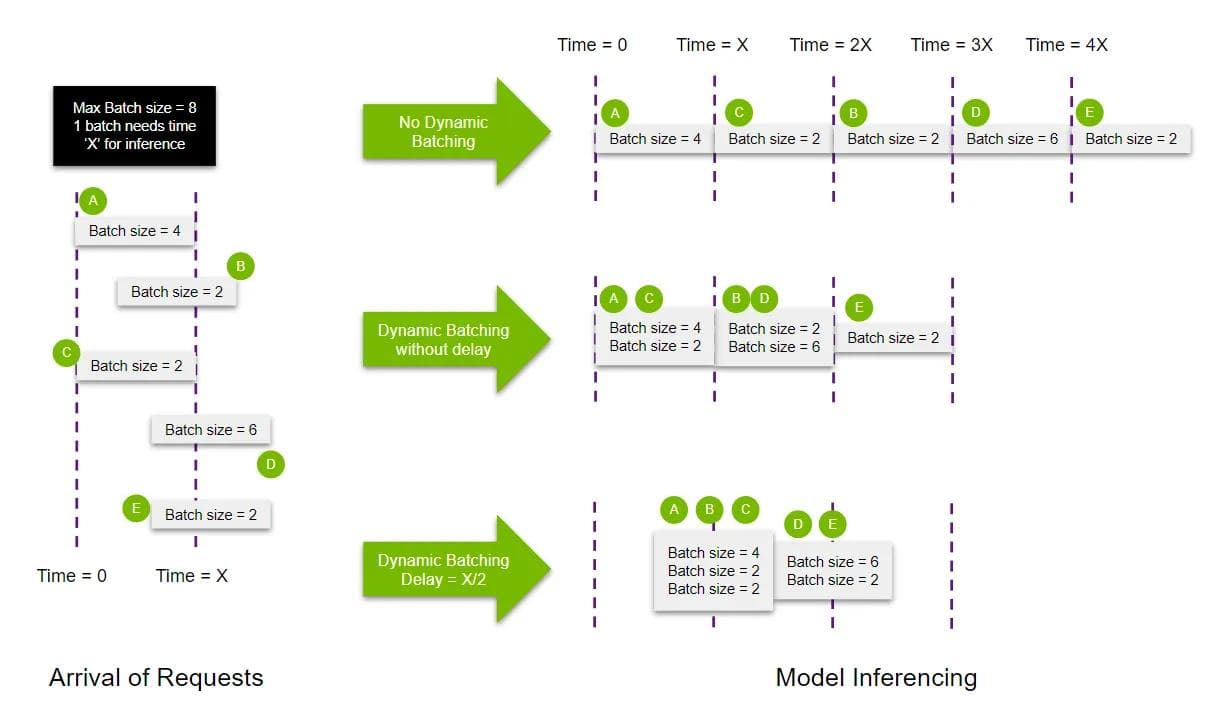
Dynamic batching collects incoming requests during a short configurable delay period, then processes them together once either the batch reaches its maximum configured size or the delay expires. This approach reduces inference overhead and maximizes GPU utilization, particularly beneficial in Pinecone’s multi-tenant environment, where customer workloads can vary significantly in batch size and frequency.
The configuration is customized for each model and workload type. For example, multilingual-e5-large has the following configurations:
| Query Model | Passage Model | |
|---|---|---|
| Target Batch Size | <16 | 96 |
| Delay Window | 10ms | 30ms |
The query model uses a shorter delay window to minimize latency for fast, real-time responses, while the passage model employs longer delay windows to accommodate larger batch sizes and maximize throughput for high-volume requests.
Scaling with dedicated query and passage infrastructure
Pinecone deploys separate inference servers for query and passage workloads across most embedding models. This separation ensures real-time query requests—which require consistently low latency—are never delayed by resource-intensive batch passage embedding operations optimized for throughput. By isolating these workloads, each infrastructure path can scale independently, minimizing resource contention and maintaining predictable performance.
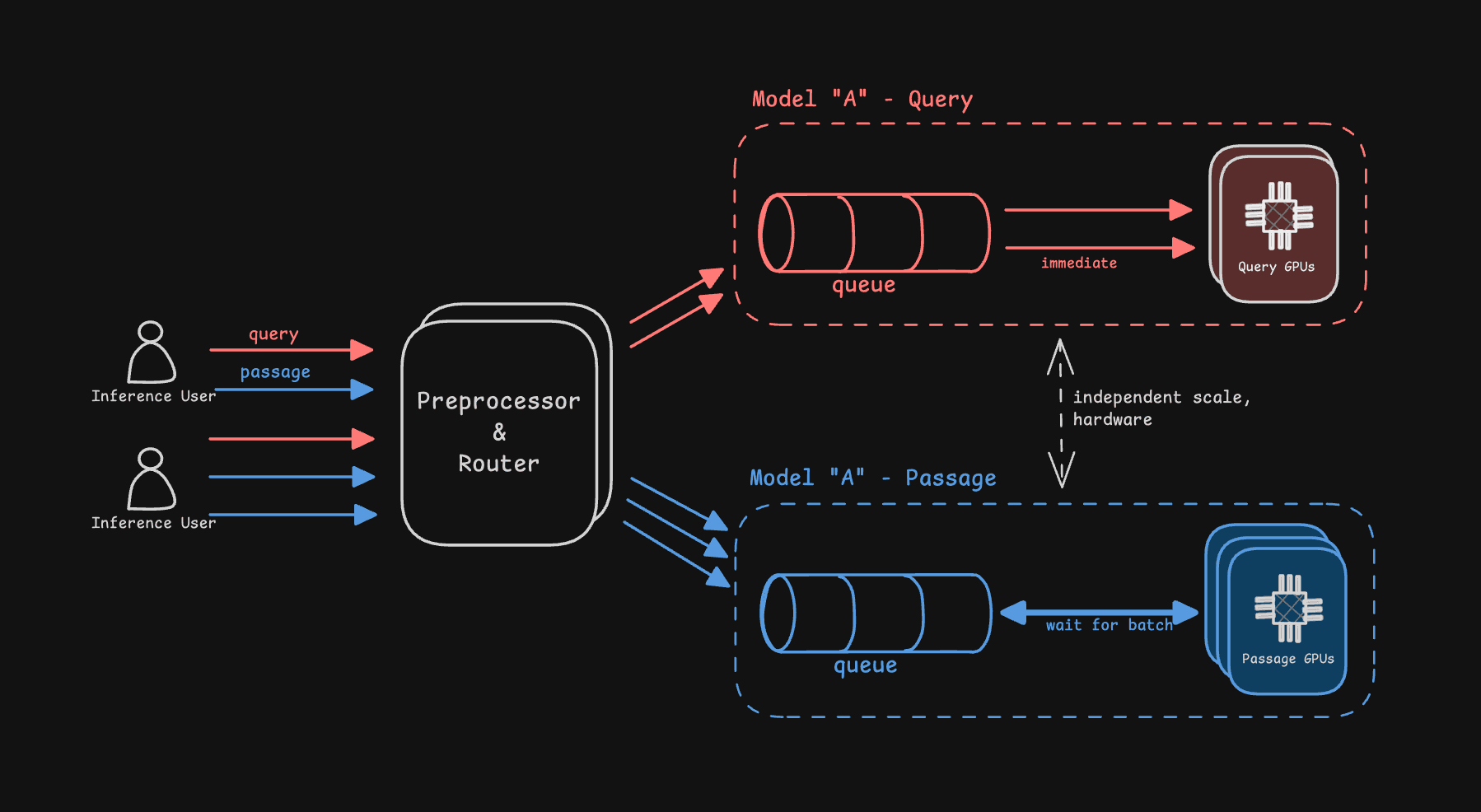
Inference requests are automatically routed to the appropriate infrastructure based on user-defined parameters, including the input_type, number of input sequences, and token length. For instance, a real-time query request configured as follows would be processed on the optimized query infrastructure:
POST https://api.pinecone.io/embed
{
"model": "llama-text-embed-v2",
"parameters": {"input_type": "query"},
"inputs": [
{"text": "What is the tastiest apple?"}
]
}This dedicated approach enables precise performance tuning—passage processing optimized for maximum throughput and query processing optimized for minimal latency—ensuring efficient resource allocation tailored to each workload.
We can observe the query and passage path separation by comparing the latencies of query requests to those of passage requests under load. This test simulates a large passage embedding job being started while the system is serving 80 queries per second (QPS) in a constant time of <~150ms (measured at client). For simplicity, this test was performed on a single pair of GPUs (1 query, 1 passage) with scaling disabled.
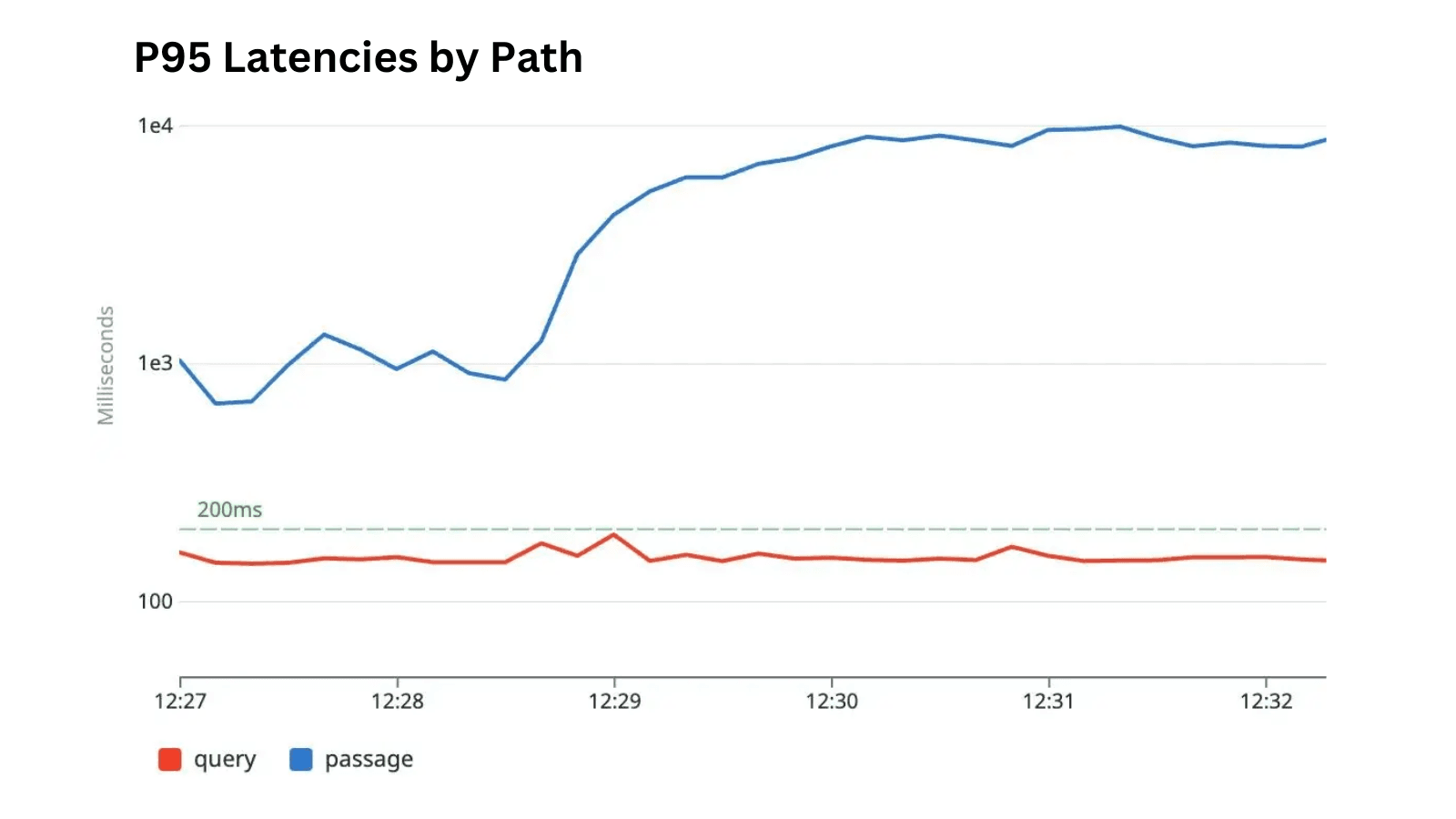
Importantly, as passage request latencies rise—reflecting the queueing of those additional requests—query path latencies remain steady.
Eliminating complexity with integrated inference
Building Retrieval-Augmented Generation (RAG) and agent-based applications traditionally requires multiple distinct inference and database operations across different service providers. This distributed approach often needs five or more separate API calls per query, introducing integration overhead, increased latency from network calls, and potential security concerns from data movement between services.
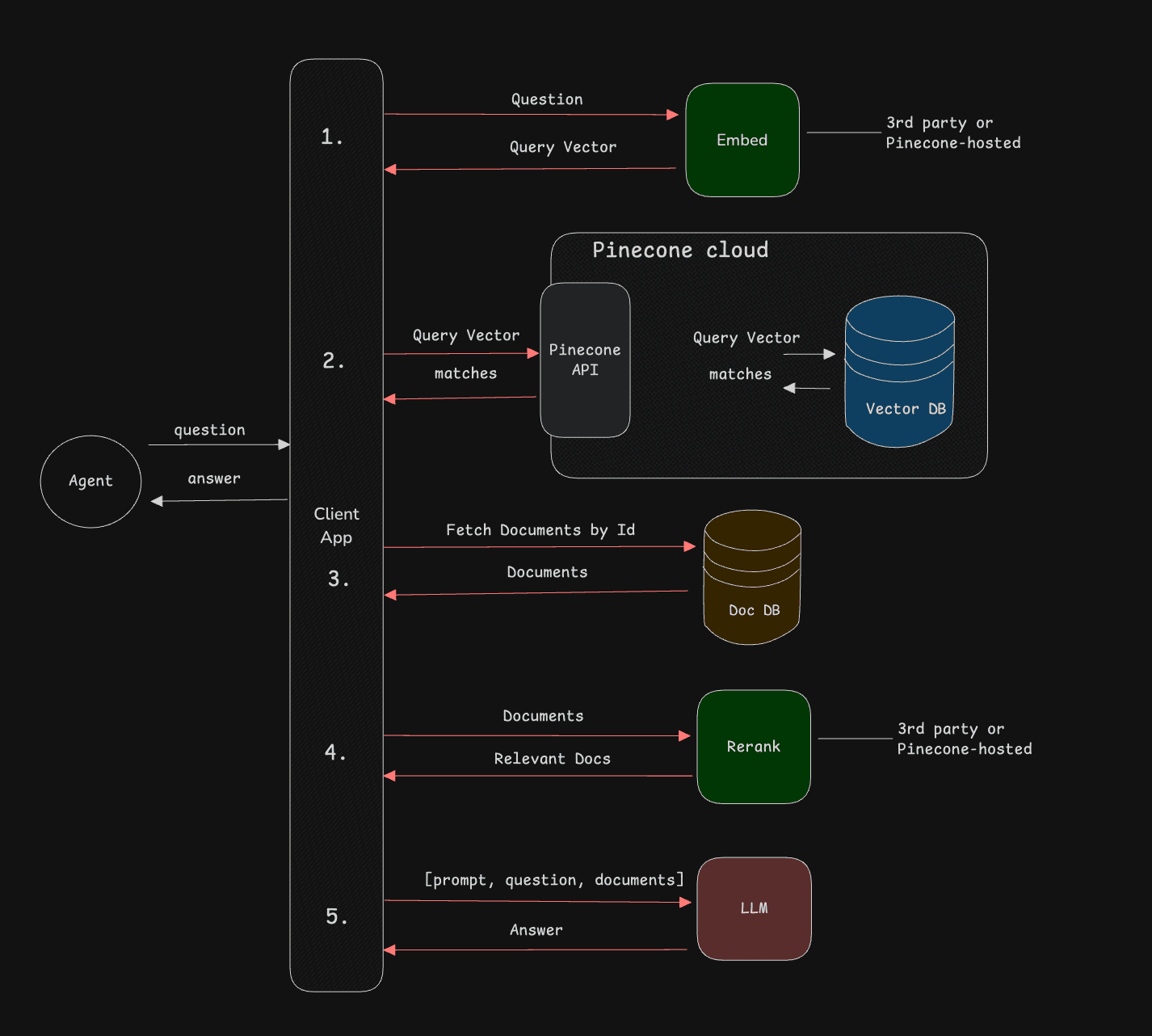
Pinecone’s integrated inference simplifies retrieval application development by consolidating embedding generation, vector search, and reranking into fewer, streamlined API calls. With direct support for state-of-the-art models like llama-text-embed-v2 and cohere-rerank-3.5, developers can achieve advanced retrieval quality without relying on external inference providers. This integration significantly reduces complexity, allowing developers to build high-performing RAG and agent-based applications efficiently using their own data.
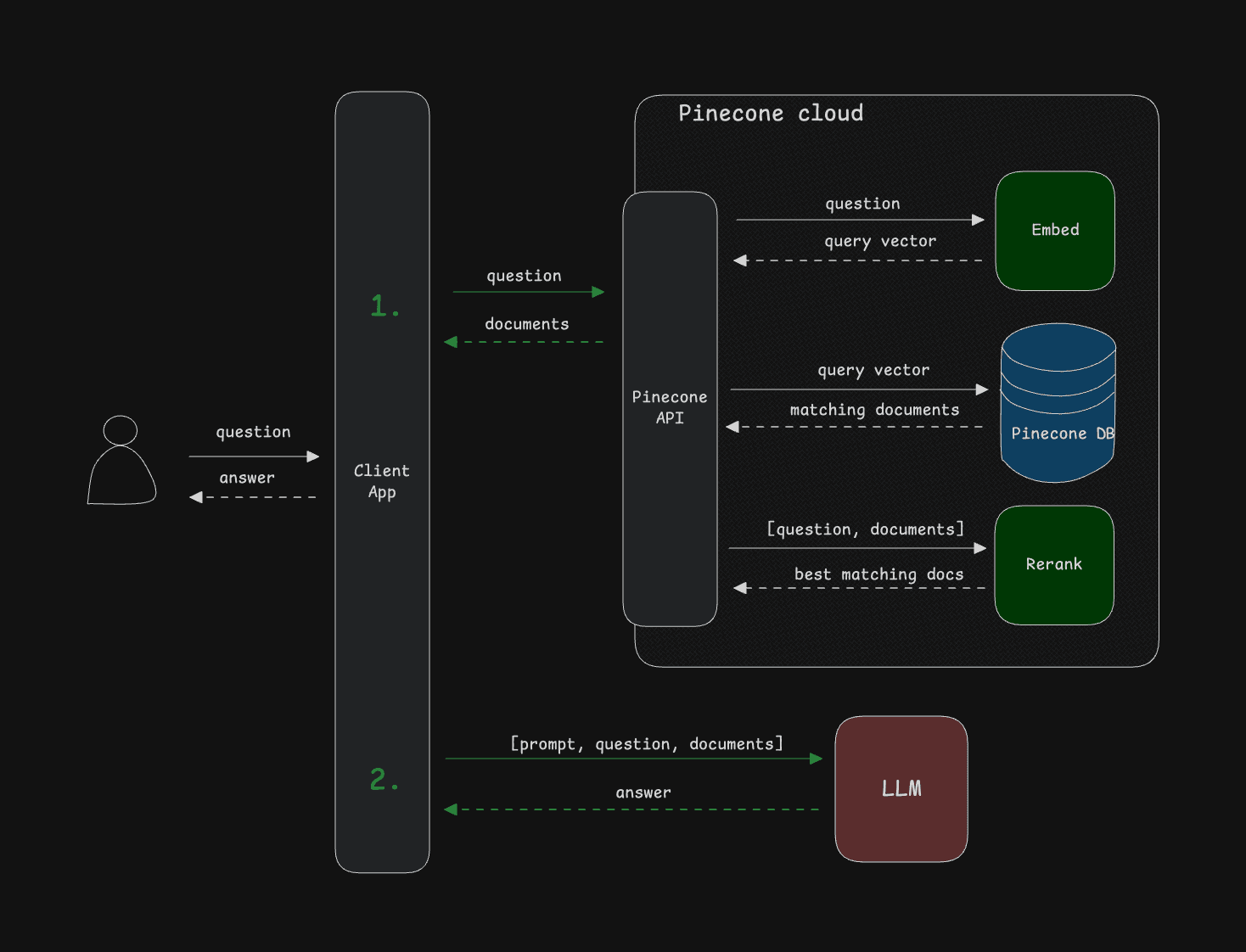
What’s in store
Performance will remain our top priority as we pursue our mission to deliver high-quality, accurate, and fast retrieval. We will deepen our investment in integrated inference by incorporating more advanced retrieval workflows, including Cascading Retrieval, bulk embedding, and expanded support for additional modalities like images.
We'll have lots more to share about all the things we’ve been working on during our upcoming Launch Week, March 17-21. Stay tuned!
Was this article helpful?