Simplify, enhance, and evaluate RAG development with Pinecone Assistant, now in public preview
Pinecone Assistant, an API service that securely generates accurate, grounded insights from your proprietary data, is now available in public preview. Since announcing beta earlier this year, thousands of developers have created RAG-based assistants across a broad set of use cases (e.g., financial analysis, legal discovery, and e-commerce assistants). Today we’re excited to open the feature to all users with public preview.
In this release, we’re introducing new features like expanded LLM support; an Evaluation API for benchmarking correctness and completeness; the ability to associate and filter files by metadata; and a new console UI.
A simpler way to get the answers you want
Developers still struggle to build AI assistants that can accurately answer questions about private data. Publicly available models are unaware of this data, and providing it through approaches like Retrieval Augmented Generation (RAG) requires AI expertise and valuable engineering time.
Pinecone Assistant is focused on delivering high-quality, dependable answers over private data while abstracting away the many systems and steps required to build RAG-powered applications (e.g., chunking, embedding, file storage, query planning, vector search, model orchestration, reranking, and more). It does this through a simple API that enables you to add files (in .txt or .pdf format) and start building within minutes. Your uploaded files are encrypted and isolated and only used to help generate useful answers without training the model. You can easily and permanently remove data at any time, meaning you control what the assistant knows or forgets.
pip install --upgrade pinecone pinecone-plugin-assistantIf using the Python SDK, begin by upgrading the client and installing the pinecone-plugin-assistant package
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# Create an assistant
assistant = pc.assistant.create_assistant(
assistant_name="finance-assistant",
timeout=30 # Wait 30 seconds for assistant operation to complete.
)Easily create an Assistant and upload your files. You can download the file used in this example or run the below command.
wget -O annual-filings-10-k.pdf https://investors.coca-colacompany.com/filings-reports/annual-filings-10-k/content/0000021344-24-000009/0000021344-24-000009.pdf#Upload a file to the assistant
assistant.upload_file("./annual-filings-10-k.pdf")
# Once the upload succeeds, ask the assistant a question
from pinecone_plugins.assistant.models.chat import Message
msg = Message(content="What operating segments does Coke have?")
resp = assistant.chat_completions(messages=[msg])
print(resp.choices[0].message.content)Start chatting with your Assistant once your files are uploaded.
Backed by Pinecone serverless, purpose-built for fast, highly accurate vector search
Our research on RAG shows that you can dramatically improve the performance of LLMs on many tasks by leveraging a vector database like Pinecone Serverless that’s capable of efficiently storing and searching across billions of embeddings. Pinecone Assistant leverages Serverless to retrieve only the most relevant documents to formulate a coherent context, enabling the LLM to generate the most accurate results across domains. Our initial benchmarking efforts show that Pinecone Assistant performs better than other assistant APIs (e.g., OpenAI Assistants).
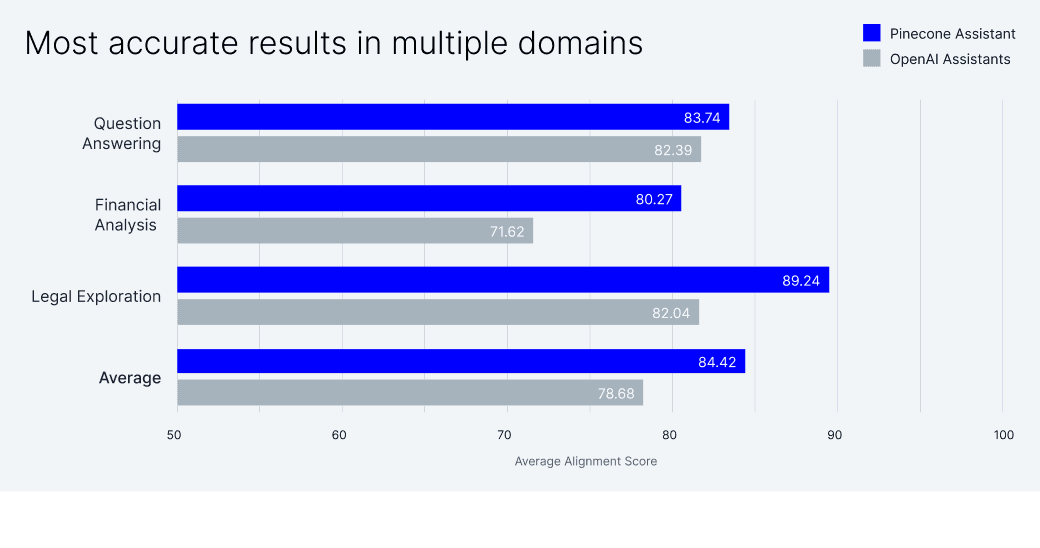
Evaluating AI assistants — especially for knowledge-intensive tasks over private data — remains a challenge for many developers for several reasons: 1) Not all components of a RAG pipeline have established benchmarks, 2) Generative AI outputs can vary significantly in style, structure, and content, making it hard to apply consistent evaluation metrics, and 3) Verifying the facts is difficult, as it often requires checking against a reliable source.
That’s why we developed a RAG benchmarking framework to measure how AI-generated answers align with ground-truth answers. Comparing the alignment of generated answers to ground-truth answers serves as a proxy for human preference, evaluating what the end user sees, rather than an intermediate output of the RAG system. This framework is now available for Pinecone Assistant to all Standard and Enterprise users via the Evaluation API.
What’s new with Pinecone Assistant:
- Built-in evaluation: You can now evaluate the query, generated answer, and ground truth through the Evaluation API. The Evaluation API measures correctness (i.e., did the generated answer hallucinate facts) and completeness (i.e., did the generated answer include all the relevant ground truth facts), which are combined into an overall “answer alignment score.” The Evaluation API makes it easier to assess your assistants' accuracy, benchmark performance against other RAG systems, and compare the results of different data or question choices for a given Pinecone Assistant task.
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
response = pc.assistant.evaluation.metrics.alignment(
question="What operating segments does Coke have?",
answer="Coca-Cola has operating segments of North America and Private Ventures and was founded in 1886",
ground_truth_answer="""Coca-Cola has operating segments of
Europe, Middle East and Africa,
Latin America,
North America,
Asia Pacific,
Global Ventures,
and Bottling Investments
""")The Evaluation API request has fields for the question, answer, and ground truth answer.
{
"metrics": {
"correctness": 0.5,
"completeness": 0.1667,
"alignment": 0.25
},
"reasoning": {
"evaluated_facts": [
{
"fact": {
"content": "Coca-Cola has an operating segment in Europe, Middle East and Africa."
},
"entailment": "neutral"
},
{
"fact": {
"content": "Coca-Cola has an operating segment in Latin America."
},
"entailment": "neutral"
},
{
"fact": {
"content": "Coca-Cola has an operating segment in North America."
},
"entailment": "entailed"
},
{
"fact": {
"content": "Coca-Cola has an operating segment in Asia Pacific."
},
"entailment": "neutral"
},
{
"fact": {
"content": "Coca-Cola has an operating segment in Global Ventures."
},
"entailment": "contradicted"
},
{
"fact": {
"content": "Coca-Cola has an operating segment in Bottling Investments."
},
"entailment": "neutral"
}
]
},
"usage": {
"prompt_tokens": 1359,
"completion_tokens": 122,
"total_tokens": 1481
}
}In the Evaluation API response, scores are calculated from 0 to 1 along with reasoning for the “answer alignment score"
- Expanded LLM support: Throughout beta, we leveraged Azure’s OpenAI service to run GPT-4o for query generation. With public preview, we now also support Anthropic’s Claude 3.5 Sonnet via Amazon Bedrock. To choose your LLM, simply update a parameter at query time. We’ll continue to add support for new LLMs over the coming months.
- Metadata filtering: Pinecone Assistant now supports metadata filters to easily limit your vector search to a particular user, group of users, or category. Simply attach metadata key-value pairs to vectors in your index, and then specify filter expressions on a per-file basis. Upon query, metadata filters will be used to retrieve exactly the number of nearest-neighbor results that match the filters.
# Upload a file with metadata
resp = assistant.upload_file(
file_path="./annual-filings-10-k.pdf",
metadata={"quarter": "Q4-2023"},
)
# List files with a filter
assistant.list_files(filter={"month": {"$eq": "october"}})
# Specifying a filter restricts the context it can use to only those files matching with matching metadata
msg = Message(content="What operating segments does Coke have?")
resp = assistant.chat_completions(
messages=[msg],
filter={"quarter": {"$eq": "Q4-2023"}}
)Pinecone Assistant is available to all users, start building today
Pinecone Assistant is now available in public preview to all users. Starter (free) plan users are limited to 1GB of file storage, 200K output tokens, and 1.5M input tokens. Standard and Enterprise users have access to an unlimited number of Assistants with $3/GB for monthly storage, $8 per 1M input tokens, $15 per 1M output tokens, and $0.20/day per Assistant. Learn more about pricing and public preview limitations for Assistants.
In the coming months, we plan to add additional LLMs, more control around the citations and references for generated responses, the ability to provide instructions to Assistants, and greater functionality for the Evaluation API. Learn more about Pinecone Assistant, try out the example application, and start building knowledgeable AI applications today.
Was this article helpful?