Rewriting a high performance vector database in Rust
I recently spoke at the Rust NYC meetup group about the Pinecone engineering team’s experience rewriting our vector database from Python and C++ to Rust. The event was very well attended (178+ registrations), which just goes to show the growing interest in Rust and its applications for real-world products. Below is a recap of what I discussed, but make sure to check out the full recording if interested in learning more.
Introduction to Pinecone - why are we here?
Data lakes, ML Ops, feature stores - these are all common buzzwords trying to solve similar sorts of problems. For example, let’s say you have a lot of unstructured data, and in order to gain insights you store it in blob storage. Historically, you would use an ML Ops platform, like a hosted Spark pipeline, for this. However, in many ways, we’re seeing the industry start to transition to the concept of vector databases and specifically approximate nearest neighbor (ANN) search to support similar use cases.
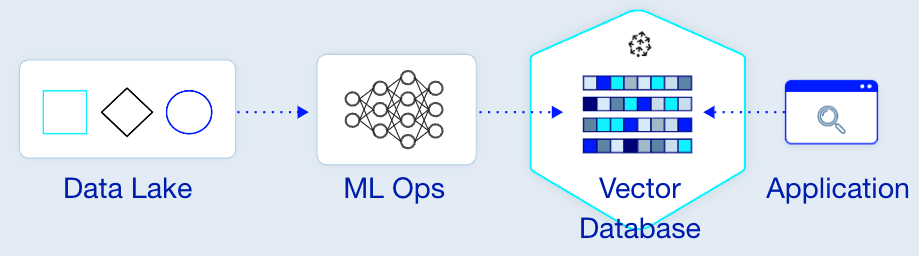
Pinecone is a fully managed, SaaS solution for this piece of the puzzle - the vector database. While the concept of the vector database has been used by many large tech companies for years, these sorts of companies have built their own proprietary, deep learning ANN indexing algorithms to serve news feeds, advertisements, and recommendations. These infrastructures and algorithms require intensive resources and overhead that most companies can’t support. With its strict memory management, efficient multi-threading, and fast, reliable performance, this is where the Pinecone solution comes in.
Ramping up with Rust
Pinecone was originally written in C++ with a connectivity wrapper written in Python. While this worked well for a while, we began to run into issues.
First of all, Python is a garbage collected language, which means it can be extremely slow for writing anything high performance at scale. In addition, it’s challenging to find developers with experience in both Python and C++. And so the idea of iterating on the database was born - we wanted to find some way to unify our code base while achieving the performance predictability we needed.
We looked at and compared several languages - Go, Java, C++, and Rust. We knew that C++ was harder to scale and maintain high quality as you build a dev team; that Java doesn’t provide the flexibility and systems programming language we needed; and that Go is also a garbage collected language. This left us with Rust. With Rust, the pros around performance, memory management, and ease of use outweighed the cons of it not yet being a very established language.
Identifying bottlenecks
Continuous benchmarking
As we began ramping up with Rust, we ran into a few bottlenecks. Before shipping the newly rewritten database, we wanted to ensure it continued to scale easily and have predictable performance. How did we test this? With continuous benchmarking.
Continuous benchmarking allowed us to see every commit broken down by the performance of a specific benchmark test. Through HTML reports, we are able to see the exact commit that caused the regression of the debt anytime a code change is merged.
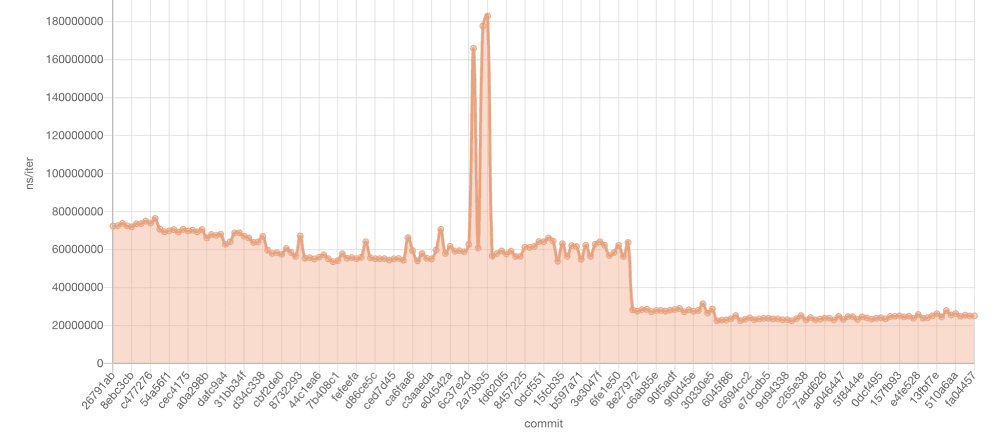
As you can see in the above graph, a commit was merged that caused a huge spike. However, with Criterion, an open source benchmarking tool, we were easily able to identify it, mitigate it, and push a fix. And over time, we lowered our latency and shipped improvements.
Building an observability layer
At this point, we’ve confirmed that the new database is performant, and have benchmarks to run it against. But what happens when you go to production, and things are slower than they should be? This is when you need an observability solution.
Adding an observability layer with Rust can be complicated without the support of a more mature developer community. As a result, we wanted a solution with minimal instrumentation, that’s easy to integrate, and is cloud agnostic. Our end goal was to provide a layer compatible with Datadog, Prometheus or any other metrics provider.
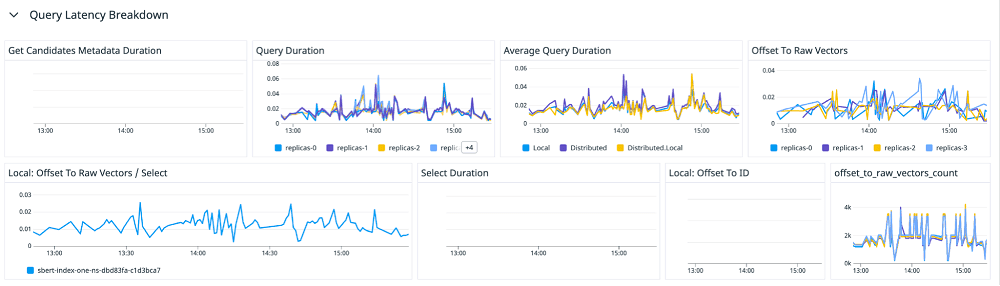
There are two main components to our observability layer - traces and aggregated metrics. With each of these signals, you can see how each part of the code is performing over time.
How did we achieve this? For metrics, we used some macros for histogram and counter metrics. We also used a custom Rust macro that hooks into OpenMetrics, and from there we can push metrics to Prometheus or Datadog. For tracing, we took a similar approach. We implemented an OpenTelemetry protocol that allows us to send traces to any observability solution. This way we’re able to see all of our metrics and trace requests as graphs in a single dashboard (see the below example).
Optimizing performance with Rust
After identifying and addressing the above bottlenecks, we were able to focus on optimizing performance. With Rust, there are several aspects around achieving high performance that we liked - low level optimized instruction sets, memory layout, and running async tasks.
Optimized instruction sets
One of the things we considered when choosing Rust was its access to low level optimized instruction sets, which are critical for optimizing the kind of vector based workloads that Pinecone utilizes. So for example, AVX-512 allows us to utilize parallel dot-product to compute high throughput dot-product queries on anything. And Rust gives us direct access to these compiler optimizations.
Memory layout
If you’re using a higher level language, you’re not going to have access to how the memory is laid out. A simple change, like removing indirection in our list, was an order of magnitude improvement in our latencies since there’s memory prefetching in the compiler and the CPU can anticipate which vectors are going to be loaded next in order to improve the memory footprint.
Running async tasks
Rust is async, and Tokio is the one of the most popular async providers. It’s performant, ergonomic, and has options for running on a single event loop. However, it’s not great for running CPU intensive workloads, like with Pinecone.
When it comes to running these tasks, there are many options. For example, because Tokio has different runtime modes, you can run it by itself in this async mode with multiple threads. And in that context, you can block on an individual thread in place, which is called ‘block_in_place’. You can also use ‘spawn_blocking’.
There are also “smart” work, parallel processing libraries, like Rayon, that maintain a thread pool and implement things like work stealing. And finally there’s the option of your own solution. If you want more control, you can use MPSC channels. While you have to write some custom code, they give you the fine grained ability to schedule work and ensure data locality.
What’s next for Pinecone?
We are continuing to optimize our codebase to ensure we’re maintaining a highly performant, stable, and fast database. This recap highlights the key points discussed during the meetup, but make sure to watch the full recording for more detail.
If you are interested in learning more about Pinecone and vector databases, check out the resources on our learn page or try it out (it’s free). Also, if you’re currently using or interested in working with Rust, we are hiring.




