Reimagining the vector database to enable knowledgeable AI
An entirely new AI “tech stack” has emerged in the past year. Large Language Models (LLMs) have emerged as the intelligence and orchestration layer for the stack. Yet for AI to be truly useful, LLMs need access to knowledge. Vector databases are at the core of how we provide knowledge to LLMs and the AI stack.
With Pinecone serverless, we set out to build the future of vector databases, and what we have created is an entirely novel solution to the problem of knowledge in the AI era. This article will describe why and how we rebuilt Pinecone, the results of more than a year of active development, and ultimately, what we see as the future of vector databases.
The Future of Knowledge in AI
Our clients' needs have continued to evolve, and we have seen massive changes in how they use Pinecone. Before diving into Pinecone serverless, we will look at the user behaviors and patterns that have informed its development over the past year.
Labeling
One example of a client whose use case guided our development of Pinecone serverless is Gong. They have developed an innovative “active learning system” called Smart Trackers that leverages AI, allowing it to detect and track complex concepts in conversations.
Smart Trackers leverage Pinecone as follows: user conversations are processed and converted into sentences. These sentences are embedded into a 768-dimensional vector and stored within Pinecone alongside metadata. Once sentences are embedded, Gong uses Pinecone for vector searches to identify sentences similar to the user-provided examples. These search results are analyzed and classified based on their relevance to the tracked concept.
What is novel in their use of Pinecone this way is that labeling is an on-demand use case. The queries are infrequent and aren’t sensitive to latency — several seconds is good enough since it is a human labeling activity. However, we need to run cost-efficient searches over billions of vectors.
In our pod-based architecture, this would have been cost-prohibitive for Gong. With Pinecone serverless, their costs decreased by 10x. This is because, with serverless, Gong gets both low latency and cost-effective search over billions of vectors.
Traditionally, vector databases have used a search engine architecture where data is sharded across many smaller individual indexes, and queries are sent to all shards. This query mechanism is called scatter-gather — as we scatter a query across shards before gathering the responses to produce one final result. Our pod-based architecture uses this exact mechanism.
Before Pinecone serverless, vector databases had to keep the entire index locally on the shards. This approach is particularly true of any vector database that uses HNSW (the entire index is in memory for HNSW), disk-based graph algorithms, or libraries like Faiss. There is no way to page parts of the index into memory on demand, and likewise, in the scatter-gather architecture, there is no way to know what parts to page into memory until we touch all shards.
Such an architecture makes sense when you are running thousands of queries per second spread out across your entire corpus, but not for on-demand queries over large datasets where only a portion of your corpus is relevant for any query.
What this means for labeling use cases is that the cost per query for such use cases ends up being proportional to the total data under management: the entire index needs to be available all the time, even if you are only querying once every few minutes/hours, and even if you can tolerate latencies of a few seconds.
Traditional serverless approaches also don’t work here: these indexes are massive, so it is not economical to load these indexes on-demand, nor is it efficient enough to allow for interactive queries, as blob storage latencies would be prohibitively expensive for loading such large datasets in their entirety.
To drive order of magnitude cost savings to this workflow, we need to design vector databases that go beyond scatter-gather and likewise can effectively page portions of the index as needed from persistent, low-cost storage. That is, we need true decoupling of storage from compute for vector search.
Multitenant search
One example is Notion, whose users create, update, search for, and get recommended content. However, the usage of individual users varies dramatically; some users store a lot of data, and others very little. Some users are running queries constantly, while others are sporadically. Likewise, some users update their content frequently, while others do so infrequently. That means massive variation in the usage profiles between tenants—this is a pattern we see across many of our customers. At the same time, given the highly interactive nature of the usage pattern, queries typically need to return with sub-100ms latencies.
The solution to multi-tenancy within an index in Pinecone is what we call namespaces.
Customers like Notion leverage thousands of namespaces within a single index for cost-effectiveness at scale while ensuring isolation.
Namespaces map to tenants and allow for data isolation between tenants—one tenant cannot access another’s data. In the pod-based architecture, namespaces could be spread across shards. Likewise, a query for a namespace would have to scatter-gather over all shards to retrieve the relevant candidates.
To dramatically improve cost efficiencies in this workflow, we again need to avoid scatter-gather.
On top of that, we also need to effectively collocate and cache namespaces so that the frequently-used-namespaces can be queried with low latency, while the infrequently-used-namespaces can be efficiently paged from persistent low-cost storage on demand.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) combines LLMs alongside a vector database like Pinecone to augment the LLM with knowledge.
Since the release of ChatGPT in December 2022, we have seen a massive increase in our user base, and without a doubt, it was this use case powering the majority of our 10K+ daily signups.
We commonly see RAG used for three purposes:
- LLMs lack up-to-date knowledge, so RAG provides recent information. Information may be current news, up-to-date stock data in commerce, user data, etc.
- LLMs lack out-of-domain knowledge; this could be knowledge on a unique topic that LLMs do not understand or internal knowledge such as company documents. We saw this use-case most frequently online with the “chat with your PDF” phenomenon.
- LLMs are prone to hallucination. Researchers have shown RAG reduces the likelihood of hallucination even on data that the model was trained on. Moreover, RAG systems can cite the original sources of their information, allowing users to verify these sources or even use another model to verify that facts in answers have supported sources.
Our research on RAG shows that you can dramatically improve the performance of LLMs on many tasks, even on the data they were trained on, by leveraging a vector database that stores the embeddings generated from their billion-scale training corpus.
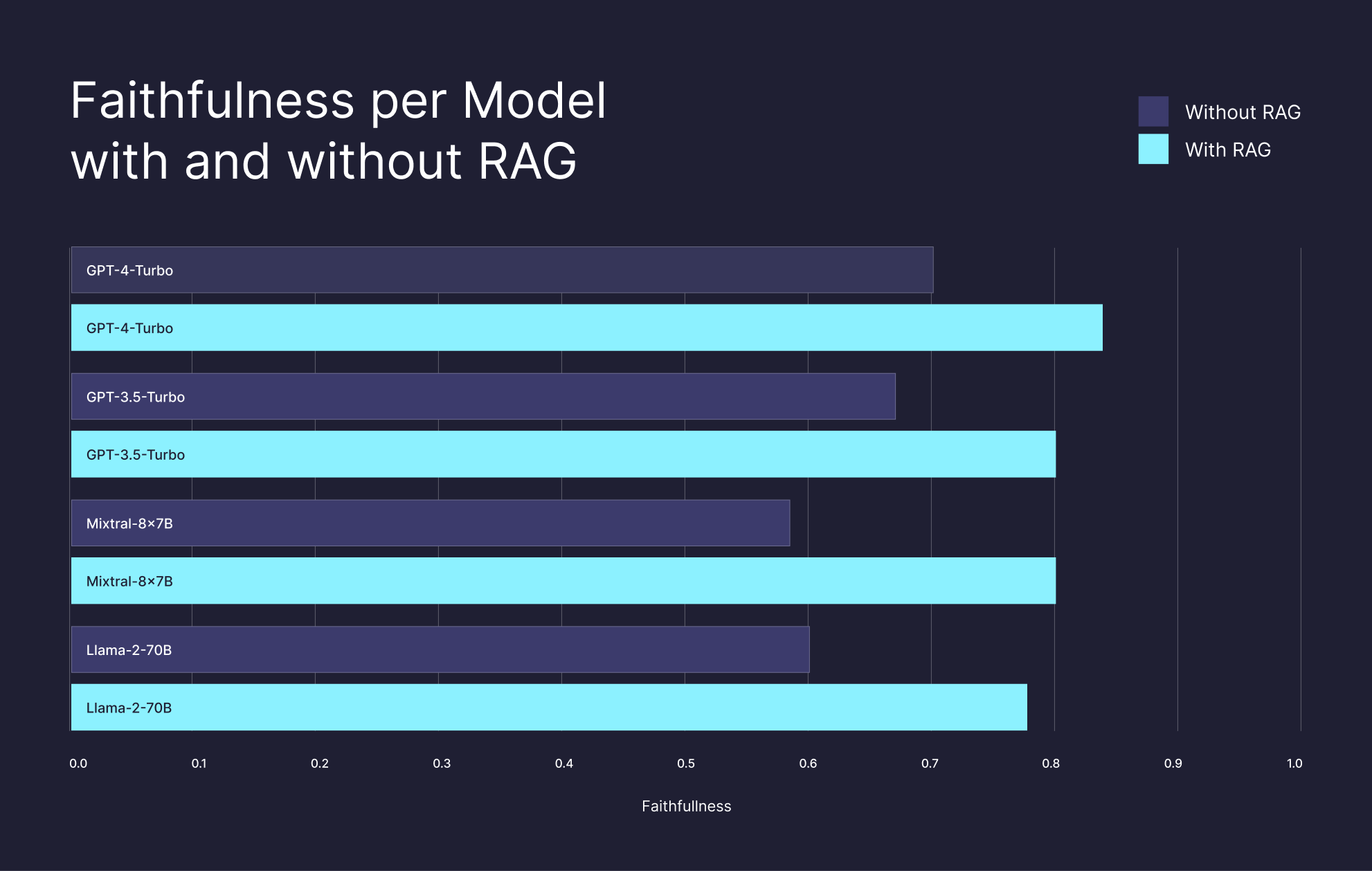
These results suggest that RAG is a great equalizer for knowledge-intensive tasks. By supplying LLMs with precise and relevant information, RAG enables a smaller, cost-effective open-source model like Llama2-70b to outperform GPT-4 without RAG and achieve nearly equivalent performance when GPT-4 is equipped with RAG.
However, for RAG to be a great equalizer, searches using a vector database must also be economical. This scenario is only possible if we can decouple storage from compute. Without it, one would have to pay the cost of storing the entire billion scale index on some fast local storage like SSDs or RAM, and these costs turn out to be a non-starter for such optimizations.
Likewise, updating a billion scale index incrementally and efficiently when the index is in persistent storage is a complex problem. Existing vector search libraries like HNSW and FAISS struggle with incrementally updating indexes even when they are in memory, let alone being able to update them in persistent storage efficiently. If we can solve these problems, even storing the world’s knowledge in vector databases can become economical and augment an LLM’s internal representation to build more knowledgeable AI applications.
Usage Patterns
Across all the above and many other use cases, we observe at Pinecone that vector databases have high demands on freshness, elasticity, and cost at scale.
Very few of our use cases are primarily static corpora that only tend to serve queries.
This point is striking for two reasons: most of the research and development around vector search and vector search libraries has been optimized around mostly static datasets. Likewise, most, if not all, of the existing vector search benchmarks focus on QPS and latency on static datasets and ignore essential complexity like updates and deletes, concurrent workloads, cost to serve, cost to scale elastically, etc.
Based on years of running and observing production workloads across many different operating points, our strong conviction is that such focus and attention on static corpora is entirely misguided.
Freshness, elasticity, and cost at scale are also areas that are challenging for vector databases.
Freshness, in particular, is challenging for vector databases. All existing vector search algorithms struggle to deal with keeping indexes fresh on dynamically evolving corpora.
With graph algorithms like HNSW, this manifests itself as the difficulty with maintaining the “small world” property of the graph as data is dynamically added and/or removed from the index.
With clustering-based algorithms like IVF or IVF-PQ, this manifests itself as difficulty maintaining well-separated clusters as the data distribution changes over time. Either way, vector databases have unique challenges in keeping their indexes fresh.
Elasticity has been one of the most frequently requested features at Pinecone. The traditional search engine architecture makes elastically scaling indexes hard. In this architecture, horizontal scaling requires provisioning additional shards and moving data around, which at scale can be manual, slow, expensive, and prone to run into issues with concurrent workloads. This difficulty is one of the reasons why most such architectures offer vertical scaling but not horizontal scaling, including our own pod-based architecture.
At Pinecone, we introduced the concept of collections to allow customers to scale their indexes horizontally without moving data in and out of the platform.
To allow people to elastically scale up their index to meet demands, an architecture that decouples storage from compute is essential. With Pinecone serverless, users no longer need to create collections to resize their indexes or think in advance about how to size their indexes. They can simply start ingesting data without worrying about sizing.
Pinecone serverless architecture
The serverless architecture must solve three critical pain points inherent in vector databases to achieve freshness, elasticity, and cost at scale.
- Separation of storage from compute: How can we effectively decouple the index from compute so that only relevant portions of the index can be paged on demand from low-cost persistent storage? And how do we do so with low enough latencies that it solves the use cases that our customers care about?
- Multitenancy: How do we handle namespaces such that we can have 100s of thousands of namespaces in an index and ensure that a long tail of infrequently-queried namespaces does not drive up the costs of an index?
- Freshness: How do we provide a fresh and up-to-date index to the tune of a few seconds?
Separation of storage from compute starts with having blob storage as the source of truth for all indexes in the Pinecone serverless architecture.
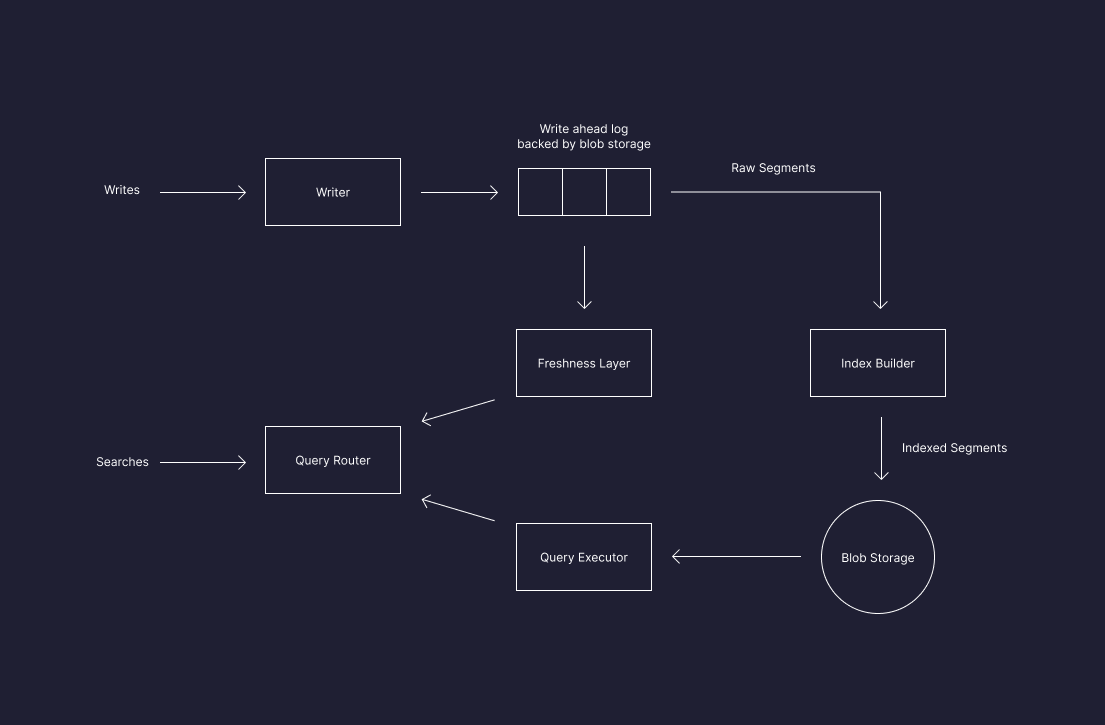
As the index receives new data, writers commit it to blob storage and record it in a log, which provides sequencing of all mutations applied to the index.
Two separate processes are responsible for tailing this log: one is the freshness layer, and the other is the index builder.
The index builder is responsible for building a geometrically partitioned index and does much of the heavy lifting to optimize the index for efficient queries.
Geometric partitioning can be thought of as dividing the space of vectors into regions.
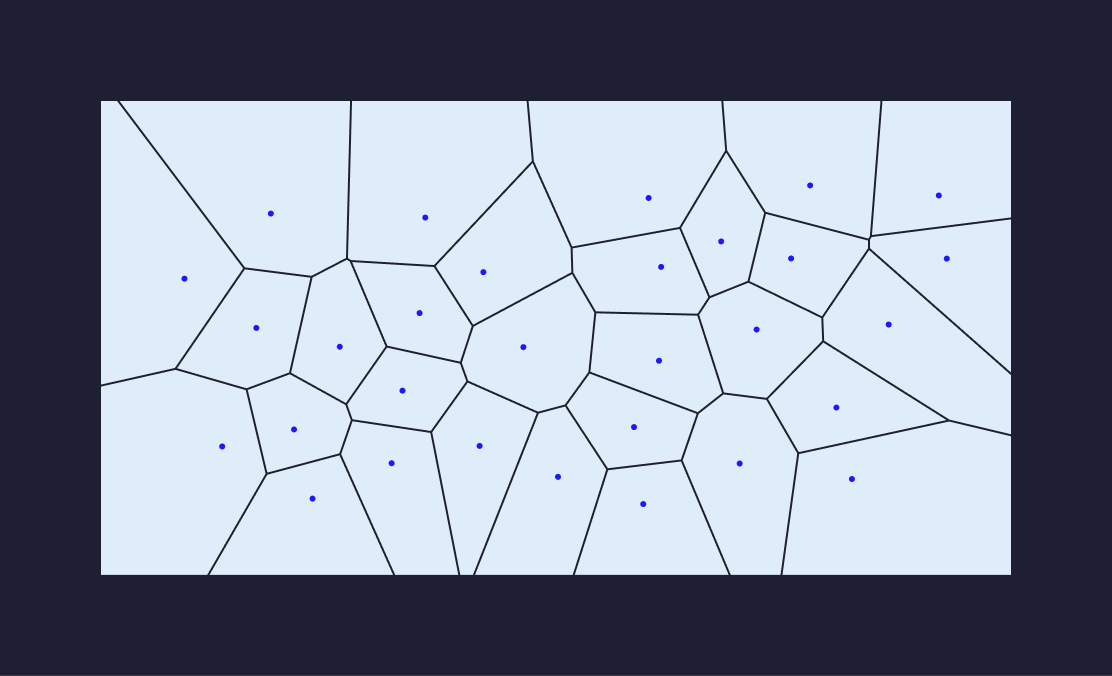
Once space has been partitioned geometrically, we maintain the centroid vectors as representatives of each partition. Every new point gets assigned to the partition corresponding to the closest centroid to that point. The index builder reads newly committed data and adds each point to a specific partition.
Once the points are assigned to a partition, the index segments are built and committed to blob storage. The index builder also updates the index manifest to let everyone know the valid indexed segments and the maximum version number of the records that have been indexed so far.
This process immediately enables two features in conjunction with storing segments in blob storage:
- Only relevant segments need to be loaded for queries since we now have a fine-grained geometric partitioning of the index.
- Partitioned segments are immutable and can be easily loaded, cached, and managed on query executors.
Geometric partitioning assumes that we can divide up the space of vectors nicely into well-arranged partitions. This assumption is true as long as the data is static and is what algorithms like IVF, IVF-PQ, etc. do. However, the nature of workloads in the real world is such that we don’t know all the data in advance. (indexes in Pinecone are rarely static) Hence, we need a mechanism to build and rebuild partitions dynamically as needed.
Therefore, the index builder maintains a hierarchy of partitions starting from coarse-grained to more refined as it sees more data. This process allows the index to be incrementally maintained and stay efficient for search as data evolves.
With the ability to incrementally (re) build indexes, we unlock another critical feature of serverless: you only need to load segments that have been newly added and are relevant for a given query. This feature will allow RAG applications to continue to serve fresh results at scale as users add, edit, and redact documents.
All these, taken together, are what is required to enable efficient separation of storage from compute for vector databases. These components represent a core innovation in Pinecone serverless.
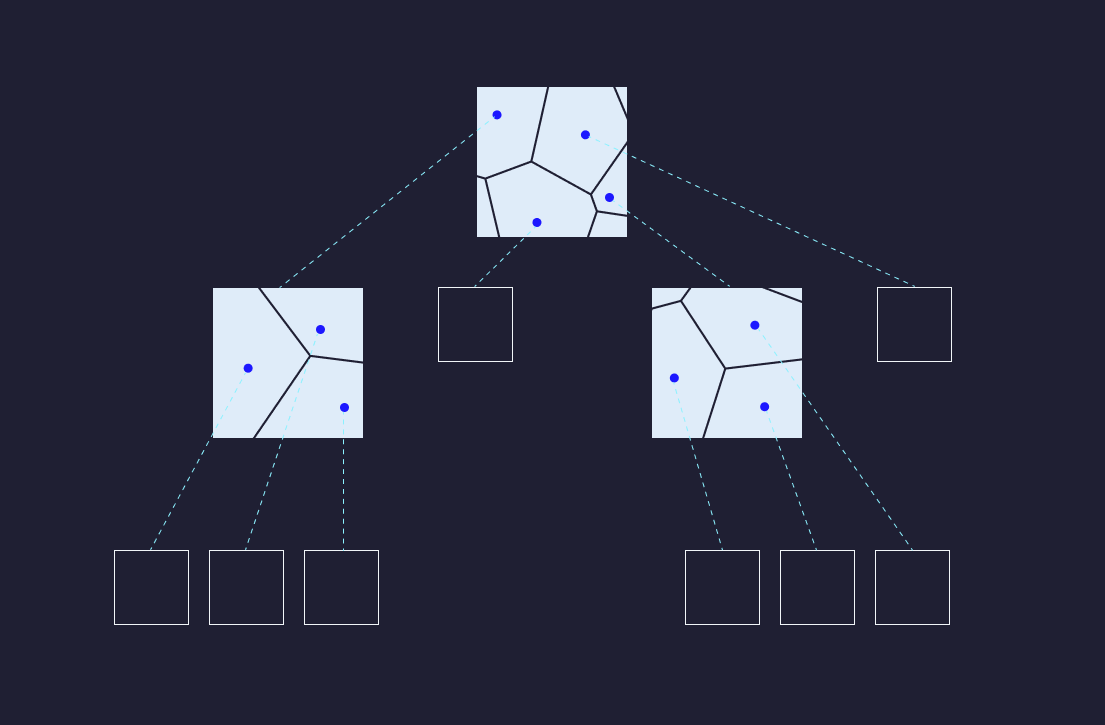
In parallel to the index builders, the freshness layer tails the same log and builds a compact fresh index over the most recent data. The freshness layer only cares about data that hasn’t been indexed yet, and it figures this out using the max version number of the index manifest. The freshness layer is what allows customers to edit, add, or redact documents and have them available for search within seconds.
With query executors responsible for searching over indexed data and the freshness layer responsible for serving the most recent writes, we can provide an up-to-date view of the index using a lambda-style architecture for vector search.
Executors load the data segments that are relevant to queries upon first access and cache them locally. It is caching that brings all the economic benefits of serverless without sacrificing the low latency requirements of applications like Notion, Gong, etc.
Namespaces in Pinecone serverless act as hard partitions on your data. Index builders only build geometric partitions within namespaces. And queries filter on namespaces to restrict their search space to segments generated for specified namespaces. The design of Pinecone serverless treats namespaces as the fundamental unit of isolation, so it is designed to provide these guarantees out of the box. Indexes then inherit those guarantees automatically and can be logically thought of as a collection of namespaces.
Namespaces allows customers like Notion to leverage multi-tenancy to drive down the costs of serving their RAG applications to their own customers without sacrificing latency, isolation, or security.
Next steps for Pinecone serverless
Today, we are proud to release Pinecone serverless in public preview for all our customers and anyone who wishes to gain a first-of-its-kind vector database that takes ease of use to the next level.
The initial release optimizes for ease of use, the ability to ingest and query data across orders of magnitude in scale, and obtain high search quality at low cost.
That said, there are many features we are working on that will make their way into Pinecone serverless this year:
- More clouds and regions: The initial public preview of Pinecone serverless will be on AWS us-west-2 region. We plan to expand Pinecone serverless to additional regions as well as other clouds like Azure and GCP.
- Performance mode: Some use cases require extremely low and consistent query latency or high throughput. We will support a performance-focused variant of the serverless architecture, which meets these requirements alongside all the other benefits of this architecture.
- Database security: Ensuring your data is secure in Pinecone is a top priority for many users. We will add support for additional security features like PrivateLink support, audit logging, and customer-managed encryption keys to Pinecone serverless.
What does the future hold for vector databases?
Pinecone serverless was designed to solve some of the most challenging problems with vector databases, such as freshness, elasticity, and cost at scale. We have made significant headway into meeting these challenges, but at the same time, we are only scratching the surface of research and development in vector databases.
Vector databases are fundamentally different from traditional databases, and at the same time, they inherit some of the challenges of traditional databases.
Traditional databases deal with structured data and are good at that. Such databases have by now perfected the techniques of organizing data so that you can access fresh and accurate results at scale. This capability is possible only because the data and queries are highly structured and restrictive.
Vector databases are inherently different: vector embeddings don’t have the same structure as traditional columns in databases do. Likewise, the problem of searching for the nearest neighbors of a query in your vector database is fundamentally computationally intensive in anything but the smallest databases. It is a mistake to think of a vector database as just another data type with just another index in an SQL/ NoSQL database. For precisely this reason, every such attempt to naively integrate vectors into traditional databases is doomed to fail at scale.
Every vector database returns an approximate list of candidates for such a search. The only difference is that a vector database provides the best cost to search quality tradeoff.
In the pod-based architecture, we took the approach that we always want to provide the highest possible search quality, even if it means, in some cases, the costs can be higher. Everyone else has taken the approach that the user must figure out how to tune vector databases to get to a high enough recall. In fact, not a single vector database benchmark out there even talks about recall and the cost of achieving a certain recall on any given benchmark.
We think it is time the situation changes: after all, a vector database’s primary purpose is to provide high-quality search results in a cost-effective manner. If we don’t have a simple and intuitive way to present this tradeoff to users without expecting them to become performance engineers on vector search, then we fail as a cloud-native database. At Pinecone, we measure and obsess over providing the best user experience and the best search quality economically at scale, which motivates the architectures we choose and the design tradeoffs we make.
With Pinecone serverless, we have taken a big step in the direction of the future of vector databases. But we expect to rapidly continue delivering on that vision with continued scale, elasticity, and search quality improvements to cost tradeoff.
Some benchmarks
We collected some benchmarks that compare our pod-based architecture to Pinecone serverless. In due course, we will also release a benchmarking suite along with our methodology for benchmarking vector databases so anyone can reproduce these benchmarks and use them to compare other vector databases and traditional databases on the workloads that matter.
The datasets used in these benchmarks span a range of sizes, dimensions, and complexity.
Cost to query at high recall
Here, we benchmarked what it costs to serve queries on the pod-based architecture vs Pinecone serverless across various datasets, keeping recall at least as high as the pod-based architecture.
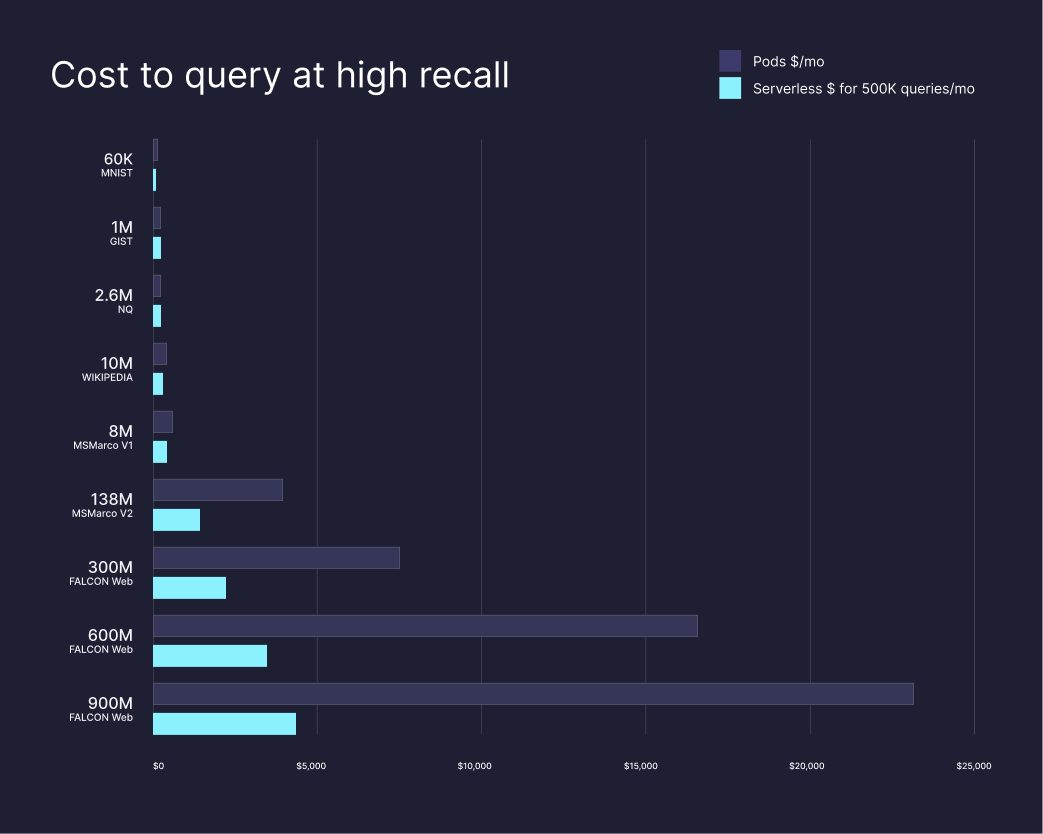
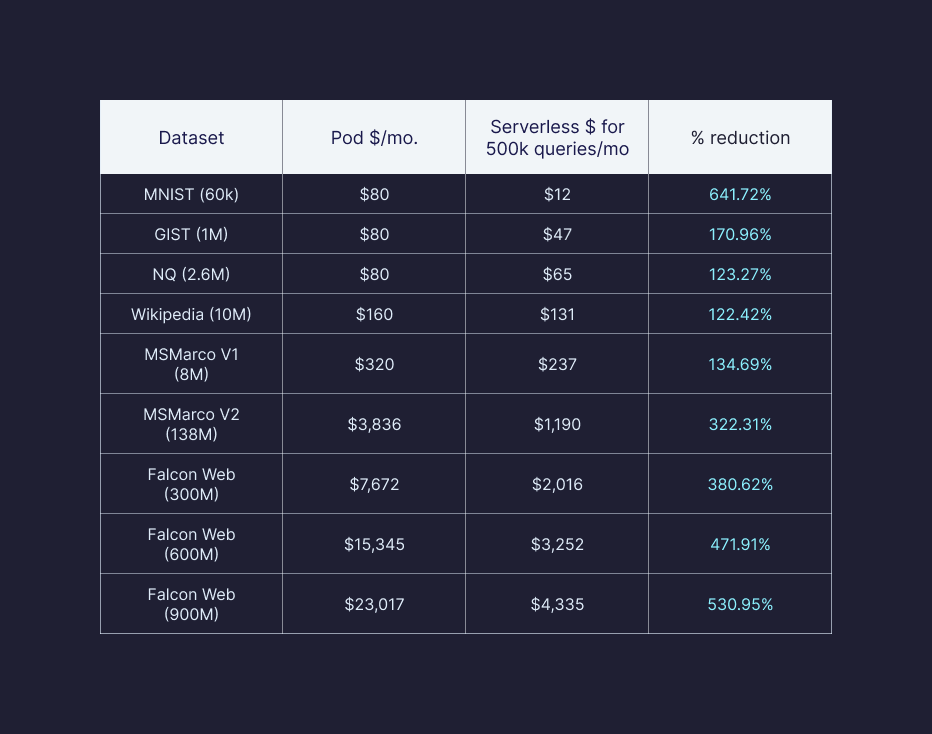
Most of our users run less than 500K queries against their index monthly and will see even larger cost savings than we have shown above. For our higher QPS users, we still see cost savings across most use cases. Users with very high QPS requirements will benefit from the serverless performance-tier pricing and packaging.
Serverless Latencies
Query latencies are lower for most scenarios with Serverless, with an average latency reduction of ~46.9% found in our benchmarking of Pods against Serverless. For example, benchmarking the Cohere-768 dataset, we found a massive 85% reduction in latency. Our goal was to optimize resource usage at scale, and we expect there is even more we can do here as we deliver performance-tier features.
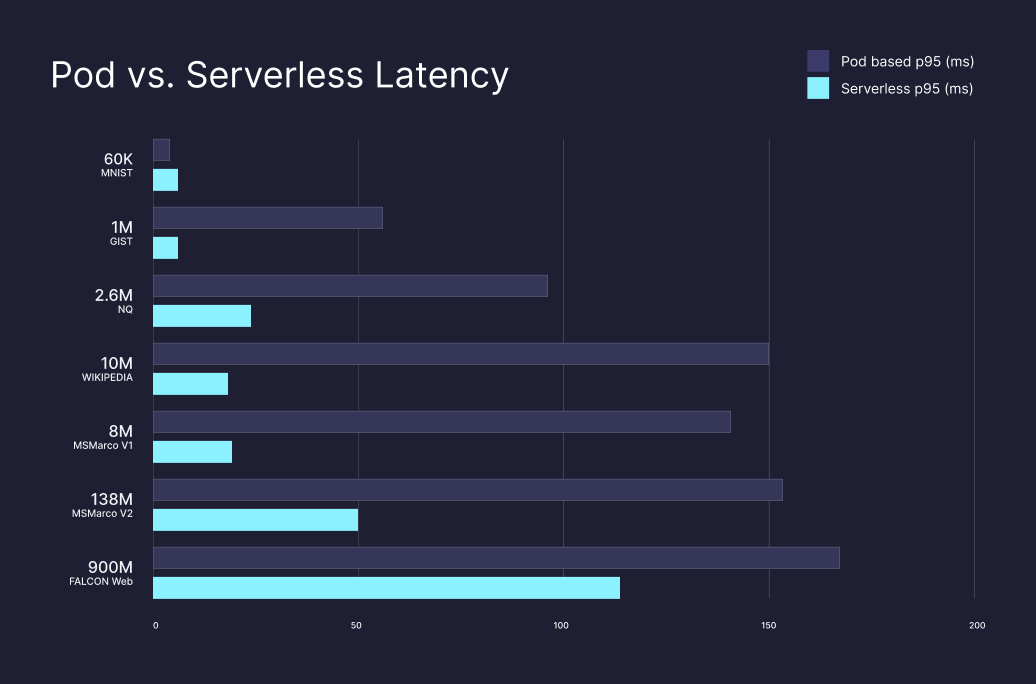
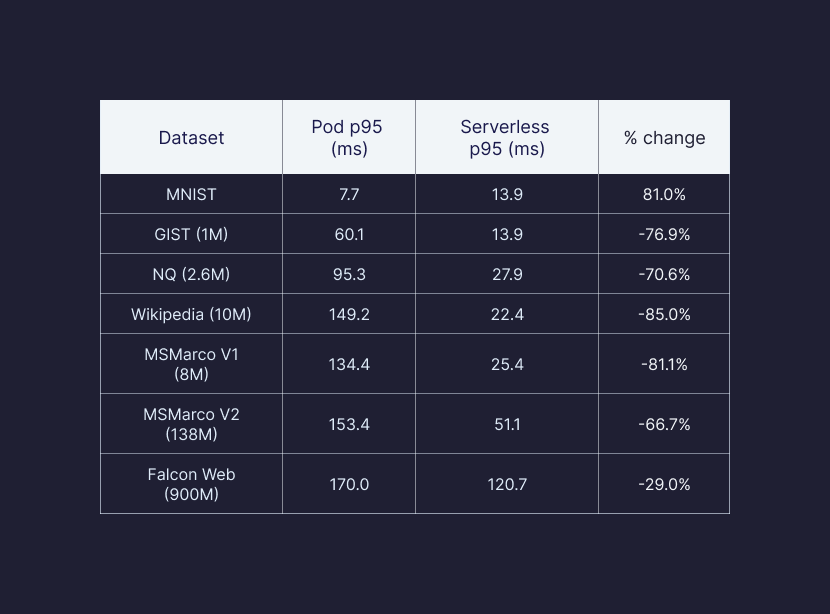
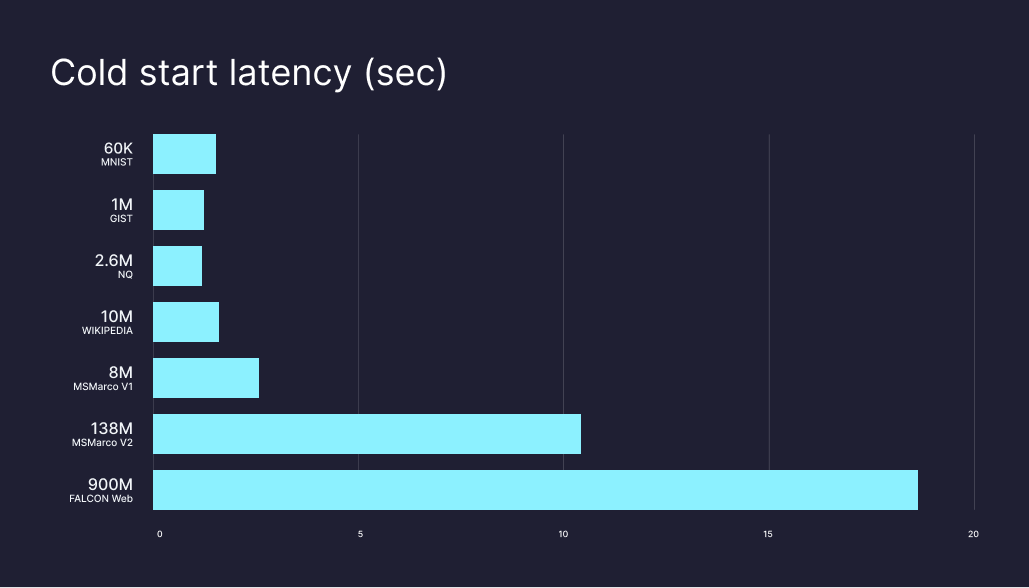
Cold start latencies (maximum latency for first-time queries) in Pinecone serverless are expected to be in the order of a couple of seconds for most datasets and up to around 20 seconds for queries over billion scale datasets.
Recall at Scale
Latency, costs, and recall were the focus of serverless. Pinecone’s pod-based architecture already provided SotA recall performance. Our goal with Serverless was to maintain or beat that performance, and we did.
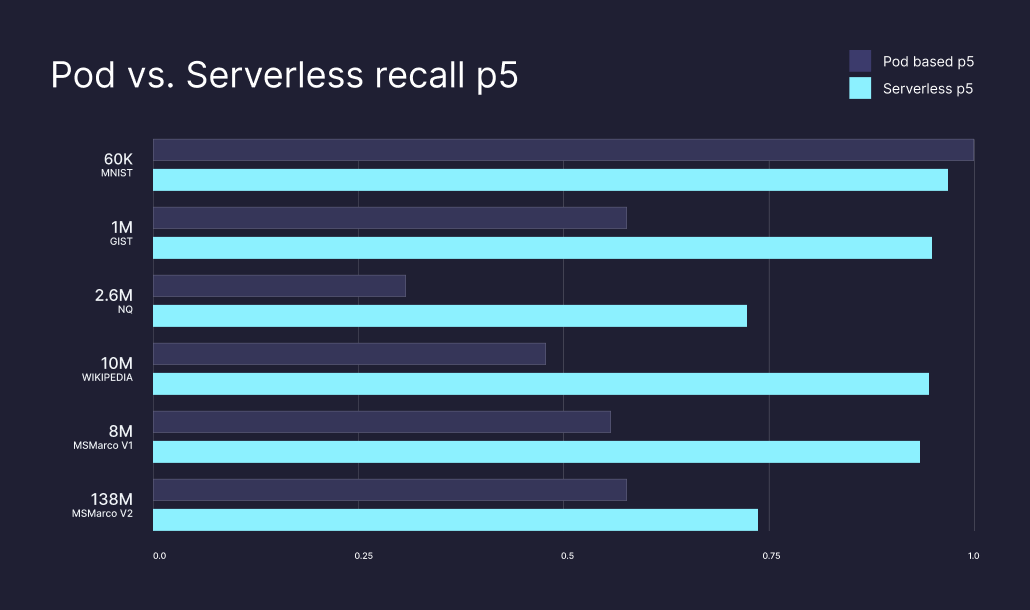
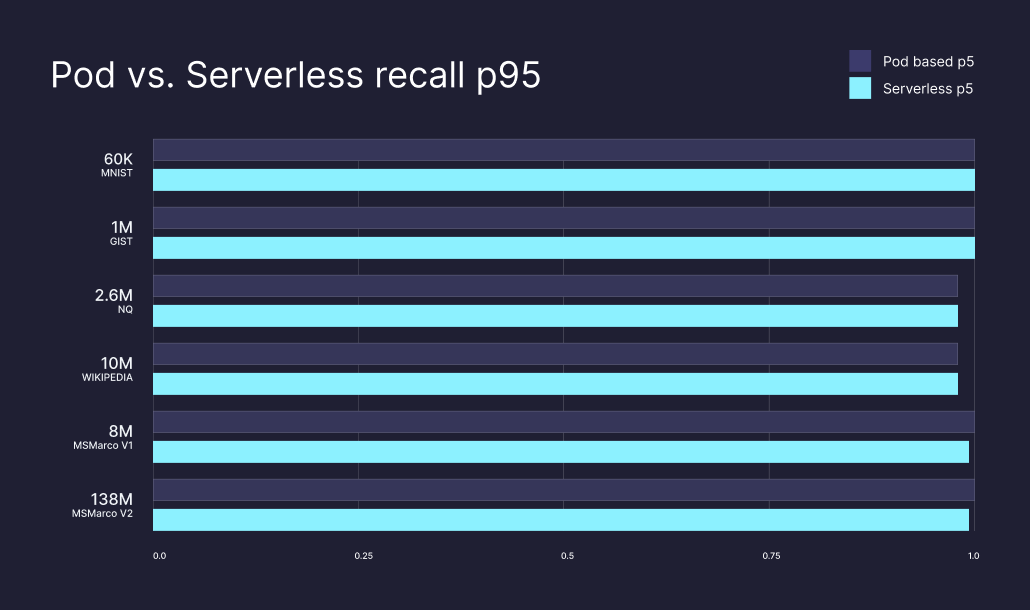
Our best gains came from improving many of our “worst case” recall performances. At p95 (the majority of calls), Serverless and pod-based return similar recall performance, but our worse-case performances (p50 and p5) are significantly improved.
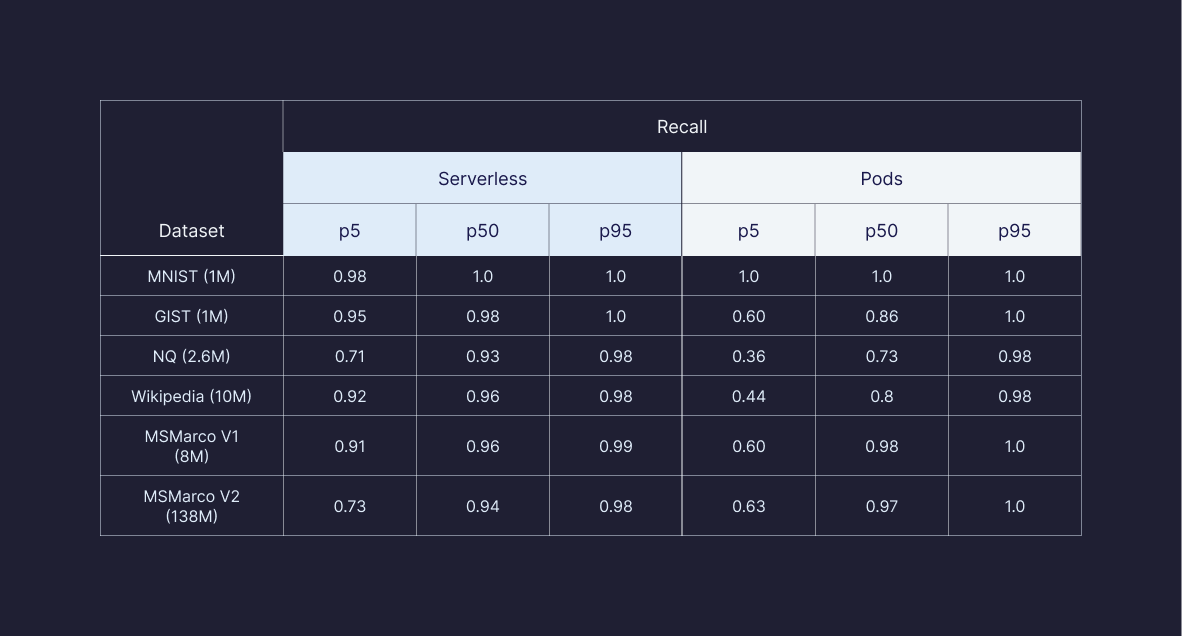
These benchmarks only scratch the surface of all the measurements we measure and care about. We plan to open source these and other benchmarks, our benchmarking tools, and methodologies that we use to benchmark SaaS vector databases across a diverse set of workloads.
We hope that this will be broadly useful to the community and help shape the future of vector databases.




