Winning in AI means mastering the new stack
AI in 2030
AI is rapidly changing. Too rapidly for most. Ten years ago it was all about big data and ML. Deep Learning was a “buzzy” term that was just picking up steam. The term “AI” was still reserved for the futuristic dream of human level intelligence. The technology was used mostly by hyperscalers for advertising optimizations, search, feed ranking in online media, product recommendation in shopping, abuse prevention online, and a few other core use cases. Five years ago ML Ops was all the rage, as companies started grappling with feature engineering and model deployments. Their ambitions had mostly to do with data labeling, churn prediction, recommendation, image classification, sentiment analysis, natural language processing, and other standard machine learning tasks. Roughly a year ago LLMs and foundational models completely transformed our expectations from AI. Companies started investing in chat bots, and RAG powered knowledge hubs, automating customer support, legal discovery, medical history, and others. Peeking into 2024 and beyond, it would seem that agents and co-pilots are taking center stage. And, that solving hallucinations while making LLMs more trustworthy and usable in user facing products will be a main focus. We don’t know what AI will look like after that, let alone in 2030. We are pretty sure nobody knows.
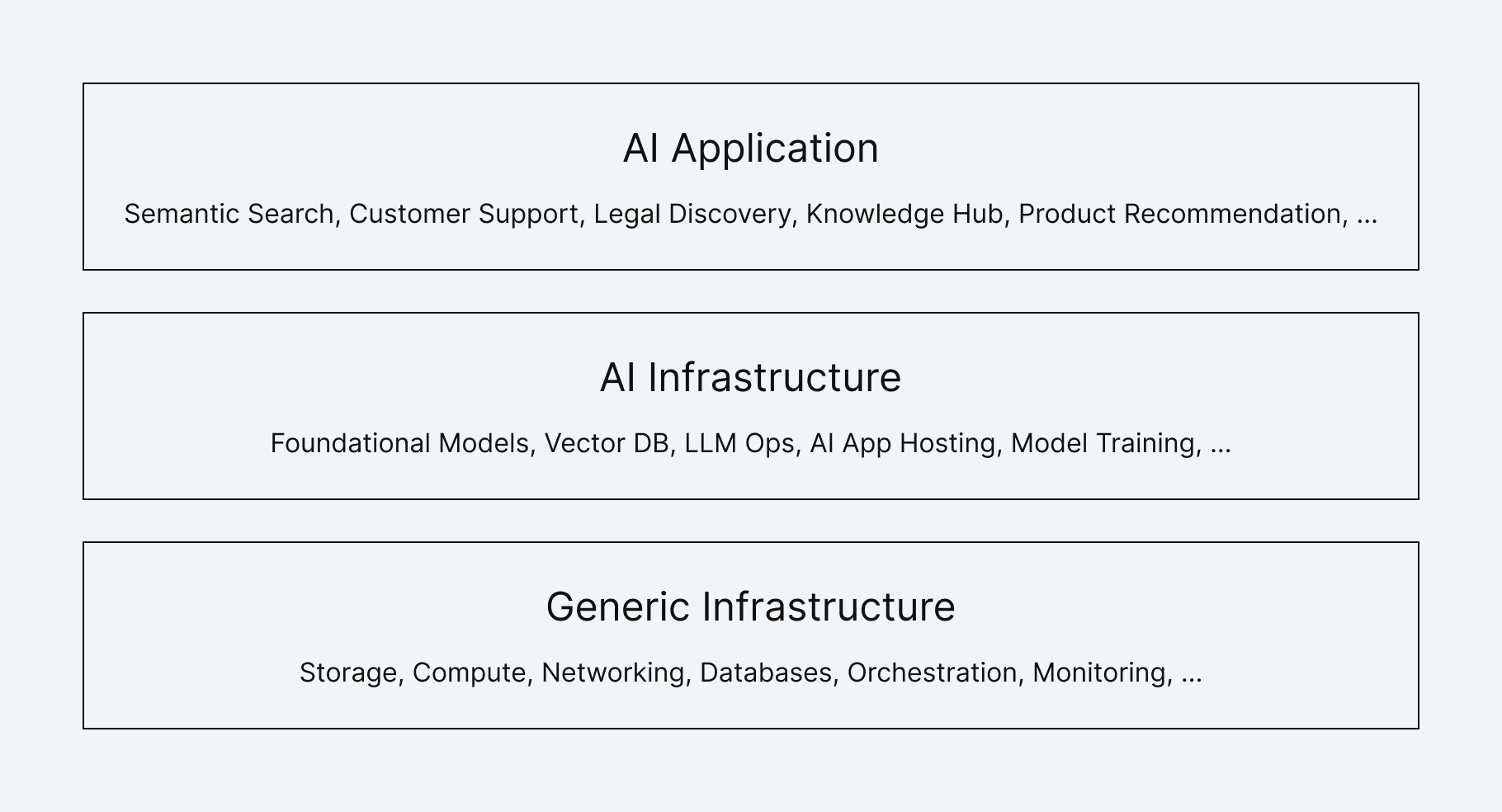
Nevertheless, somehow in this head-spinning innovation frenzy, the infrastructure components which power almost all AI based solutions remained surprisingly constant.
Some things don’t change…
While there are many AI product architectures, a few core infrastructure building blocks seem to power almost all of them. These include capabilities for model training and hosting, pretrained foundation models, vector databases, model pipelines and data operations, labeling, evaluation frameworks, and AI application hosting.
These components are not new. Ad serving at Google is using vector search for candidate generation for many years now. Distributed neural network training was being built at Meta for feed-ranking model training for more than a decade. At the same time, multimodal embeddings for shopping recommendations were being generated by Amazon and Microsoft built vector based retrieval and ranking into Bing. These are only a handful of examples.
The main challenge for the rest of the market was that the AI stack was confined to the hyperscalers. Those were the only companies who had the scale to justify their development and the talent to support it. Other companies had a tough choice between giving up and making a Herculean effort to build inhouse. Companies like Uber, Netflix, Yahoo, Salesforce, Pinterest, and others exemplify those whose investment in AI talent and technologies was quite remarkable (and visionary) compared with the size of their business.
Today, companies no longer have this dilemma. They have the option to simply use the infrastructure for AI (from companies like ours). In fact, these tools are now readily available, easy to use, and affordable. But, we are getting ahead of ourselves…
The challenges going forward
Before describing the new stack, we outline the current and future challenges AI applications will face. Note that AI applications face all the challenges that all other software services face. Issues like code quality, deployments, uptime, speed, correctness, etc. The list below only points to unique new challenges.
Multimodal data and models will soon be the norm. Today’s text-based applications will be flooded with images and video. Existing services will be far more data intensive and will have to rethink their interfaces across the entire stack.
Data is growing and becoming more complex. Massive amounts of text and multimodal data will have to be processed by models and made available to AI applications in real time. Such applications expect to access data by meaning as a source of knowledge. Traditional databases, which most engineers are familiar with, struggle mightily with such applications.
Hardware is changing. A burgeoning ecosystem of hardware accelerators will begin to relieve some of today’s compute shortages, but the need to leverage (and mix between) a broad and evolving set of accelerators will pose new challenges around portability and performance optimization.
Application development is becoming more AI centric and well integrated with advanced tooling and AI capabilities. This means traditional web development is becoming much more storage and compute intensive.
Model training is also transitioning. With foundational models, we move away from (only) model development from scratch. Capabilities for model retraining and fine tuning are needed. While this greatly reduces the computational burden it also poses new challenges regarding model customization and composition which will strain our already strained model evaluation capabilities.
Cloud centrality is becoming a key success factor. Negotiating between data gravity and model gravity requires new cloud native services that are very dynamic and optimized in their use of compute, storage, and networking. Moreover, cloud portability and cross cloud functionality is becoming a core design tenet for many. This is why effectively the entire AI stack is served only as cloud native services with the major cloud providers.
Needless to say, building these capabilities in-house is unfeasible for most and unnecessary for nearly all. To take advantage of these new opportunities, businesses will need to learn how to use the right infrastructure. That infrastructure must address these needs but also be future proof. That means being optimized for flexibility, iteration speed, and general applicability.
The AI Stack
Foundational Models: Models are expected to either transform a document or perform a task. Transformation usually means generating vector embedding for ingestion in vector databases or feature generation for task completion. Tasks include text and image generation, labeling, summarization, transcription, etc. Both training such models and operating them efficiently in production is very challenging and incredibly expensive. Companies like AI21 Labs offer the best in class LLMs which are highly optimized for embedding and generation, and AI21 Labs also builds highly specialized models that solve specific business challenges. They are not only hosted but are constantly retrained and improved.
Model training and Deployment: One of the defining characteristics of AI workloads is how compute intensive they are. As such, successful AI teams build with scale in mind. Their need for scale comes from larger models, from larger quantities of data, and from an exploding number of models to build and deploy. Simply computing the embeddings to power a vanilla RAG application can require hundreds of GPUs running for days.
The need for scale introduces tremendous software engineering challenges around performance, cost, and reliability, all without compromising on developer velocity. Anyscale develops Ray, an open source project used as the foundation of AI infrastructure across the tech industry and used to train some of the world’s largest models like GPT-4.
Vector Database: Knowledge is at the core of AI and semantic retrieval is the key to making relevant information available to models in real time. To do that Vector databases have matured and specialized to be able to search through billions of embeddings in milliseconds and still remain cost effective. Pinecone recently launched its newly architected, cloud native, and serverless vector database. It now lets companies scale with no limits and build performant applications (like RAG) faster than ever before. Many companies reduce their DB spend by up to 50x with this new product.
AI Application Hosting: AI applications present unique new challenges for the application rendering, delivery, and security stack. For one, unlike traditional websites, AI apps are more dynamic by nature, making traditional CDN caching less effective, and rely on server rendering and streaming to meet users’ speed and personalization demands. As the AI landscape evolves rapidly, iterating quickly on new models, prompts, experiments, and techniques is essential, and application traffic can grow exponentially, making serverless platforms particularly attractive. In terms of security, AI apps have become a common target of bot attacks to attempt to steal or deny LLM resources or scrape proprietary data. Next.js and Vercel are investing heavily in product infrastructure for GenAI companies, driving iteration velocity for developers and fast, secure delivery to end users.
LLM Developer Toolkits: Building LLM applications requires taking all the above mentioned components and putting them together to build the “cognitive architecture” of your system. Having an LLM toolkit like LangChain to bring these different components together can allow engineers to build faster and higher quality applications. Important components in this toolkit include: the ability to flexibly create custom chains (there is a good chance you will want to customize your cognitive architecture), a variety of integrations (there are many different components to connect to), and first class streaming support (an important UX consideration for LLM applications).
LLM Ops: Building a prototype is one thing, taking it into production is a whole other issue. Aside from the logistics of hosting the application (covered above) there emerges a whole other set of issues around the reliability of the application. Common issues include being able to test and evaluate different prompts or models, being able to trace and debug individual calls to figure out what in your system is going wrong, and being able to monitor feedback over time. LangSmith - a platform built by the LangChain team but independent of the framework - is a comprehensive solution for these issues.
Our pledge
As the CEOs building the new AI stack, we are committed to future-proofing your AI applications. We are committed to building the best building blocks. We are committed to constantly improving the integrations between our products. We commit to include and evolve alongside other AI products and services. We are committed to being there with you when your demands evolve over time. We are committed to your success in leveraging AI in the years to come.
Bios
Edo Liberty, CEO Pinecone
Edo Liberty is the Founder and CEO of Pinecone, the managed database for large-scale vector search. Edo previously was a Director of Research at AWS and Head of Amazon AI Labs and Head of Yahoo’s Research Lab building horizontal machine learning platforms. Edo received his B.Sc in Physics and Computer Science from Tel Aviv University and Ph.D. in Computer Science from Yale University. After that, he was a Postdoctoral fellow at Yale in the Program in Applied Mathematics. He is the author of more than 75 academic papers and patents about machine learning, systems, and optimization.
Guillermo Rauch, CEO Vercel
Guillermo Rauch is the founder and CEO of Vercel and the creator of Next.js, which powers the leading Generative AI companies on the web. Guillermo previously co-founded LearnBoost and Cloudup, where he served the company as CTO through its acquisition by Automattic in 2013. Originally from Argentina, Guillermo has been a developer since the age of ten and is passionate about contributing to the open-source community.
Ori Goshen, Co-CEO AI21 Labs
Ori Goshen is a seasoned entrepreneur and a graduate of IDF's elite intelligence unit 8200. Prior to founding AI21 Labs, he co-founded Crowdx, a network analytics company (acquired by Cellwize). Beforehand, Mr. Goshen served as a product manager at Fring (acquired by Genband) and led the development of the first ever made VoIP and messaging app for iPhone and Android. Mr. Goshen brings more than 15 years of experience in technology and product leadership roles.
Robert Nishihara, CEO Anyscale
Robert Nishihara is one of the creators of Ray, a distributed framework for seamlessly scaling and productionizing AI workloads. Ray is used by innovative companies like Uber, OpenAI, Netflix, Amazon, and others to scale machine learning training, inference, and data ingest workloads. Robert developed Ray with his co-founders at the UC Berkeley RISELab. He received his PhD in machine learning and co-founded Anyscale to commercialize Ray. Before that, he majored in math at Harvard.
Harrison Chase, CEO Langchain
Harrison Chase is the co-founder and CEO of LangChain, a company formed around the popular open source Python/Typescript packages. The goal of LangChain is to make it as easy as possible to use LLMs to develop context-aware reasoning applications. Prior to starting LangChain, he led the ML team at Robust Intelligence (an MLOps company focused on testing and validation of machine learning models), led the entity linking team at Kensho (a fintech startup), and studied stats and CS at Harvard.
Was this article helpful?



