Less is More: Why Use Retrieval Instead of Larger Context Windows
Large Language Models (LLMs) have been around for a while, but in the last couple of months the idea of expanding the context window of transformer-based models has been booming, especially as a solution to hallucination. Anthropic released a 100K context window Claude model, and OpenAI followed with a 32K GPT-4 model and a 16K GPT-3.5 model.
The idea of a large context window seems appealing at first — just give the model all your data and let it figure it out. However, this approach of “context stuffing” actually comes at a cost and performs worse than expected:
- Answer quality decreases, and the risk of hallucination increases. Below we review two studies that show LLMs struggle to extract relevant information when given very large contexts.
- Costs increase linearly with larger contexts. Processing larger contexts requires more computation, and LLM providers charge per token which means a longer context (i.e, more tokens) makes each query more expensive.
Research shows that LLMs provide the best results when given fewer, more relevant documents in the context, rather than large numbers of unfiltered documents.
In a recent paper from Stanford titled "Lost in the Middle," Liu and team show that state-of-the-art LLMs often encounter difficulties in extracting valuable information from their context windows, especially when the information is buried inside the middle portion of the context.
The team showed that LLMs actually struggle to “separate the wheat” out of a long, incoherent context - where numerous documents are used as input to the model, and that this problem intensifies as the size of the context increases.
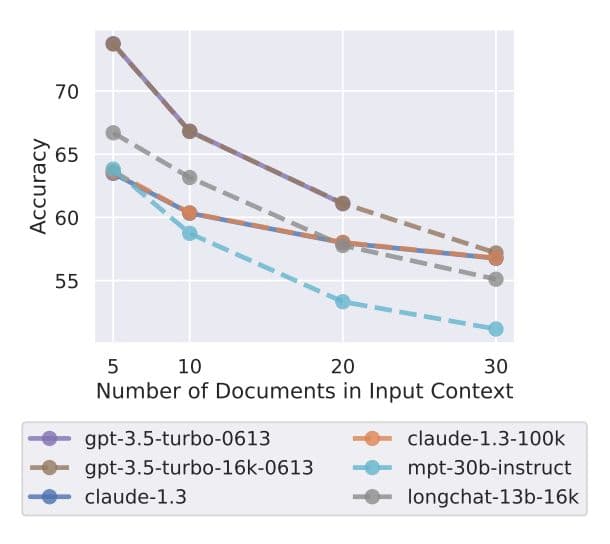
In this experiment, the authors measured the performance of LLMs on the Natural Questions (NQ) dataset, containing genuine queries made to Google search. Each time, the model is given a set of k documents, with precisely only one of them containing the answer, while the other k-1 are distractors (do not contain the answer). As shown above, with each increase in k, there’s a corresponding decrease in the model's accuracy. For instance, a gpt-3.5-turbo-16k model especially designed for extended context experienced nearly a 20% drop in accuracy when dealing with 30 documents as compared to 5.
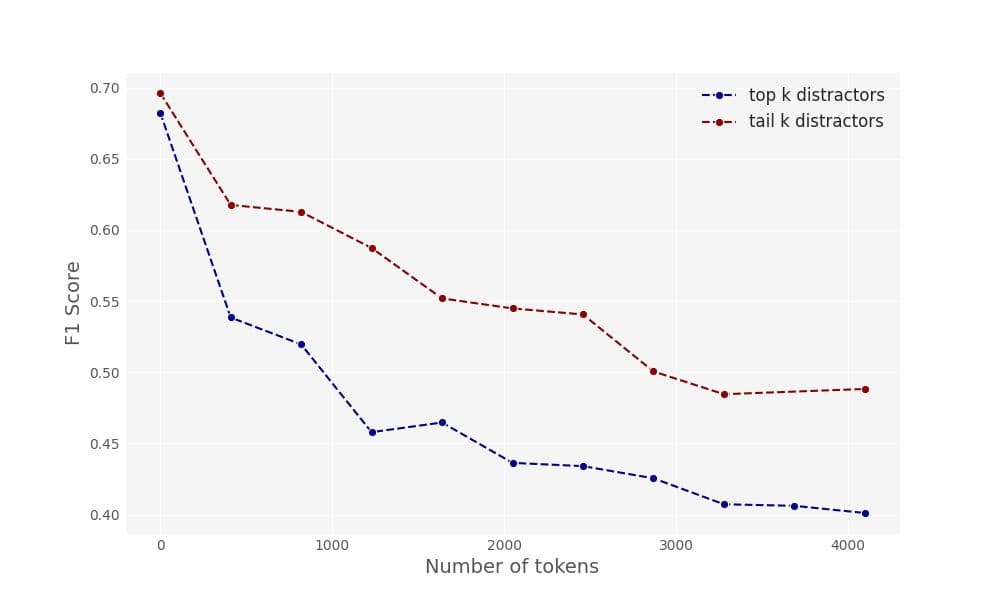
We conducted a similar experiment with minor adaptations. In our experiments, we were also interested in evaluating how well LLMs perform when given a diverse corpus of documents, simulating a scenario where unfiltered documents — such as a complete website or a file directory — are provided to the model. To accomplish this, we used the top 1,000 documents returned for each query from the NQ dataset using Pinecone with OpenAI ada-002 embeddings, and compared the model's performance (using F1 score at the token level) under two conditions:
- When the model was given the document with the answer along with the top k-1 retrieved documents (same as in the paper) — simulating a coherent corpus of documents highly related to the query.
- When the model was given the document with the answer along with the tail (bottom) k-1 retrieved documents — simulating a more diverse and unfiltered corpus of documents.
According to our results, the model struggled to extract the relevant information in both settings: When provided with the most similar distractors (“top”) and the most dissimilar distractors (“tail”), although the performance was slightly better in the latter case.
Naturally, this is where retrieval systems come into play. Retrieval systems have been developed and optimized over decades, and are specifically designed to extract relevant information on a large scale, doing so at a significantly reduced cost. Furthermore, the parameters of these systems are explicitly adjustable, offering more flexibility and opportunities to optimize compared to LLMs. The use of retrieval systems to provide context to LLMs forms an approach known as Retrieval Augmented Generation (RAG).
These findings hold true even when all the information is contained within a single document. To illustrate the proficiency of retrieval for individual documents, we utilized a random sample of 200 questions from the QuALITY dataset, which comprises multiple-choice question-answer pairs based on lengthy documents such as books and articles (averaging 5K tokens with a maximum of 8K tokens). We compared the performance-per-token of ChatGPT-4 under two different scenarios:
- Using retrieval on document segments (RAG).
- Sequentially processing the document from the beginning, referred to as the baseline.
For the retrieval process, we employed all-MiniLM-L6-v2 embeddings to extract the top-k segments from the documents (each 100 tokens long), and then sorted them chronologically.
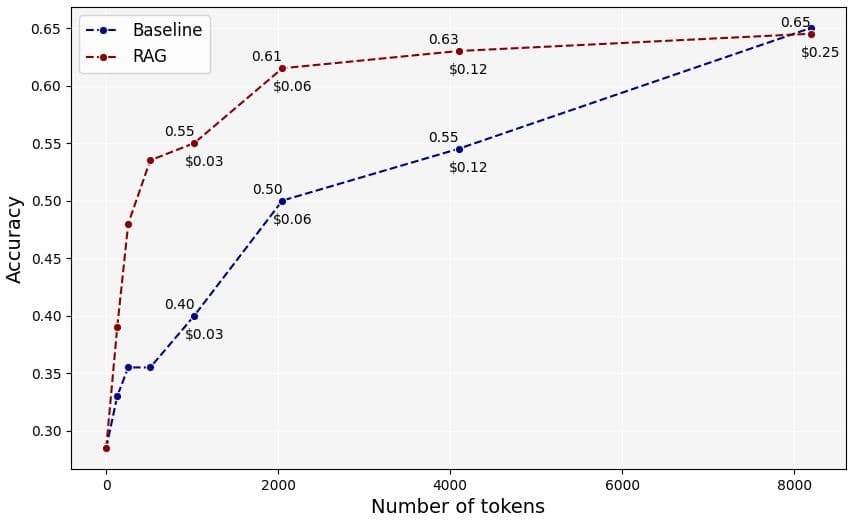
As illustrated below, retrieval has the capability to pull relevant data from long documents and provide more focused contexts. In other words, retrieval improves the accuracy achieved per token. For instance, RAG preserved 95% of the original accuracy from when the model processed the entire documents, despite only using 25% of the tokens. This resulted in a considerable cost reduction of 75%, with only a marginal drop in quality (while index and search costs were negligible). This is critical for production applications since large context windows tend to be more resource-demanding.
These experiments show that stuffing the context window isn't the optimal way to provide information for LLMs. Specifically, they show that:
- LLMs tend to struggle in distinguishing valuable information when flooded with large amounts of unfiltered information.
- Using a retrieval system to find and provide narrow, relevant information boosts the models' efficiency per token, which results in lower resource consumption and improved accuracy.
- The above holds true even when a single large document is put into the context, rather than many documents.
Information retrieval systems such as Pinecone play a pivotal role in improving model accuracy and efficiency. This translates to lower operating costs and lower risk of hallucination in real-world Generative AI applications.
Was this article helpful?