Pinecone Helps Deep Talk Deliver World-Class AI Assistants with Lower Engineering Overhead

Deep Talk makes it simple for companies to turn text– particularly conversational data like phone transcriptions, chats, emails, and surveys– into AI assistants that understand customer needs and predict their satisfaction levels. They cater to a wide range of industries with specialized needs, including retail, healthcare, and banking, serving clients such as Liverpool Mexico, Mercado Libre, Pfizer, and BCI Bank. They’ve earned several notable accolades, including prestigious grants from Start-Up Chile and France’s Station F.
Deep Talk’s models can:
- detect frequent customer issues in conversations
- discover recurring flows that solve these problems
- extract training phrases to design and improve bots
- predict customer satisfaction
- analyze message urgency
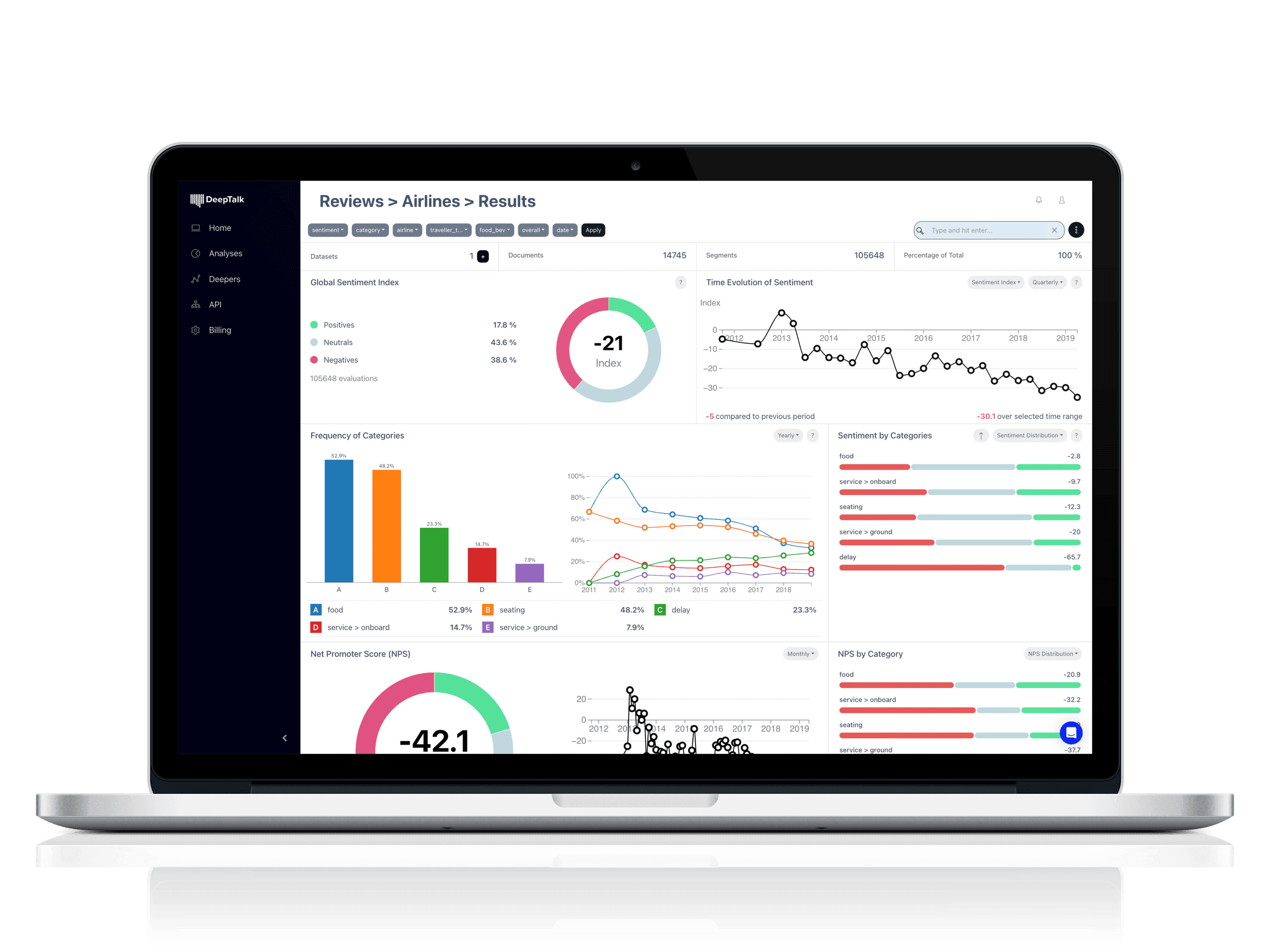
The insights from these models were already available through their Feedback Analysis solution, which categorizes and analyzes this information to find patterns and trends.
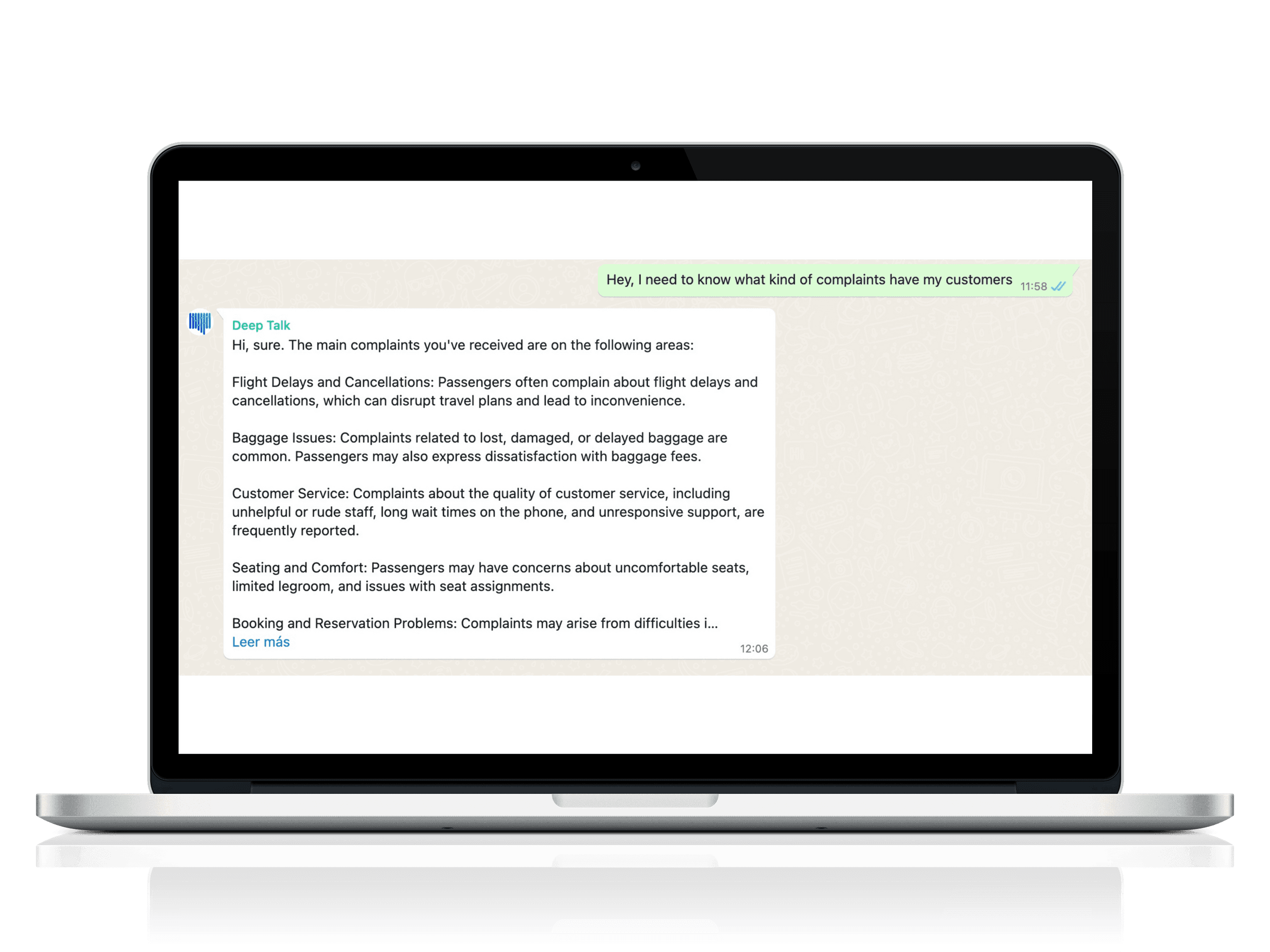
And their customers were pressing them to create full-fledged assistants that could be used by employees and customers alike to surface those insights- a new solution they called Corporate GPT.
Deep Talk needed a path to bring their AI Assistant to market, fast; it was critical to preserve the quality of their answers across industries and data types; and they needed a way to search reliably across a body of information that was growing and changing rapidly– at the speed of an entire company’s WhatsApp conversations with customers.
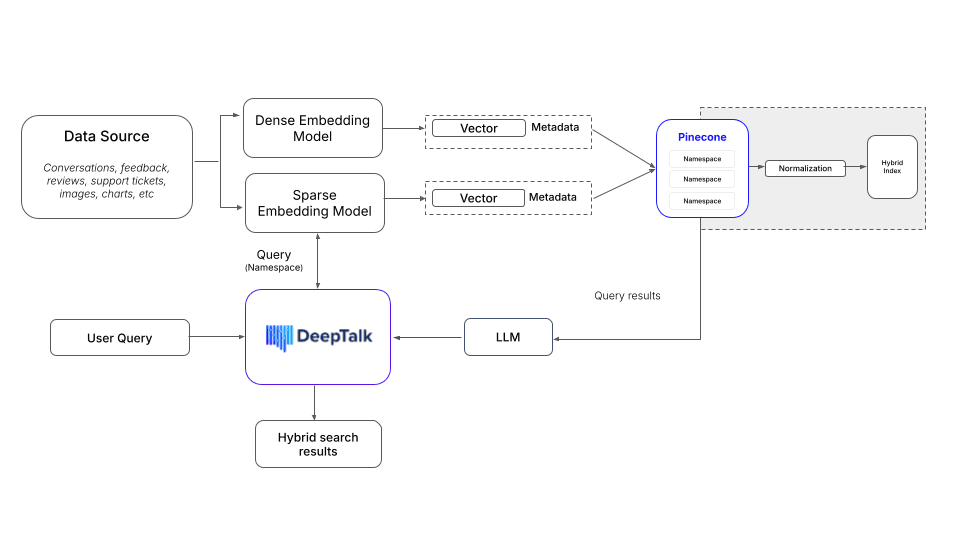
Deep Talk’s healthcare solution showcases how they adapt their technology to meet the unique demands of the industry. By combining Feedback Analysis of physicians satisfaction with an AI Assistant for conversational, evidence-based medicine, they provide a robust tool for healthcare providers. With the help of Pinecone, Deep Talk efficiently stores, manages, and retrieves a wide range of unstructured medical data— from clinical studies and drug labels to patient feedback— ensuring that providers have access to the right information exactly when they need it. Here’s how Pinecone fits into their workflow:
- Data Preparation: The team uses different techniques to process various data formats:
- Text data is extracted from PDFs and other documents using standard chunking methods.
- Text descriptions are created for images instead of using visual recognition.
- Tables and flowcharts are converted into text using diagramming and charting tools, making them easier to work with in their LLMs.
- Embedding Creation: The team generates vector embeddings from the prepared data using OpenAI models. These embeddings, along with relevant metadata such as numerical values and lists of strings, are stored in Pinecone. The metadata helps to filter and refine search queries effectively.
- Search and Retrieval: The team also uses Pinecone hybrid search, combining keyword and semantic searches to enhance retrieval accuracy. This is crucial for finding specific terms, such as drug names, with high precision.
- Data Organization: Separate namespaces are used to manage data from different customers and projects. This multi-tenant segregation ensures clear and organized analysis, maintaining data privacy and project clarity.
Getting to market quickly
Pinecone has saved the Deep Talk team time and reduced costs, enhanced their ability to innovate, and significantly improved the accuracy of their customer feedback analysis:
- Time Savings: Instead of maintaining their own vector database, Deep Talk saved approximately 3 weeks of full-time engineering work on the initial setup and about 2 full days per month on ongoing maintenance.
- Cost Efficiency: By eliminating the need to purchase and maintain server infrastructure, Deep Talk has saved significant engineering time and associated costs. Also, with Pinecone serverless, they benefit from a cost-effective solution that charges only for the resources they actually use, further increasing cost savings.
- Increased Innovation Capacity: Engineering resources can now focus on developing new products and features instead of maintaining a vector database.
Opening door for innovation
The infrastructure built around Pinecone has empowered Deep Talk to innovate and offer new ways for their customers to interact with their feedback data.
This shift allows for deeper understanding and more actionable outcomes, opening up opportunities for innovation that were previously out of reach.
"Pinecone opened up new possibilities for interacting with data, leading to innovative products like our AI assistant for Feedback Analysis." - Philipp Grothaus, CTO at Deep Talk
Handling fast-moving data
Deep Talk’s customers have massive volumes of data coming in through chat applications. At first, the team used Chroma, an open-source database, to process and store data, but it became too cumbersome to maintain and didn’t handle their growing needs well.
To deliver accurate and timely data insights, the team needed a reliable vector database that could handle complex similarity searches and scale effectively. After evaluating different options, they chose Pinecone for its ease of use, fast performance, cost-effectiveness, and ability to handle their large-scale operations.
“Pinecone was incredibly easy to use, allowing us to quickly achieve success. We chose it to fulfill the promises we made to our clients with the products we were building.” - Philipp Grothaus, CTO at Deep Talk
Building on their initial success with Pinecone's pod-based architecture, Deep Talk has now adopted Pinecone serverless. This transition provides the flexibility and scalability the team needs, while simplifying operations by removing the complexities of infrastructure management. It also allows Deep Talk to deliver better vector search performance at any scale.
What's Next
Deep Talk is committed to continuous improvement and innovation. Plans for Corporate GPT include expanding capabilities to better interpret images and other visual data. For Feedback Analysis, the focus is on providing more condensed and actionable text-based summaries of insights. The team also aims to streamline the user experience and continue delivering high-value insights to their clients.
Sergio Liberczuk, CCO and Co-Founder, expressed his excitement: "Seeing our clients, like Mercado Libre and Pfizer, successfully use our platform is incredibly satisfying. We are continuously evolving to meet and exceed their needs."
Philipp Grothaus, CTO, echoed this sentiment: "My satisfaction comes from knowing our clients are engaged and finding value in our products. The positive feedback and challenges we address drive our continued growth and innovation."