
12%
12%
more accurate search results
↓
↓
Call times and discovery
↑
↑
Compliance
Vanguard, a leading investment management company, offers a range of financial services, including retirement services, advice, and investments. At its core, Vanguard is on a mission to give its clients the best chance for investment success, which includes best-in-class customer support and resources. In this article, we’ll dive into how Ashish Bansal, Principal ML Engineer at Vanguard, and his team worked with Pinecone to transform Vanguard’s approach to customer support.
Dramatically improving retrieval to meet latency and accuracy requirements at scale
Before Pinecone, Vanguard’s customer support teams relied on keyword-based search solutions to search for documents where answers to a customer’s question may live. While this approach provided links to source documents, it required representatives to then manually search for answers within these dense, lengthy documents — ultimately increasing call times and reducing customer satisfaction. In order to mitigate lengthy calls during peak seasons (e.g. tax season, where slow responses have a direct financial consequence), Vanguard would hire additional representatives, adding operational cost and overhead.
Vanguard knew they needed a more efficient solution for customer service agents to handle and respond to support tickets. The Center for Analytics and Insights (CAI) team within the Chief Data Analytics office at Vanguard was tasked with finding an alternative solution to support real-time retrieval for a highly dynamic dataset. To do so, they knew they needed to move beyond a keyword search-based system to a semantic or vector search-based system.
Hybrid retrieval delivers the best of both keyword- and semantic-based search
Bansal and his team first experimented with JSON storage and cosine similarity-based search solutions. During early evaluations, however, they encountered significant performance limitations: 1) The solution was slow in both search and generation, 2) managing growing data sets became increasingly inefficient, and 3) search results were often not contextually relevant.
Recognizing the need for a more powerful and scalable search solution, Vanguard’s leadership directed the team to explore vector databases. When evaluating various solutions — pgvector, Faiss, Redis, and Pinecone — the team was looking for a solution that met the following requirements:
- Hybrid search: The ability to combine dense and sparse search (BM25 + dense embeddings) to improve overall search accuracy.
- Real-time updates: The ability to efficiently index and retrieve results in real-time, even as the workload grew.
- Enterprise-readiness: A solution that met Vanguard’s stringent security requirements, including support for AWS PrivateLink.
- Flexible metric selection: The ability to experiment with different distance metrics across indexes.
- Advanced metadata filtering: a critical feature for compliance, allowing differentiation between outdated and current documents.
The team ultimately chose Pinecone as the best solution to meet their use case and requirements. From there, the team built and launched a new internal RAG-powered chat assistant called Agent Assist for the customer support team.
“One of the reasons we chose Pinecone beyond functionality is because Pinecone was willing to work with Vanguard, specifically to meet our security control and performance requirements by creating a dedicated AWS account and cluster for us.” - Hung Pham, ML Engineer at Vanguard
Building Agent Assist, an AI assistant powered by Pinecone
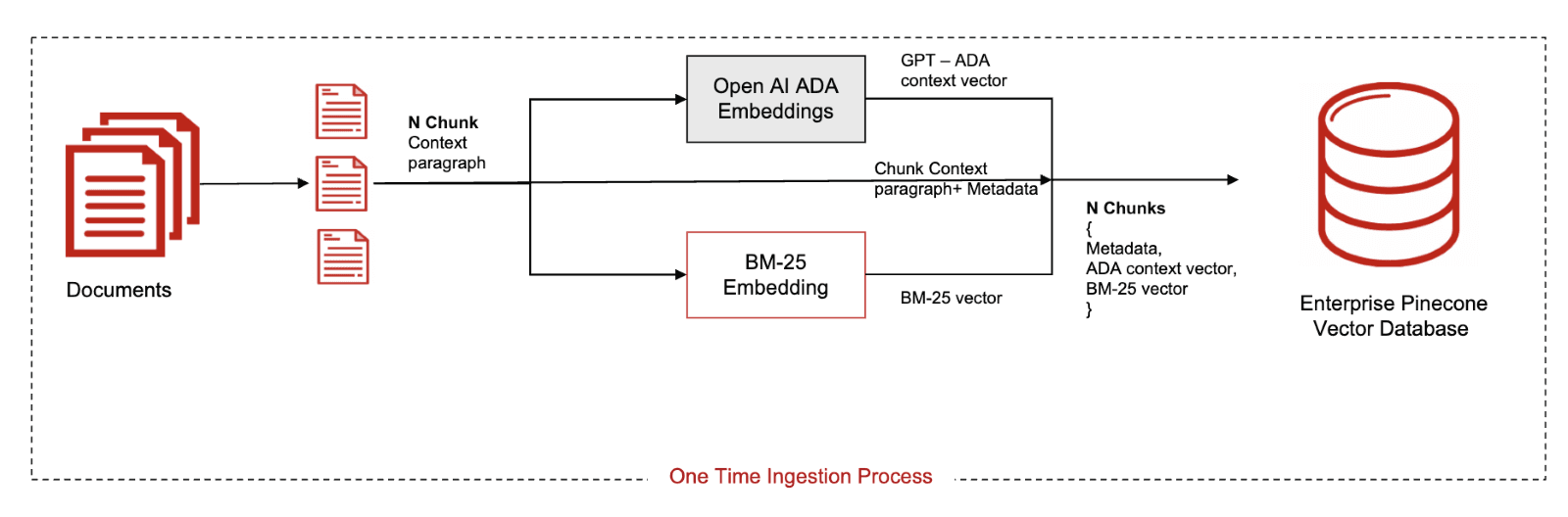
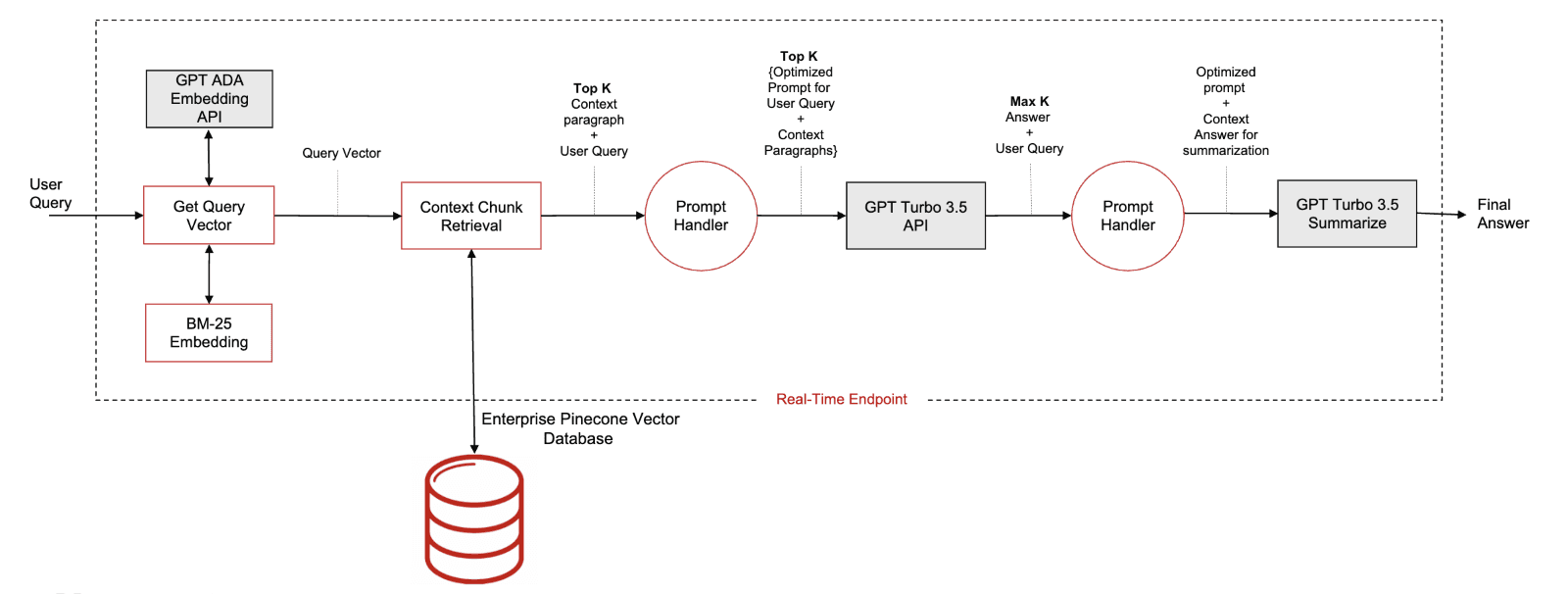
The workflow for Agent Assist begins by scraping financial documents stored as HTML pages and preprocessing them with a custom chunking strategy. From there, dual dense and sparse embeddings are created, with sparse embeddings trained in-house using BM25. The embeddings and their metadata are ingested and stored in Pinecone serverless. Once indexed, the data is queried via hybrid retrieval with Alpha set at 0.5 for optimal precision, especially for financial documents with domain-specific terms and abbreviations.
As policies change and new documents are created daily, it’s critical that customer service agents have real-time access to the latest information. To keep their index fresh, the team uses metadata filtering to mark documents as "live" or "stale" daily, ensuring only the “live” documents are accessed upon retrieval. “Stale” or historical documents are then passed to DynamoDB for long-term storage to meet regulatory requirements.
Faster, more efficient discovery and call times
Since deploying Pinecone, Vanguard has seen tangible improvements:
- Boosted accuracy: Hybrid retrieval improved result accuracy by over 12% compared to dense retrieval alone.
- Reduced call times and overhead: Faster, more precise retrieval has significantly cut customer wait times. Faster, more efficient retrieval also means the team can now support peak periods (e.g., tax season) without additional overhead.
- Enhanced compliance: Metadata tagging enables better traceability for audit purposes.
What’s next for Vanguard
Looking ahead, Vanguard plans to continue its innovation by leveraging RAG and Contextual-Aware Generation (CAG) systems. Pinecone will be an integral part of the knowledge ecosystem, ensuring the most up-to-date information is readily available. This robust foundation will empower Vanguard’s large language models (LLMs) to deliver enhanced contextual awareness, driving forward their mission to create cutting-edge solutions.