Make your chatbot answer right.
Companies have been using chatbot applications for years to provide responses to their users. While early adopters were limited to providing responses based on the information available to them at the time, foundational AI models like Large Language Models (LLMs) have enabled chatbots to also consider the context and relevance of a response. Today, AI-powered chatbots are able to make sense of information across almost any topic, and provide the most relevant responses possible.
With continued advancements in AI, companies can now leverage AI models built specifically for chatbot use cases — chatbot models — to automatically generate relevant and personalized responses. This class of AI is referred to as generative AI.
Generative AI has transformed the world of search, enabling chatbots to have more human-like interactions with their users. Chatbot models (e.g. OpenAI’s ChatGPT) combined with vector databases (e.g. Pinecone) are leading the charge on democratizing AI for chatbot applications, enabling users of any size — from hobbyists to large enterprises — to incorporate the power of generative AI to a wide range of use cases.
Chatbot use cases
Chatbots trained on the latest AI models have access to an extensive worldview, and when paired with the long-term memory of a vector database like Pinecone, they can generate and provide highly relevant, grounded responses — particularly for niche or proprietary topics. Companies rely on these AI-powered chatbots for a variety of applications and use cases.
Examples:
- Technical support: Resolve technical issues faster by generating accurate and helpful documentation or instructions for your users to follow.
- Self-serve knowledgebase: Save time and boost productivity for your teams by enabling them to quickly answer questions and gather information from an internal knowledgebase.
- Shopping assistant: Improve your customer experience by helping shoppers better navigate the site, explore product offerings, and successfully find what they are looking for.
Challenges when building AI-powered chatbots:
There are many benefits to chatbot models such as enabling applications to improve the efficiency and accuracy of searching for information. However, when it comes to building and managing an AI-powered chatbot application, there can be challenges when responding to industry specific or internal queries, especially at large scale. Some common limitations include:
- Hallucinations: If the chatbot model doesn’t have access to proprietary or niche data, it will hallucinate answers for things it doesn’t know or have context for. This means users will receive the wrong answer. And without citations to verify the source of the content, it can be difficult to confirm whether or not a certain response is hallucinated.
- Context limits: Chatbot models need context with every prompt to improve answer quality and relevance, but there’s a size limit to how much additional context a query can support.
- High query latencies: Adding context to chatbot models is expensive and time consuming. More context means more processing and consumption, so adding long contexts to embeddings can be prohibitive.
- Inefficient knowledge updates: AI models require many tens of thousands of high-cost GPU training hours to retrain on up-to-date information. And once the training process completes, the AI model is stuck in a “frozen” version of the world it saw during training.
Vector databases as long-term memory for chatbots
While AI models are trained on billions of data points, they don’t retain or remember information for long periods of time. In other words, they don’t have long-term memory. You can feed the model contextual clues to generate more relevant information, but there is a limit to how much context a model can support.
With a vector database like Pinecone there are no context limits. Vector databases provide chatbot models with a data store or knowledgebase for context to be retained for longer periods of time and in memory efficient ways. Chatbot applications can retrieve contextually relevant and up-to-date embeddings from memory instead of from the model itself. This not only ensures more consistently right answers, especially for niche or proprietary topics, but it also enables chatbot models to respond faster to queries by replacing the computational overhead needed to retrain or update the model.
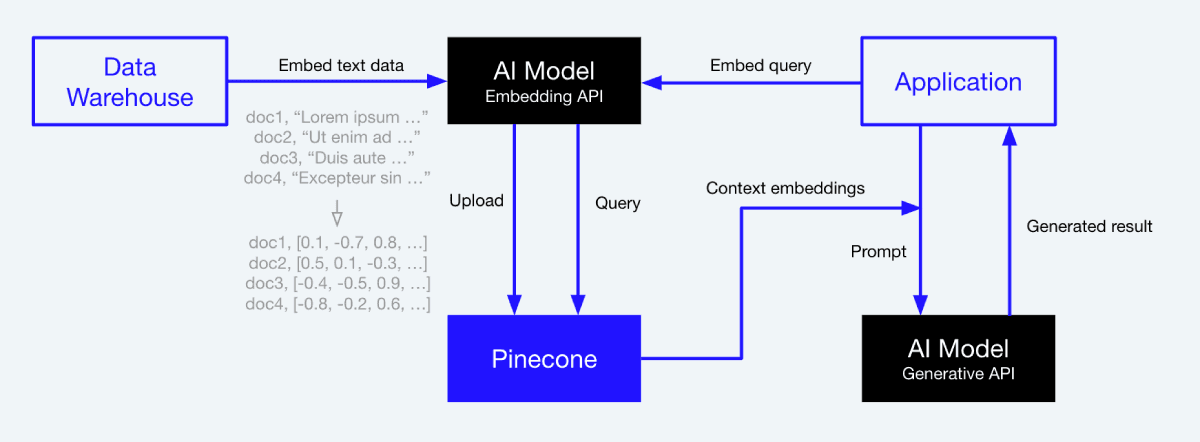
Building chatbots with Pinecone
Pinecone is a fully-managed, vector database solution built for production-ready, AI applications. As an external knowledge base, Pinecone provides the long-term memory for chatbot applications to leverage context from memory and ensure grounded, up to date responses.
Benefits of building with Pinecone
- Ease of use: Get started in no time with our free plan, and access Pinecone through the console, an easy-to-use REST API, or one of our clients (Python, Node, Java, Go). Jumpstart your project by referencing our extensive documentation, example notebooks and applications, and many integrations.
- Better results: With long-term memory, chatbot models can retrieve relevant contexts from Pinecone to enhance the prompts and generate an answer backed by real data sources. For hybrid search use cases, leverage our sparse-dense index support (using any LLM or sparse model) for the best results.
- Highly scalable: Pinecone supports billions of vector embeddings so you can store and retain the context you need without hitting context limits. And with live index updates, your dataset is always up-to-date and available in real-time.
- Ultra-low query latencies: Providing a smaller amount of much more relevant context lets you minimize end-to-end chatbot latency and consumption. Further minimize network latency by choosing the cloud and region that works best (learn more on our pricing page).
- Multi-modal support: Build applications that can process and respond with text, images, audio, and other modalities. Supporting multiple modalities creates a richer dataset and more ways for customers to interact with your application.
How it works
Basic implementation:
With a basic implementation, the workflow is tied directly to Pinecone to consistently ensure correct, grounded responses. To get started:
- Step 1: Take data from the data warehouse and generate vector embeddings using an AI model (e.g. sentence transformers or OpenAI’s embedding models).
- Step 2: Save those embeddings in Pinecone.
- Step 3: From your application, embed queries using the same AI model to create a “query vector”.
- Step 4: Search through Pinecone using the embedded query, and receive ranked results based on similarity or relevance to the query.
- Step 5: Attach the text of the retrieved results to the original query as contexts, and send both as a prompt to a generative AI model for grounded, relevant responses.
Agent plus tools implementation:
Another way to get started is by implementing Pinecone as an agent. The below is an example workflow using OpenAI’s ChatGPT retrieval plugin with Pinecone:
- Step 1: Fork chatgpt-retrieval-plugin from OpenAI.
- Step 2: Set the environmental variables as per this tutorial.
- Step 3: Embed your documents using the retrieval plugin’s “/UPSERT” endpoint.
- Step 4: Host the retrieval plugin on a cloud computing service like Digital Ocean.
- Step 5: Install the plugin via ChatGPT using “Develop your own plugin”.
- Step 6: Ask ChatGPT questions about the information indexed in your new plugin. Check out our notebook and video for an in-depth walkthrough on the ChatGPT retrieval plugin.
Get started today
Create an account today, and access our platform with an easy to use REST API or one of our many clients. Contact us for more information.