How to build an agentic, chat or RAG knowledge system using Pinecone Assistant
Pinecone Assistant is a powerful service that leverages retrieval-augmented generation (RAG) to enable users to upload documents, ask questions, receive context-aware responses and power agentic workflows. This guide will help you understand its core functionality, use cases, and workflows, as well as provide insights into optimizing its performance.
What is Pinecone Assistant?
Pinecone Assistant is an API service that securely generates accurate, grounded insights from your proprietary data. Pinecone Assistant makes this possible by providing a simple flow that allows you as a developer to:
- Upload documents
- Ask questions about those documents
- Receive context snippets, or AI-generated responses, that reference the uploaded documents
Key features and capabilities:
- Supports various file types as input (PDF, JSON, Markdown, Text, docx)
- Handles document chunking, embedding, vector index management, and storage automatically
- Allows metadata tagging for better filtering and answer relevance
- Produces grounded responses where generated text have specific citations
- Can produce output in a variety of formats - human readable chat, JSON, or structured snippets of the underlying documents.
The workflow consists of two core flows — one where you manage assistants and upload the files you want Assistant to manage, and the other where you Query assistants with end user queries whose responses are integrated into downstream applications.
Document Path:
- Creating an assistant
- Uploading documents
Query Path:
- Chatting with the assistant
- Optimizing performance through custom instructions
- Retrieving context snippets for transparency
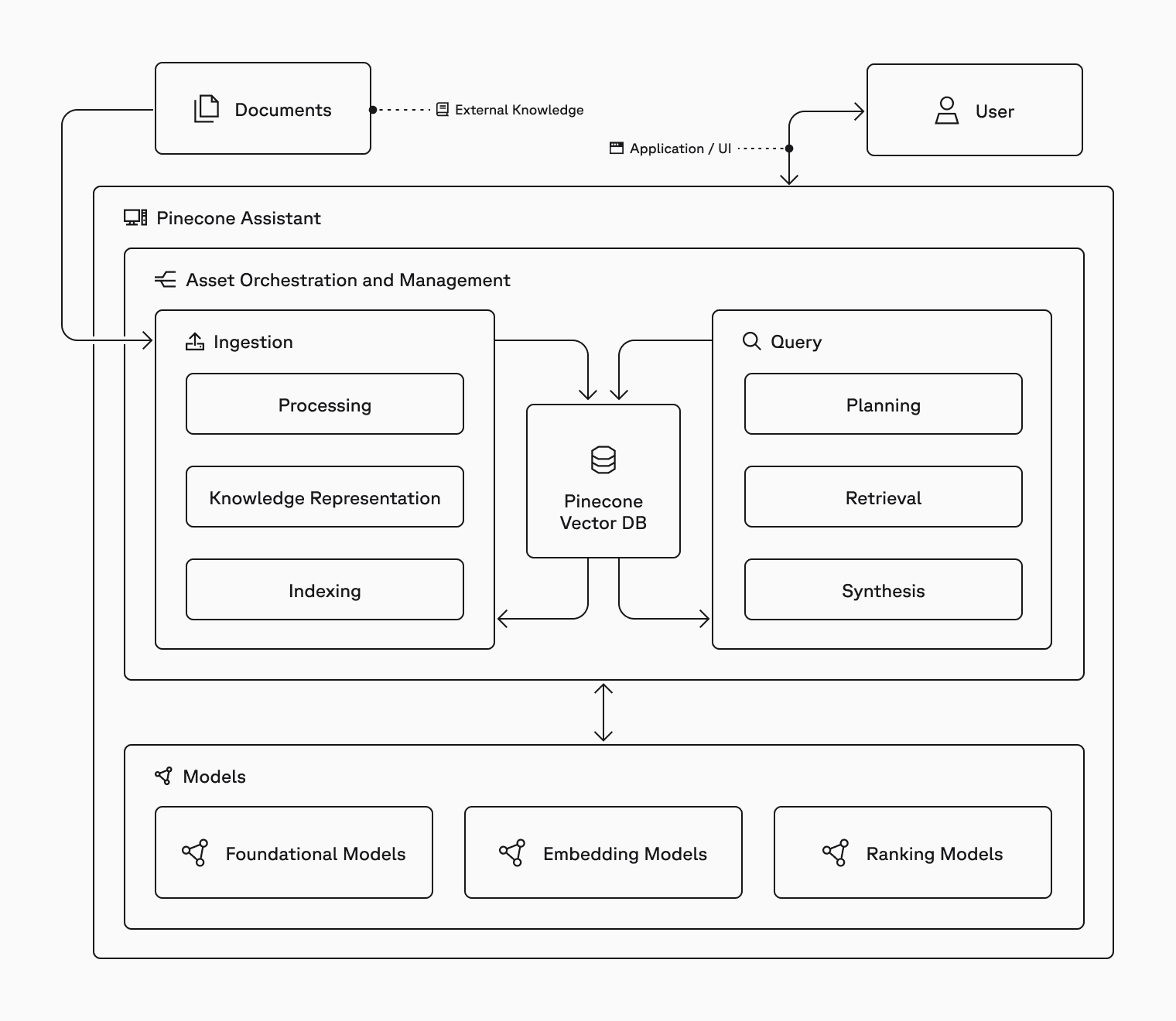
Files are stored in Google Cloud Storage (GCS) and the organization's Pinecone vector database, with metadata support for filtering, organization and improving relevance. The system measures usage in tokens. For Chat API, this will be Assistant Input and Output tokens for generation, retrieval and planning. If you use the Context API, the usage is measured in Context Processed tokens which cover all planning and retrieval.
Pinecone Assistant is designed to power chat and agentic applications, and makes building easier in a few key ways:
- Quick time to value: Quickly create, test and deploy chat based AI assistants; quickly provide knowledge and context to an agentic workflow.
- Always grounded AI applications: Provide accurate, referenced, context-aware answers on private, secure data without requiring fine-tuning of large language models or large context windows.
- Easy customization: A series of interfaces geared towards different applications, metadata filtering for relevance, custom instructions and region selection allow you to customize your assistant to your domain or application.
Uploading documents
The document upload path allows you to take raw documents and create an Assistant from them in one step. The assistant handles everything from processing the documents (e.g. extracting meaningful text and tables from PDFs) to breaking down markdown and JSON files for processing. The assistant then breaks down the processed documents into chunks, enriching each chunk with additional information to improve retrieval performance.
The documents and chunks are turned into an Assistant knowledge representation that captures the relationship between the original document and all its processed components. This is key to being able to reconstruct the most relevant parts of the document at query time. The chunks are then embedded into vectors, and uploaded to a Pinecone Serverless index.
As a user, you can specify metadata for each file that is uploaded that you can use a criteria to filter at query time, or as additional information you can use in downstream systems in production.
Example:
pip install --upgrade pinecone pinecone-plugin-assistant
// If you're using Jupyter Notebook do
!pip install --upgrade pinecone pinecone-plugin-assistantEasily create an Assistant and upload your files. You can download the file used in this example or run the below command.
wget -O dji_mini_2_user_manual.pdf https://dl.djicdn.com/downloads/DJI_Mini_2/20210630/DJI_Mini_2_User_Manual-EN.pdfFirst, we’ll create our Assistant:
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
assistant_name = "learn-assistant"
# Create a new assistant, but first check it does not already exist
assistants_list = pc.assistant.list_assistants()
if assistant_name not in [a.name for a in assistants_list]:
assistant = pc.assistant.create_assistant(assistant_name, timeout=30)
else:
assistant = pc.assistant.Assistant(assistant_name=assistant_name)Now let’s upload our document. Note: Assistant does not validate that file names are unique, as many automated processes and folder structures result in duplicate filenames (e.g. report.pdf). Instead, Assistant internally assigns a different id for every file uploaded.
file_name = "dji_mini_2_user_manual.pdf"
if file_name not in assistant.list_files():
response = assistant.upload_file(file_path=file_name, metadata={"type":"manual"})While uploading, we added metadata for this file. Metadata can help us focus and pre-filter results for Assistant, improving relevance. For example, metadata could be used to filter assistant results to specific categories, dates, or verticals. See Metadata section below.
We can see the unique ID assigned for this file by just accessing response.id.
Querying an Assistant
Each Assistant maps directly to the files uploaded to it - each time you query an Assistant, you are asking questions of the underlying knowledge, filtered by the metadata.
The query path at the highest level has the following steps: planning the query, executing the query, reranking the results, synthesizing the context and generating a response.
In planning the query, the Assistant takes the provided query and develops a plan on how to answer the question. This typically involves breaking the query down into a series of smaller queries in the form of more direct questions. Direct questions improve the performance of retrieval and make it easier to verify that questions were answered.
Post retrieval, the retrieved results are reranked to ensure the maximize relevance, and the Assistant knowledge object is used to then expand the ranked results with additional relevance context.
Depending on the API and parameters you have used, either these snippets are returned or an answer is generated. There are a few different options available to you: chat, chat completions and context.
Chat API
Chat API is the best way to use the Assistant to create generated, grounded text. The chat API returns a message, associated citations, and specific information showing which citations are related to which snippets of text.
One of the key advantages of using the Assistant API for generating answers is the power of grounding and citations. To learn more about how citations are developed, please see our technical deep dive.
Example:
msgs = [
{"role": "user", "content": "What is the maximum speed of the DJI mini 2?"}
]
resp = assistant.chat(messages=msgs)
# To get the response:
print(resp.message.content) # The maximum speed of the DJI Mini 2 is 16 m/s in Sport Mode.
# To continue the conversation (like with a chatbot) we can append the response and add more user queries
msgs.append(resp.message.to_dict())
msgs.append(
{"role": "user", "content": "And what is the battery capacity?"}
)
resp = assistant.chat(messages=msgs)
print(resp.message.content) #The DJI Mini 2 Intelligent Flight Battery has a capacity of 2250 mAh.Context API
Context API gives you the power of the ingestion, knowledge representation and query planning of Assistant but gives you control over how you can use the context snippets retrieved by Assistant. Where Chat API will use the retrieved snippets to generate a natural language answer with citations, Context API will give you the snippets in a structured format that you can use in a variety of different ways.
Context snippets can be used to generate an answer using a prompt and LLM of your choice, or they could be used as an input to an agentic system for further processing, or combined with other data sources as part of a broader information retrieval synthesis. The purpose of Context API is to provide this flexibility.
Example:
The most simple use for context API is to use a query input, that means that Assistant can be used as a simple context generation tool on a per-query basis. Using the same Assistant we created before:
resp = assistant.context(query="describe preflight checks for DJI mini 2")Now we can reconstruct the context for our LLM or agent. For example, let’s filter all the context objects with relevancy scores larger than 0.9. Note: the relevancy score is a measure that can change given a different query.
context_obj = []
for snippet in resp.snippets:
if snippet.score > 0.9:
context_obj.append({"context_snippet": snippet.content, "score": snippet.score})You can use Assistant and Context API to provide useful context to any LLM based system. The example below could be embedded into an agentic workflow, as a tool or or as a retrieval call that is combined with other data or processed further.
Chat Completions API
The Chat Completions API is a version of the Chat API that returns generated responses in a format that is generally compatible with OpenAI chat completion endpoints. Use chat completions to quickly experiment substituting an Assistant for an existing chat service.
Example:
Let’s demonstrate how chat completion can provide compatibility with OpenAI endpoints. We released Assistant Chat Completion API to support ecosystem of integrations, chat UI templates and more.
First let’s copy the base URL for our Assistant on our Assistant Playground in the console:
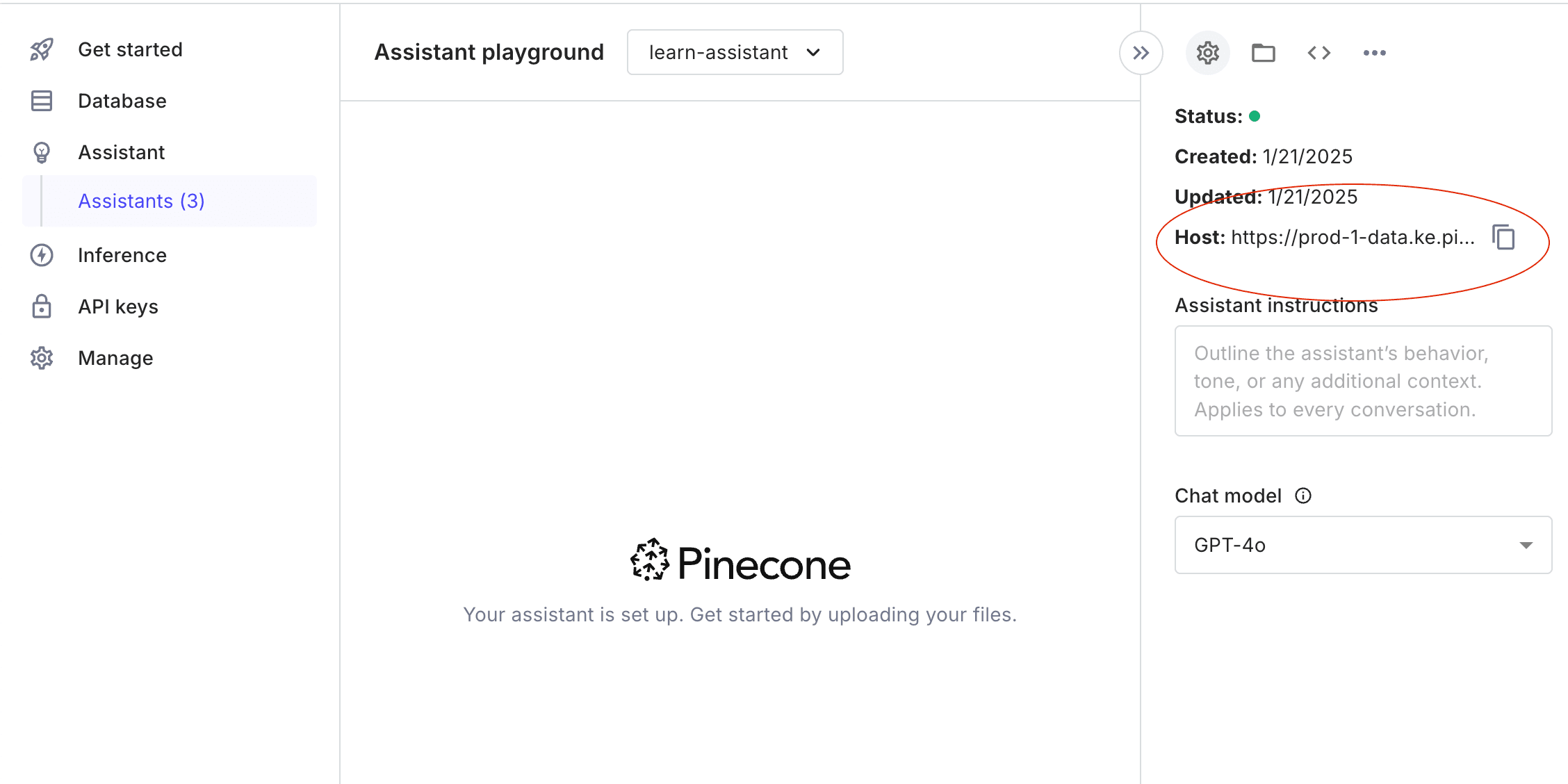
Now we can use code written to work with OpenAI, with only one single code change:
assistant_name = "learn-assistant" # Same Assistant that we created before
host = "https://prod-1-data.ke.pinecone.io" # This is what you copied from Assistant Console
base_url = f"{host}/assistant/chat/{assistant_name}"
from openai import OpenAI
oai_client = OpenAI(api_key=YOUR_API_KEY, base_url=base_url)
msg = {
"role": "user",
"content": "What is the maximum speed of the DJI mini 2?"
}
resp = oai_client.chat.completions.create(
model="gpt-4o",
messages=[msg]
)
print(resp.choices[0].message.content)
# This will print response and inline citations:
# The maximum speed of the DJI Mini 2 is 16 m/s in Sport Mode [1, pp. 12, 46]... Note: the response will include a reference section in Markdown format. We recommended you render this as markdown or a structured output for more flexibility than the Chat API directly.
from IPython.display import Markdown, display
display(Markdown(resp.choices[0].message.content))
APIs at a glance:
| Chat API | Context API | Chat Completions API | Evaluation API | |
|---|---|---|---|---|
| What it does | Generates responses to user provided queries in structured formats with citations | Provides retrieved context snippets for user provided queries with sources | Generates a grounded response via a chat completions compatible interface | Compute scores to quantify the completeness and correctness of generated responses. |
| When to use it | Best for Chat based applications or agentic applications that want generated JSON | Agentic applications or other applications or other compound/programmatic systems | A quick switch from an existing chat completions endpoint | When you want to evaluate generated answers vs. ground truth |
Customizing your Assistant
Instructions
Custom instructions in Pinecone Assistant allow you to significantly tailor the assistant's responses by defining its role, tone, and focus — effectively acting as the system prompt. For example, instructing the assistant to act as a legal expert will generate authoritative, law-focused answers, while setting it as a customer support agent ensures responses are geared toward troubleshooting and user assistance.
Custom instructions can also dictate the communication style—formal or conversational—and prioritize specific content or policies, such as compliance with industry regulations. By customizing these parameters, you can substantially differentiate the assistant's behavior, ensuring it provides highly relevant and appropriate information for specific use cases.
Some examples use cases for custom instructions include:
- Define Role: Set as subject matter expert or customer support agent.
- Focus Content: Adhere to regulations and company policies.
- Customize Format: Use structured outputs and adjust detail level.
- Set Guidelines: Ensure cultural sensitivity and mitigate bias.
- Set Limitations: Apply content filters and control response length.
- Handle Queries: Ask for clarification and maintain conversation context
Example:
Custom instructions can be used to guide the generated answers:
| Succinctness | “Answer directly and succinctly. Do not provide any additional information.” |
|---|---|
| Focus on topic or aspect of the response | “Summarize key risks to the business, including financial, operational, regulatory, and competitive risks. Where applicable, briefly explain the company's risk mitigation strategies to provide context on how these risks are managed.” |
| Structure or format | “Format every answer you give as a numbered list. Each item on the list should be one sentence long.” |
Metadata
Pinecone Assistant's use of file metadata significantly improves its ability to deliver accurate and relevant responses in real-world scenarios. By attaching metadata like topic, date, author, language, or access level to files, the assistant can more effectively filter and prioritize information.
This approach enables:
- Scoped retrieval: Instead of retrieving all files the assistant has access to, we can limit our search only to include a subset of these files. This can enable categorical filtering, numerical range filtering, boolean filtering and more. Read more about filtering with metadata.
- Role-based access control for sensitive information: We can leverage the filtering mechanism to limit the answers provided by the assistant based on user roles or other user attributes.
Example: For this example, we’ll create some short ‘files’ to clearly demonstrate how metadata can be used. We’ll create 5 files with some NYC Jazz history facts.
import json
from datetime import datetime, timedelta
# We're creating 'files' for this example that capture Jazz club facts
jazz_facts = {
"file1.txt": """The Village Vanguard, opened in 1935, is NYC's longest-running jazz club.
John Coltrane recorded his famous 'Live at the Village Vanguard' album here in 1961.
The club's distinctive triangular shape and exceptional acoustics have made it a favorite among musicians.""",
"file2.txt": """Minton's Playhouse in Harlem, established in 1938, is known as the birthplace of bebop.
Musicians like Dizzy Gillespie, Charlie Parker, and Thelonious Monk developed the revolutionary jazz style during late-night jam sessions.
The club's house pianist, Thelonious Monk, experimented with revolutionary harmonic ideas that would define modern jazz.""",
"file3.txt": """Birdland, named after Charlie "Bird" Parker, opened in 1949.
Count Basie's band was the house band at Birdland for many years.
The club was so popular that George Shearing and Sarah Vaughan recorded "Lullaby of Birdland" in its honor.""",
"file4.txt": """The Blue Note, established in 1981, brought jazz back to Greenwich Village.
Oscar Peterson, Dizzy Gillespie, and Sarah Vaughan have all performed on its stage.
The club's intimate setting allows audiences to sit just feet away from legendary performers.""",
"file5.txt": """Small's Jazz Club, opened in 1994, became famous for its all-night jam sessions.
The club helped launch the careers of many young jazz musicians in the 1990s.
It was known for having some of the most affordable cover charges in NYC, making jazz accessible to everyone."""
}
# Generate files and create the file list structure
files = []
base_date = datetime(2025, 1, 20) # Starting from January 20, 2025
# Create each file and add to the list
for i in range(1, 6):
filename = f"file{i}.txt"
# Write content to file
with open(filename, 'w') as f:
f.write(jazz_facts[filename])
# Calculate date (going backward from base_date)
file_date = base_date - timedelta(days=(i-1))
date_str = file_date.strftime("%Y%m%d")
# Add to files list
files.append({
"path": filename,
"metadata": {"date": date_str}
})Now we can load them into Assistant and use the metadata to filter at query time:
# Let's upload all the files
for file in files:
assistant.upload_file(
file_path=file["path"],
timeout=None,
metadata=file["metadata"]
)
# Now let's query without metadata, this will not filter
r = assistant.chat(
messages=[{"role": "user", "content": "Why is the club 'Birdland' called this way?"}]
)
print(r.message.content)
#"The club 'Birdland' is named after the famous jazz saxophonist Charlie "Bird" Parker."
# Now let's add metadata
r = assistant.chat(
messages=[{"role": "user", "content": "Why is the club 'Birdland' called this way?"}],
filter={"date": {"$gt": 20250118}}
)
print(r.message.content)
# "Based on the available information, I do not know why the club 'Birdland' is called this way" JSON output mode
JSON output mode instructs the Assistant to generate valid JSON as the message component of the Chat API, enabling you to use Assistant to provide structured, generated, output to other systems. JSON mode allows you to take advantage of the Assistants generation capabilities as part of a more complex agentic or compound AI system.
Example: JSON output can be helpful for structuring data to use in compound systems, let’s list all the Jazz clubs we indexed with the year founded:
import json
# Using the assistant we created in the metadata example above
resp = assistant.chat(
messages=[{"role": "user", "content": """list all the Jazz club you have in your data use the list of jsons, example: {"clubs": [{"name":"name", "year_founded": "year"}]}"""}],
json_response=True
)
json.loads(resp.message.content)This will output the results as follows:
{'clubs': [{'name': 'The Village Vanguard', 'year_founded': '1935'},
{'name': "Small's Jazz Club", 'year_founded': '1994'},
{'name': 'The Blue Note', 'year_founded': '1981'},
{'name': 'Birdland', 'year_founded': '1949'},
{'name': "Minton's Playhouse", 'year_founded': '1938'}]}LLM choice
Using the Context API, you can use an LLM of your choice with Assistant, taking the retrieved context snippets from Assistant and combining them with a prompt and LLM of your choosing. The ChatAPI provides the built in choice of LLM with OpenAI’s GPT4o and Anthropic’s Claude Sonnet 3.5.
Bringing it all together
This notebook brings the above concepts together to demonstrate how you can use Assistant to quickly build the backend for a chat or agentic application. The code in the notebook can be embedded into an application/UI of your choice for immediate use.
Related docs
Was this article helpful?