Improving retrieval quality can be difficult when building vector search or retrieval augmented generation (RAG) at scale. Every increase in quality matters for a great user experience.
Using a reranker allows for further refinement of retrieved documents during search, increasing relevance to user queries.
In most cases, rerankers require only a few lines of code and a bit of latency in exchange for significantly more relevant results. And with Pinecone's new Rerank offering, it's as easy as one more API call.
In this article, we will delve into the mechanics of rerankers, demonstrate how to integrate Pinecone Rerank into your search and RAG workflows and discuss optimal strategies for applying rerankers to your applications.
What do Rerankers Do?
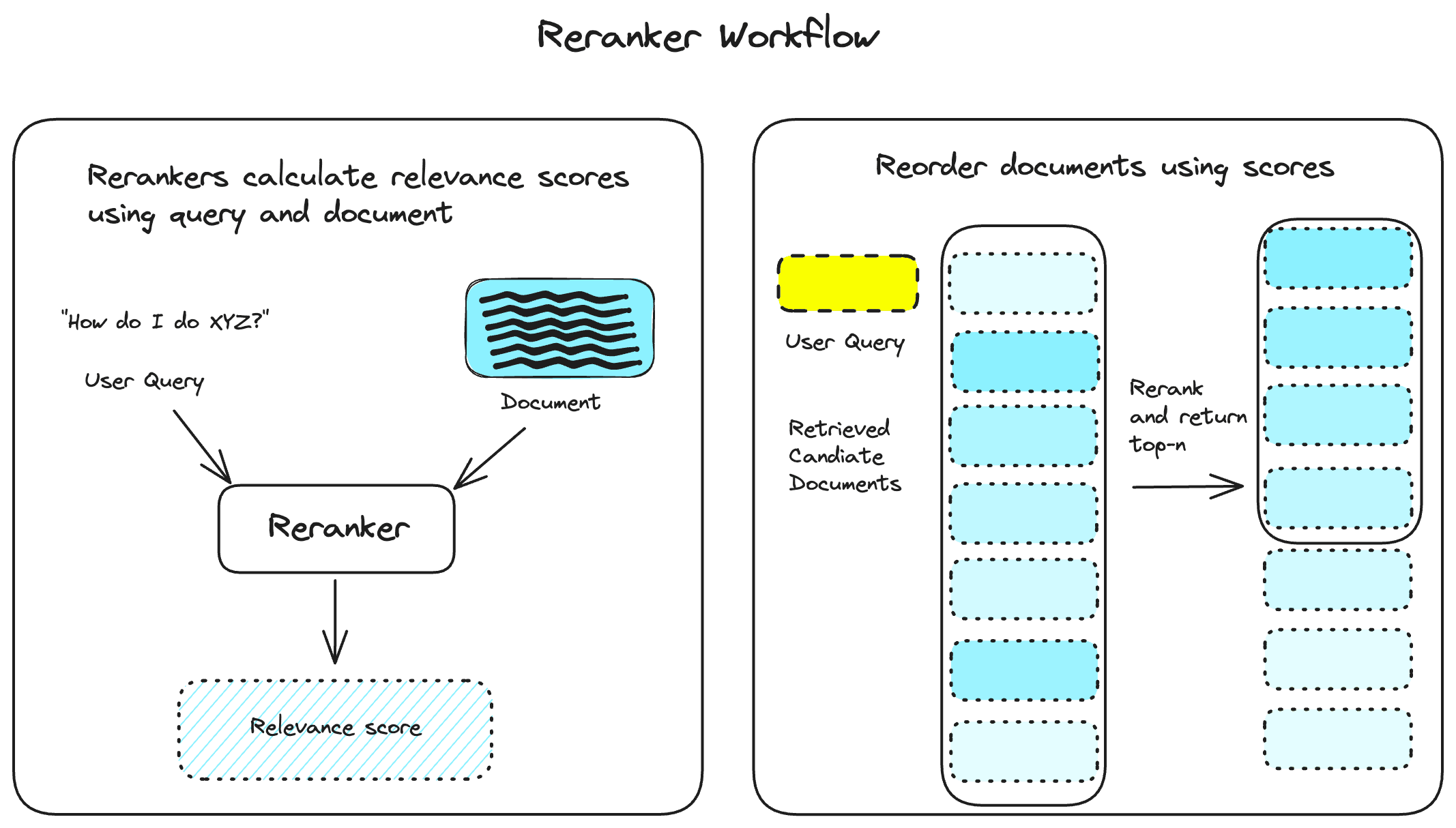
Rerankers refine the results you get from a vector database query. They do this by calculating relevance scores for each document based on how important it is to satisfy the user's query. That score is used to reorder the queried documents and return only the top-n results.
Usually, rerankers accept a larger than average number of documents and return the highly relevant subset of those.
Why use Rerankers at all?
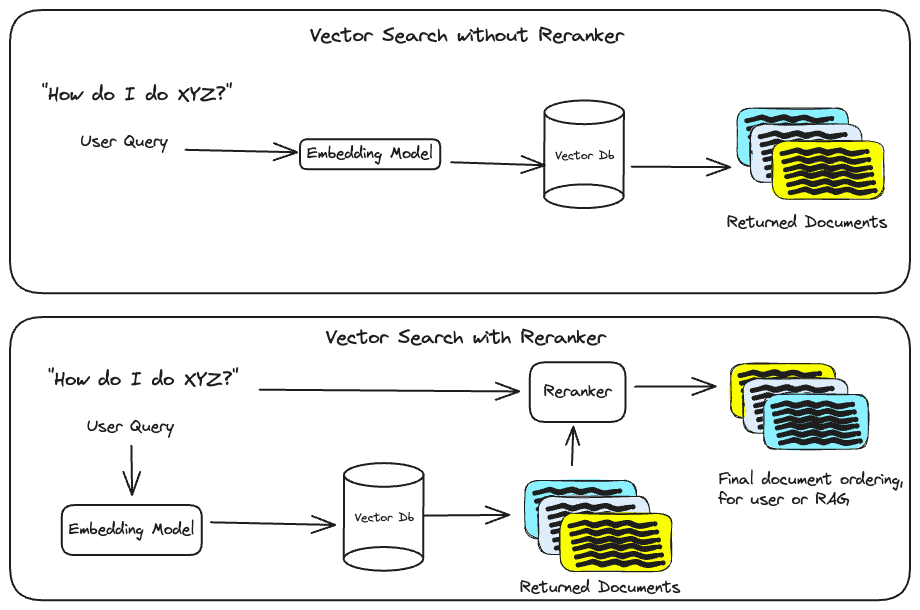
Adding a reranker to your vector search or RAG pipelines is an easy way to increase the quality of retrieved documents.
Using a reranker in your search pipeline has a few benefits:
- Increases Recall: When using the same number of returned documents, reranked results often contain more relevant documents than when using semantic search alone.
- Increases Precision: As relevance scoring happens during query time, it contextualizes the query and initial set of retrieved documents. This new ordering ensures the most relevant documents are prioritized.
- Improves User Experience: Having a tractable number of highly relevant results reduces the time to benefit from the search for the user, impacting churn/conversion metrics.
Rerankers may also be particularly important in specific industries, datasets, and applications.
Consider the benefit of rerankers in the following situations:
- Complex Documents:
- Datasets where relevant information is spread across multiple documents.
- Example: Legal research involving cross-referencing case laws and statutes.
- Recommendation Systems:
- Scenarios where the users are prompted to buy or click on things related and relevant to previous activity
- Example: Presenting product reviews where users typically only read a few relevant results before buying.
- Premium on Relevant Results:
- Essential for datasets where relevance is of utmost importance for search.
- Example: Healthcare organizations that prioritize correct and important information during searches.
These points compound at scale: every second counts for quickly satisfying user queries in domains such as e-commerce, customer support, and finance.
Optimizing RAG Context Windows with Rerankers
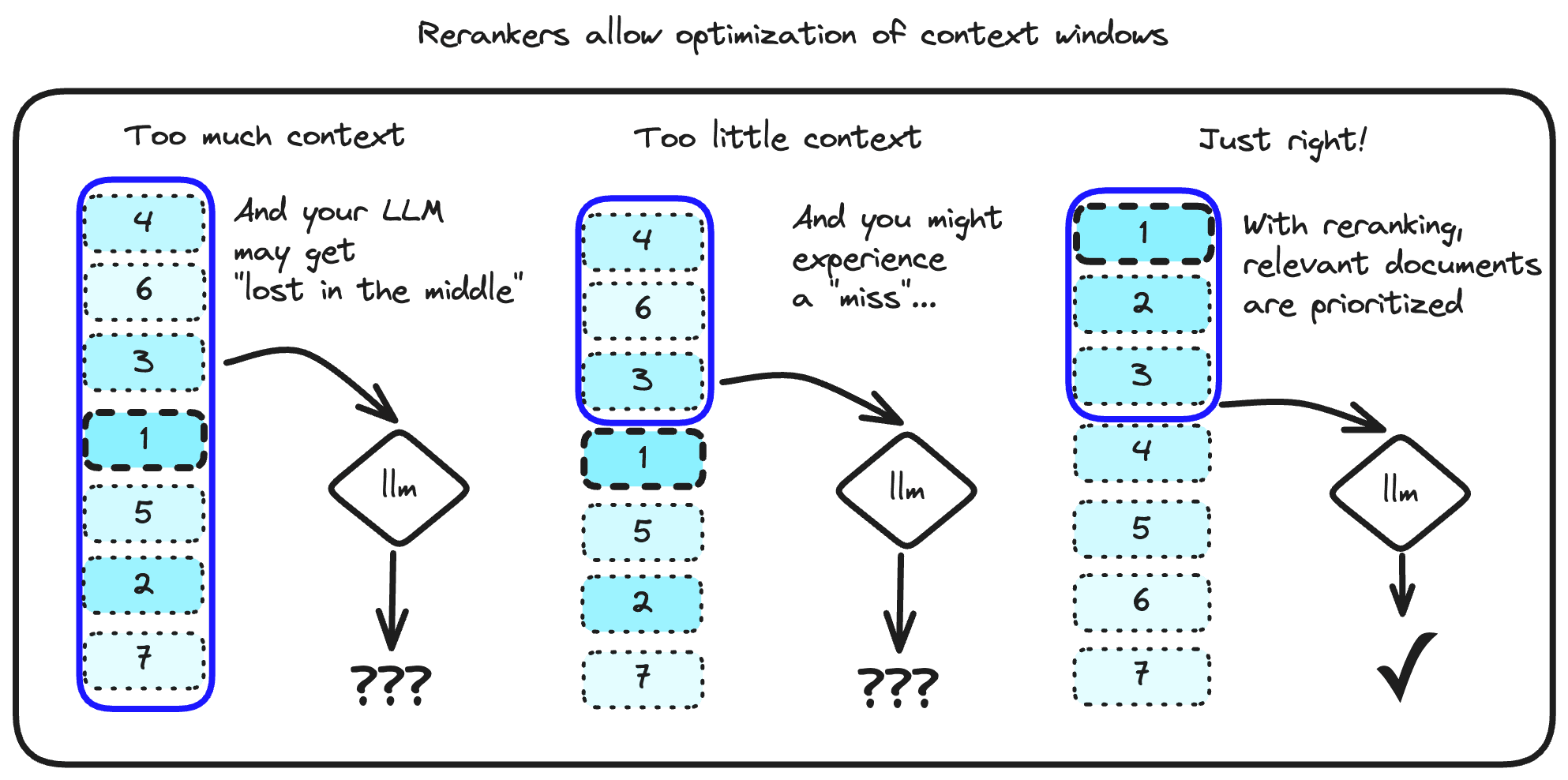
One of the goals of a great RAG application is finding the sweet spot of contextual information to generate the correct info.
Context windows determine how much information a generating LLM can use to create a response. As models are released with larger and larger context windows, it can be tempting to use them with as many documents as possible for better generation.
However, there is some evidence that LLM performance degrades when provided with too much information in context windows, which may even depend on where the information is provided. This is colloquially known as the “lost in the middle” result, when documents near the middle of the context window of LLMs are missed, resulting in erroneous output or hallucinations.[1, 2].
Although long-context LLMs help mitigate this, performance is still capped by the quality and quantity of documents passed to them [3]. Not to mention the increased costs of processing more tokens at ingest!
RAG pipelines benefit from a reranking step during document retrieval, which ensures the context window has the smallest number of highly relevant documents for use. Learn more about this tradeoff and others when building RAG pipelines in our guide here.
Using Pinecone Inference Rerank API
Through the Pinecone Inference API , you can access a reranking model for your vector search workflows using one API call:
from pinecone import Pinecone
pc = Pinecone("API-KEY")
rerank_results = pc.inference.rerank(
model="bge-reranker-v2-m3",
query="Tell me about the tech company known as Apple",
documents=[
"Apple is a popular fruit known for its sweetness and crisp texture.",
"Apple is known for its innovative products like the iPhone.",
"Many people enjoy eating apples as a healthy snack.",
"Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces.",
"An apple a day keeps the doctor away, as the saying goes.",
],
top_n=3,
return_documents=True,
)Pinecone Rerank uses the bge-reranker-v2-m3 model, a lightweight open-source and multilingual reranker.
There's no need to set up tokenization, hosting, other preprocessing pipelines, or even language-specific information: the endpoint handles it for you, much like using our hosted embedding model, multilingual-e5-large!
Integrate the Rerank API in your search workflows after querying your documents, allowing the reranker to return a smaller set of relevant documents for your pipeline.
Here's an example of stringing together an Inference embed, Query, and Rerank call:
query = "Tell me about the tech company known as Apple"
x = pc.inference.embed(
"multilingual-e5-large",
inputs=[query],
parameters={
"input_type": "query"
}
)
query_results = index.query(
namespace="ns1",
vector=x[0].values,
top_k=3,
include_values=False,
include_metadata=True
)
# Keep in mind to transform data for reranking
documents = [
{"id": x["id"], "text": x["metadata"]["text"]}
for x in query_results["matches"]
]
reranked_documents = pc.inference.rerank(
model="bge-reranker-v2-m3",
query=query,
documents=documents,
top_n=3,
return_documents=True,
)You can even query a larger-than-usual number of documents from your database and select a smaller top-n for the reranker to return.
What is BGE Reranker?
The BGE Reranker models are a multilingual reranker series of models from the Beijing Academy of Artificial Intelligence. The models were initialized from an XLM-RoBERTa model and further fine-tuned on multilingual retrieval data to optimize reranking performance within and across several languages.
For more details on how multilingual models are trained, check out our guide to multilingual e5 here. For preliminary information about model performance from the BAAI, refer to their GitHub here or on Hugging Face here.
We can understand how rerankers can refine retrieved documents through two distinct model development characteristics qualities: domain-specific training data and cross-encoding architecture.
Relevance Training Data for Rerankers
Much like any other large language model, rerankers require a large dataset to learn an internal representation of relevance.
Most datasets (like passage ranking for MS-MARCO) contain queries, relevant documents, and non-relevant documents. The labeling for these documents can be obtained from user behavior data or manually annotated by people [4].
Then, the reranking task can be seen as a binary classification task, where queries are aligned with relevant and non-relevant documents as positive and negative classes, respectively.
In fact, you can make a simple reranker using just the BERT embedding model and this framework, as demonstrated in this research paper [5].
For a deeper discussion on retrieval metrics involved in reranker training, refer to our blog posts covering various relevance metrics and information retrieval evaluation measures.
Reranker Architecture
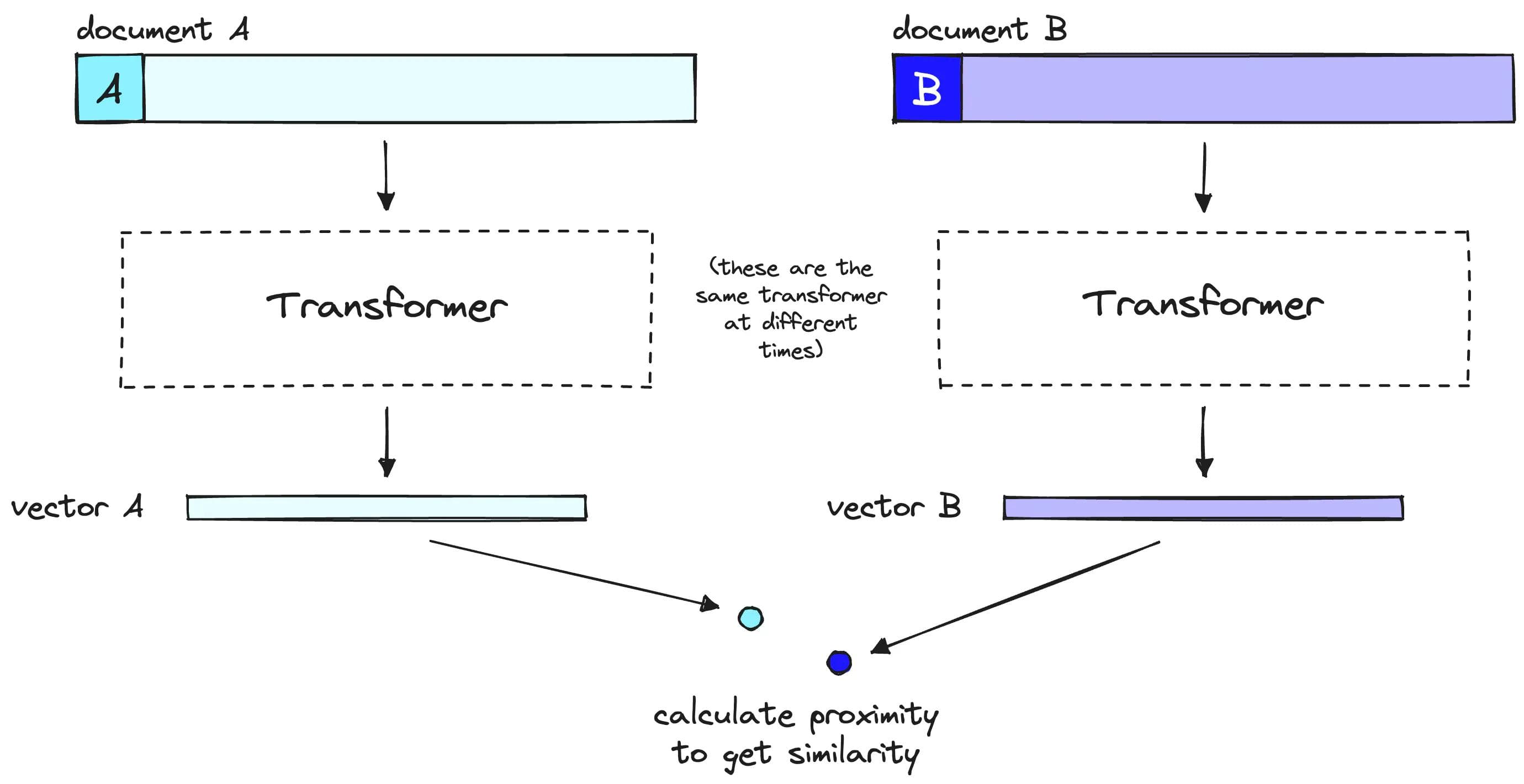
While embedding models can accept queries and documents independently, rerankers must input both the query and the document at the same time. This is because most rerankers are cross-encoders, which differ from the embed-and-compare architecture commonly associated with vector search.
Embedding models create high-quality representations of their inputs, while cross-encoders output scores when given two inputs. While embedding models do a fantastic job at this, quality inevitably degrades when cramming vast amounts of information into a fixed-size vector.
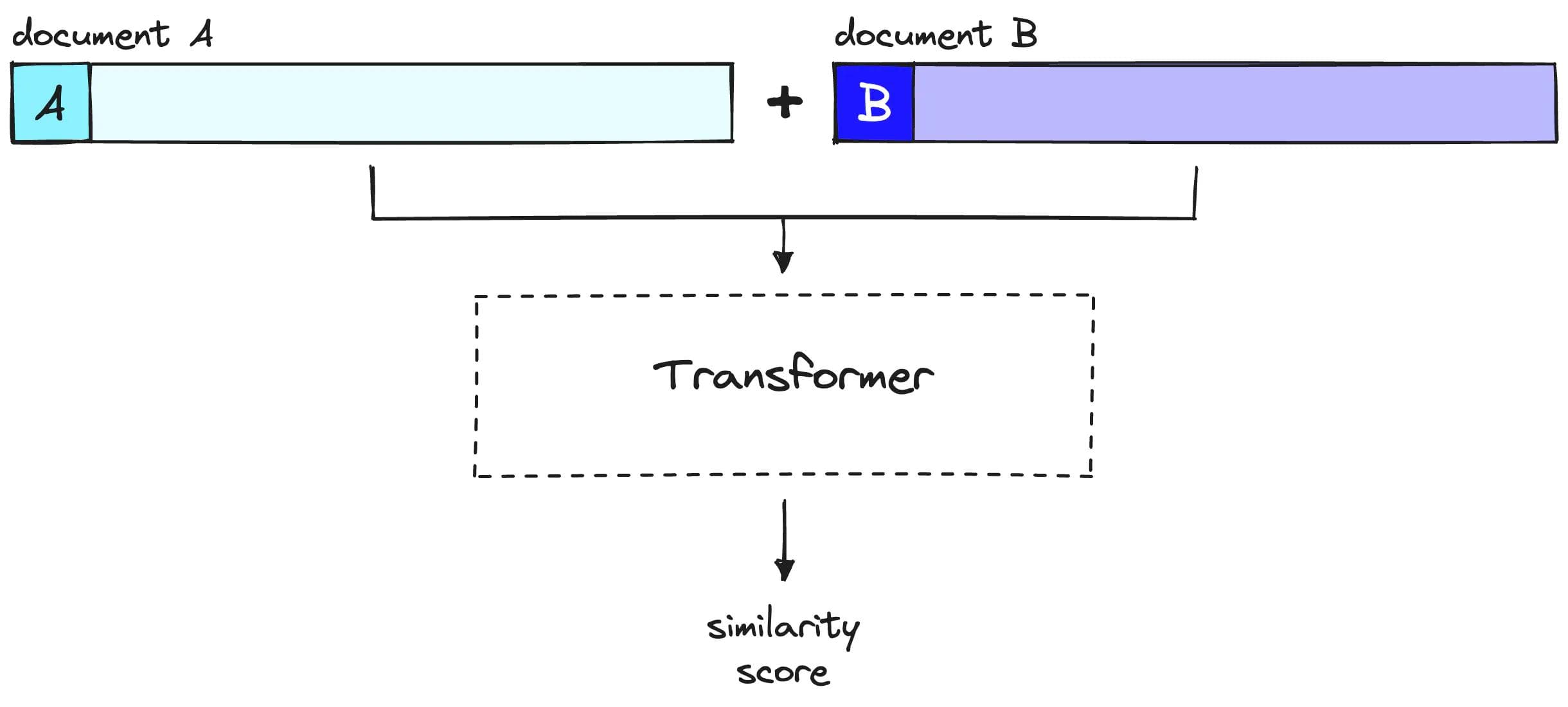
Cross encoding allows the model to make high-quality internal representations of the queries and documents and use those representations to quantify the metric in mind, in this case, relevance. By separating the task of finding relevance amongst queries and documents, the model can calculate a higher quality representation of this per query and document [1].
Rerank Best Practices
Keep Latency in Mind with Reranking
After learning about the refining benefits of rerankers for vector search, it may be tempting to assume that rerankers are a no-brainer to incorporate. However, rerankers come with a fundamental tradeoff: they can introduce significant latency.
Two main factors affect Rerank latency: document size in tokens and number of documents.
Recall that rerankers use a cross-encoder architecture. This means that every time documents are retrieved in response to a query, the reranker must calculate new relevance scores for each query-document pair. This computation cannot be easily saved as vector embeddings can in Pinecone.
Additionally, the latency will vary based on how large each document is. Because of this, we recommend experimenting with different values of top_n based on your latency and quality needs. Start with small values, such as top_k=10 and top_n=3, and iterate based on quality and latency for your application.
When using the Rerank endpoint, consider the following tips:
- Remember the following critical parameters for using Rerank: max query tokens of 256, max doc tokens of 1024, and a max of 100 documents
- Raise your retrieved top-k results from a standard of 3 to 5, to 10 or even 50, to allow for a deeper relevance search
- Record the relevance of documents for downstream users and RAG pipelines. Use this information to tweak your Rerank and query calls and measure how well the endpoint works in production
- Re-evaluate a set of in-domain search data at your organization with and without the reranker. Include measures that not only measure accuracy and relevance but also time for the user to act on the result to understand the overall effectiveness of the reranker
Using rerankers can be an easy way to increase the relevance of retrieved output from search queries with Pinecone. Incorporate the Pinecone Rerank into your pipelines today to refine your searches.
References
[1] J. Briggs, “Rerankers and two-stage retrieval” Pinecone, https://www.pinecone.io/learn/series/rag/rerankers/
[2] N. F. Liu et al., “Lost in the middle: How language models use long contexts | transactions of the Association for Computational Linguistics | MIT Press” MIT Press Direct, https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00638/119630/Lost-in-the-Middle-How-Language-Models-Use-Long
[3] Q. Leng, J. Portes, S. Havens, and M. Carbin, Long Context RAG Performance of LLMs”, Databricks, https://www.databricks.com/blog/long-context-rag-performance-llms
[4] P. Bajaj et al., “MS-Marco: A human generated machine reading comprehension dataset” a"”iv.org, https://arxiv.org/abs/1611.09268
[5] R. Nogueira and K. Cho, “Passage Re-ranking with BERT” arxiv.org, https://arxiv.org/abs/1901.04085
Was this article helpful?