Multi-Tenancy in Vector Databases
Note: If you're building mission-critical AI applications that require multi-tenancy, besides reading this guide you can also contact our solutions team for help.
Multi-tenancy is a software architecture pattern where a single instance of a system serves multiple customers, or tenants, simultaneously, with some form of data isolation ensuring privacy and security between tenants. Multi-tenancy enables you to share infrastructure and operational overhead across customers, reducing costs and simplifying system management. Nearly every SaaS app needs to design for multi-tenancy; it’s even relevant for some apps built for company-internal purposes.
Multi-tenancy is a common pattern, but it’s complex. You need to make sure that the system you design can scale effectively, maintaining high performance for all tenants — tenants that may have different workloads with different requirements and SLAs.
Let’s consider a fictional AI-assisted wiki product, SmartWiki. SmartWiki has 10s of millions of companies and individuals as their customers, each with a varying number of users (employees), scale of data (existing corpus, rate of new document creation), and SLAs provided to the customer by SmartWiki. SmartWiki pride themselves on their great UX, so query latency and other elements that affect customer perception of performance are paramount for all customers.
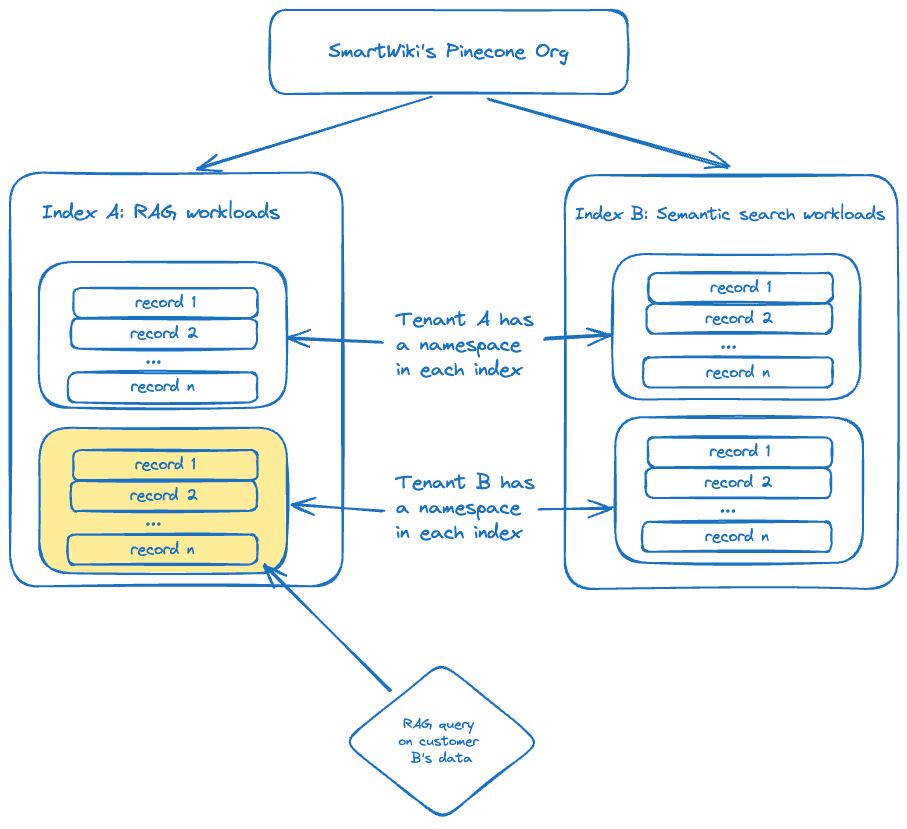
Luckily, SmartWiki can lean on Pinecone’s abstractions — indexes, namespaces, and metadata — to develop a multi-tenant system in a straightforward way. Pinecone serverless takes care of storing and accessing your tenant data efficiently, so you can design a consistent system and see the benefits without extra work.
Data isolation and efficient querying with namespaces
The most straightforward pattern for building a multi-tenant solution with Pinecone is by using one namespace per tenant. Namespaces allow you to physically partition records in an index. Queries and other operations are then limited to one namespace at a time.
That data isolation enhances query performance by isolating data into separate segments. Namespaces operate and scale independently - so if SmartWiki’s customer ACME is seeing a flurry of activity, queries and writes for Widgets'R'Us won’t run any slower.
Any query only interacts with one namespace, leading to faster response times and reduced costs. It also makes offboarding a tenant clean and simple– you simply need to delete the namespace.
Read more about serverless architecture.
You should prefer the namespaces pattern unless you require the ability to query across tenants.
All namespaces belong to exactly one index in Pinecone. SmartWiki might want to have different indexes that represent different workload patterns- let’s say for RAG and for semantic search. Then, within those indexes, data is namespaced to a specific tenant. Individual records (the group of vector + ID + associated metadata) belong to those namespaces. Then, when a query (or a write) comes in, it only hits a subset of SmartWiki’s data.
Real-world considerations for namespaces
Listen to our customer, Shortwave, talk about their namespacing strategy. Some of the things they suggest you consider:
- Do I need one namespace per user, per company, or some other division?
- How many documents do they have?
- How big are they?
Shortwave chose a strategy that worked for a case where they’re working with millions of emails, and needed strict separation between individual users– meaning the tenant is the individual user, which makes their setup look a bit different from SmartWiki’s.
In a design like this, you may need to allocate more namespaces than the index limit, we recommend setting up a mapping table between your tenants and the indexes their namespace can be found. On query time, you’ll first resolve the index based on the tenant, and then proceed to query the project, index and the appropriate namespace for the tenant.
Alternative: use metadata and ID prefixes when you need to query across tenants
In specific cases you may choose not to use namespaces to manage your tenants. For example, in an internal tool for a single company, you might have a slightly different definition of tenancy where it’s helpful to maintain some amount of separation for filtering or bulk actions like deletions, but you want to retain the flexibility to query your index across tenants. In that case, you can also manage tenants using a combination of metadata and ID prefixes.
Consider a RAG internal knowledge base chatbot for ACME co. They’re trying to create federated search via their chatbot across their 150 different SaaS products, each of which has individual user accounts for their employees. They want to be able to query across all data sources and all user accounts if needed (for a superuser or admin), but realistically, they will need to filter what gets shown to a given user– and when that user, or a piece of software they use, gets disconnected from the system, they need a clean way to remove them.
In this pattern, you would store vectors from all tenants in a single index. For any given vector, you would use an ID prefix to identify the user or data source for a given piece of information. You would also attach metadata that identifies the relevant tenant– user, data source.
At query time, you would apply filters based on metadata to show the right set of results. This approach separates tenants at the query level, allowing for “virtual” segmentation without the need for separate indexes for each tenant.
When it’s time to delete or offboard a tenant, you can list all the vectors associated with a ID prefix, then batch delete them.
Here’s how you can implement it:
- Add an ID prefix: At upsert time, assign a consistent ID prefix that identifies your tenant, e.g.
{"id": "tenantname#userID#vectorID"} - Assign Metadata: Alongside the prefix, assign metadata to each vector that identifies its tenant. For instance, you might use a key-value pair like
{"tenant_id": "tenantA"}for all vectors belonging to Tenant A. - Query with Metadata Filters: When querying the index, use metadata filters to retrieve only the vectors relevant to a specific tenant. For example, to retrieve vectors belonging to Tenant A, apply a filter that matches the
tenant_idmetadata totenantA.
This method allows querying across multiple tenants if needed, while keeping the tenants logically separated within the same index. It’s important to note, however, that tenants share compute and storage resources in this model, and you cannot track tenant-specific costs or provision tenants with different dimensions at the index level.
Tell us your tips
Namespaces are the most common, best-alternative choice for managing multi-tenancy in Pinecone– as Shortwave and others do.
What questions do you have, or what approaches have you taken? Come talk to us in the forum.