As a developer, you may only have the bandwidth to explore machine learning to the extend that it offers solutions to your present problems. For many developers, the present problem is vector similarity search. The solution is Pinecone.
Pinecone is a managed vector database that provides vector search (or “similarity search”) for developers with a straightforward API and usage-based pricing. (And it’s free to try.)
While it may be encouraging to hear that a SaaS solution exists for your data science needs, you still might feel lost. What is vector search? How or why would you use it? In this article, we’ll walk through everything you need to get started with vector search using Pinecone. Let’s go!
What is vector search?
If you’ve ever used a LIKE query in SQL, then you’ve performed a very simple form of vector search, though it’s unlikely that any ML theorist or practitioner would say as much. In reality though, vector search is fundamentally the same exercise.
When searching for similar text, there must be some kind of metric to check for overlap in the data. For text, this is simple: are the characters in the strings you’re searching over close to the ones you have in your search string? Depending on your background, you may have even heard technical terms like Hamming distance or Levenshtein distance, which are precise metrics for describing the similarity (or dissimilarity) of strings.
How does a vector search engine work?
For more complicated data sets, it’s also possible to make use of metrics like these. This is where vector based search shines, but how does it work?
In order to measure the distance between items in a particular data set, we need a programmatic way to quantify these things and their differences. Regardless of the types of objects we’re searching through, we use “vectors” or “vector embeddings” to convert the data we’re analyzing into simpler representations. Then, we check for similarity on those representations while still maintaining the deeper meaning of the objects themselves.
What are vector search embeddings?
At this point, we’ve defined an unfamiliar concept with an even more unfamiliar concept, but don’t be concerned. Vector embeddings are really just a simplified numerical representation of complex data, used to make it easier to run generic machine-learning algorithms on sets of that data. By taking real-world objects and translating them to vector embeddings — numerical representations — those numbers can be fed into machine learning algorithms to determine semantic similarity.
Vector search use cases
For example, let’s consider the phrase “one in a million.” Is this phrase more similar to “once in a lifetime” or more similar to “a million to one”? You might have some intuition about which pairing is more similar. By creating a vector embedding for each of these phrases, machine learning goes beyond human intuition to generate actual metrics to quantify that similarity.
If you’re thinking about how to get vector embeddings but coming from an SQL background, what might come to mind are aggregate functions which — if used correctly in cleverly crafted queries — could yield some sort of “all of this data boils down to a single number” result. At best, though, an SQL query can only perform really simple aggregations to distill out a final numerical representation.
Obtaining a vector embedding of real value requires some machine-learning techniques and a good understanding of the problem space.
Vector search examples
Image data, for example, is represented numerically based on the pixel values of each image. It already has the form of a vector embedding. But what about cases where obtaining a numerical representation isn’t so straightforward? Let’s consider some examples.
If we wanted to determine similarity across movies, we might look at people who had watched and rated the same movies, along with what other movies they had watched and rated. To find product similarity, we could look at customer purchases and see who has bought other items in the same purchase.
These examples are too complex and cumbersome to be handled manually. This data needs to be fed into some kind of neural network to reduce the number of dimensions of these vectors (length of the list of numbers). The following diagram shows how this reduction might work for simple object examples:
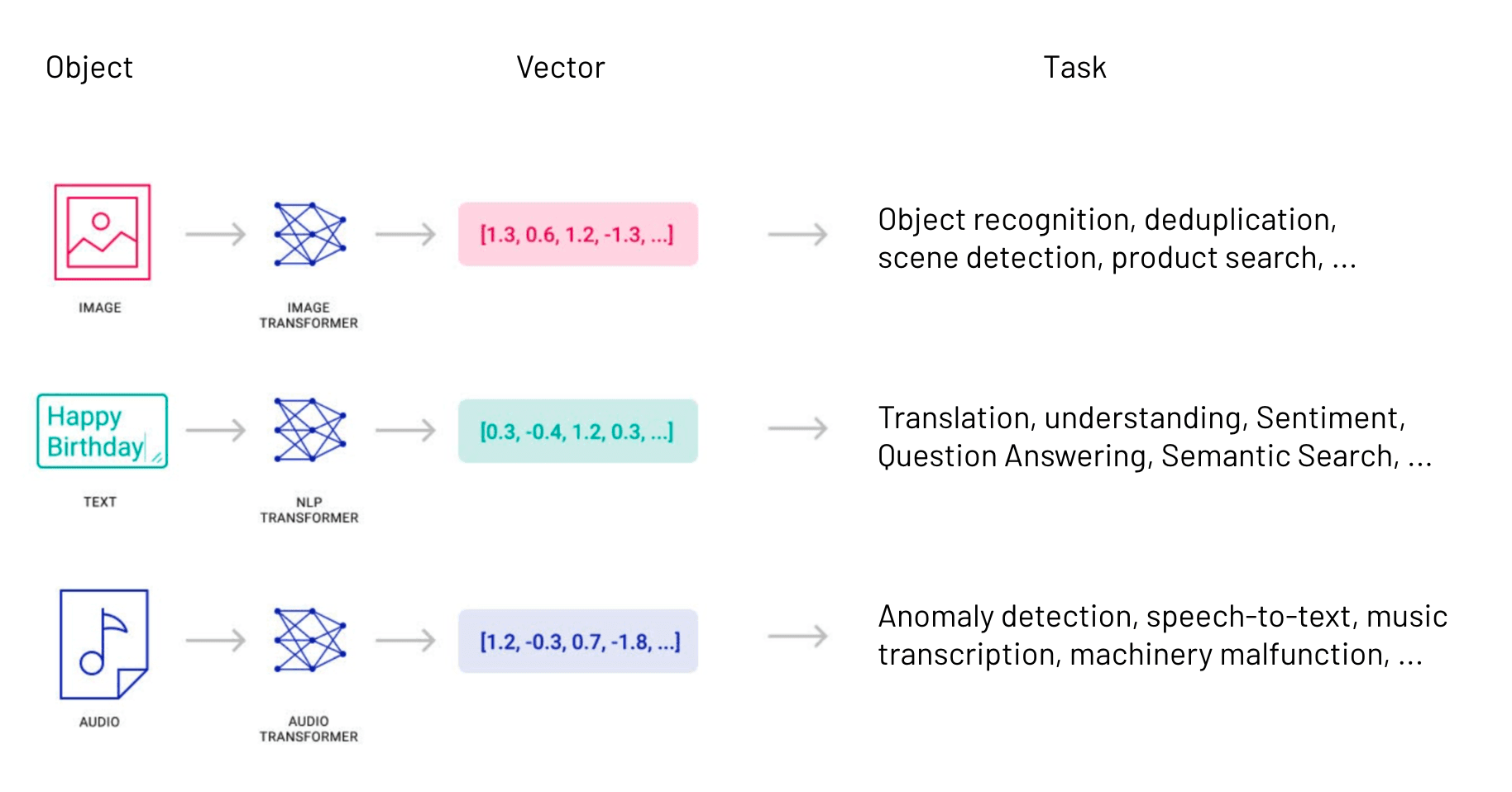
Depending on the data you’re working with, there may be existing models you can use. But if you’re working with a unique dataset or use case, you’ll need to put some time into ensuring your model will capture your data well. For more generic situations — such as text data — we can use a more widely available model like Word2vec. That model is trained against a wide collection of text data to determine similarities and differences between the concepts that real words represent.
Regardless of the model you’re using, though, Pinecone can help you search through the generated vector embeddings to find similar items.
What to do with your vector embeddings
Once you have a vector embedding, you need to be able to run queries against it. This is where Pinecone comes in. Rather than requiring you to learn all kinds of techniques for searching through your data, Pinecone provides managed vector search. You store vector embeddings with IDs that tie your data back to the objects they represent, allowing you to search through that data with a straightforward API and client. A store of vector embeddings and their IDs is called a “vector index.”
Creating a vector index is quite simple with Pinecone’s Python client:
import pinecone
pinecone.init(YOUR_API_KEY)
index = pinecone.create_index("my-new-index")(Java and Go clients are coming soon.)
You’ll need to get an API key and choose a name for your index. There are other parameters — such as the metric measuring similarity between vectors searching your data — but when you’re just starting, the defaults should be good enough.
Once you have an index created, you can insert your data as a tuple containing the id and vector representation of each object in your data set. Pinecone is blazing fast, able to index 10,000 tuples or more in just a second.
Querying an index is very simple. You can perform a unary query with a single vector, or you can query with a list of vectors too. All you need is a vector or a list of vectors you want to find similarities for and how many results (integer) you want Pinecone to return:
index.query(queries=vectors, top_k=integer)In the above line, top_k is a reference to the k-nearest neighbors to any given vector. If you’re not familiar with that algorithm, Pinecone’s usage is analogous to a LIMIT clause from SQL. All of the k-nearest neighbors analysis is taken care of by the platform! Pinecone will return IDs that match. It also returns a score that shows its confidence in the match.
Try Pinecone's managed vector search solutions
By now, you should have a better understanding of what vector search is and how Pinecone can help you integrate vector search into your application. If you’re interested in learning more, try out some techniques from our examples and start playing around with Pinecone and its vector search API yourself.
If you find you’re ready to get going with Pinecone on your own product, don’t hesitate to sign up or get in touch with us. We’ll be happy to help you get started!
Was this article helpful?