Making sense of complex, interconnected information is a major challenge across many fields. This article introduces a new AI approach that tackles this problem head-on. Enhancing how machines understand and explore data opens up new possibilities for insight discovery in areas ranging from legal analysis to scientific research. This article introduces a novel method that uses metadata-driven ontologies for more consistent graph construction, demonstrated through an exploration of Supreme Court case data.
How do AI systems reason?
AI reasoning continues to evolve, but the main challenge remains: how do we create systems that can reason precisely and flexibly?
The latest advances in the field, including Retrieval-Augmented Generation (RAG), are beginning to bridge this gap by combining structured knowledge retrieval with the generative power of LLMs - but the journey is far from over.
We continuously evolve how we think about how machines can simulate human intelligence. In the early days, reasoning was seen as a puzzle of logic and rules. AI systems were expert systems, where knowledge was neatly organized into ontologies—structured representations of facts and relationships - and conditional rules. For example, MYCIN, an early AI designed for medical diagnosis, applied “if-then” rules to navigate a web of diseases and treatments, leading to precise, explainable decisions.
However, these symbolic systems faced a challenge: they were only as good as the rules they were given. Real-world knowledge, unlike ontologies, is messy, uncertain, and constantly changing. These rigid systems couldn’t adapt to new or unexpected information. As AI attempted to scale beyond narrow domains, it became clear that reasoning couldn't be confined to strict logic.
The 1990s introduced another paradigm shift—probabilistic models. These systems embraced uncertainty, using statistics to make educated guesses rather than following rigid rules. Bayesian networks, for example, allowed AI to reason probabilistically about the likelihood of different outcomes based on incomplete information. This was a significant step forward. AI systems could now handle more ambiguity and learn from data, making them far more flexible than their symbolic predecessors.
But this flexibility came at a cost. Probabilistic models, while powerful, lacked the transparency of symbolic systems. Decisions became more complicated to trace and explain. The interpretability that came with expert systems—where every step of the reasoning process was visible—was sacrificed for the ability to generalize and scale.
Today, AI reasoning has continued to evolve with the advent of large language models (LLMs) like GPT-4, Llama 3, etc. These models seem to behave as if they reason, driven by patterns learned from huge amounts of data rather than explicit rules or probabilities.
LLMs generate responses that can be both incredibly detailed and contextually relevant, mimicking the flow of human conversation. Researchers have been split on whether or not LLMs represent a “true” understanding of the world or whether it just seems that way. Whether LLMs are truly capable of reasoning or not, they can effectively perform various tasks that were previously impossible or very hard to automate.
But while LLMs are powerful, they, too, have their drawbacks. Unlike earlier systems, they lack a structured knowledge base, making their reasoning opaque. They can generate convincing text, but without a solid grounding in facts, they are prone to hallucinations—producing information that sounds right but is factually incorrect. This black-box nature of LLMs highlights a fundamental tension in AI: the balance between interpretability and flexibility.
By retrieving relevant information from a knowledge base and providing it as context to the LLM, RAG addresses several fundamental limitations:
- Limited Knowledge: LLMs are constrained by their training data.
- Hallucinations: LLMs can generate plausible but incorrect information.
- Lack of Current Information: They can't access real-time or recently updated data.
Vector databases form the backbone of most RAG systems. They efficiently store and retrieve document embeddings and enable quick similarity searches to find relevant documents, crucial for providing accurate and up-to-date information to the LLM.
GraphRAG: A Step Forward
While RAG marked a significant advancement in AI systems' ability to access and utilize external knowledge, it's not without limitations. RAG is really good at finding relevant documents, but it often struggles to capture and leverage the intricate web of relationships between different pieces of information.
GraphRAG, a new concept that emerged in the industry following publications from researchers at companies such as Microsoft Research and Neo4j, aims to address these shortcomings by representing knowledge as a graph structure. The approaches to GraphRAG are evolving as well, and as this bleeding-edge field continues to progress, we are bound to see many types of implementations of the same concept.
In this post, we’ll juxtapose the LLM-centric approach (set forth by the Microsoft GraphRAG paper) and an approach that limits the reliance on the LLM during graph construction.
The LLM-centric GraphRAG Approach
GraphRAG builds upon the foundation of RAG by introducing a graph-based knowledge representation. This approach allows the system to:
- Represent knowledge as a graph: Instead of treating documents as isolated bags of words, GraphRAG captures entities and their relationships. This mimics how humans often think about and connect information.
- Enable multi-hop reasoning: GraphRAG can follow a chain of relationships to answer complex queries by representing knowledge as a graph. This allows for more sophisticated reasoning that goes beyond simple document retrieval.
- Provide more contextually relevant results: The graph structure allows the system to better understand the context of information, leading to more nuanced and relevant responses.
- Combine structured and unstructured data: GraphRAG can integrate traditional knowledge bases with unstructured text, creating a more comprehensive knowledge representation.
- Improve explainability: The graph structure makes it easier to trace the reasoning process, potentially improving the system's transparency and trustworthiness.
GraphRAG Use Cases
GraphRAG can be used for a variety of use cases, such as:
- Medical Diagnosis and Treatment Planning - GraphRAG could enhance medical diagnosis by representing relationships between symptoms, diseases, and treatments as a network. When a doctor inputs symptoms, it searches medical literature for relevant information. This combination of structured medical knowledge and intelligent retrieval could help doctors uncover complex diagnostic pathways, rare conditions, or unexpected treatment interactions that might otherwise be missed.
- Financial Fraud Detection - GraphRAG could model the financial ecosystem as a network of accounts, individuals, and transactions. When investigating potential fraud, it retrieves relevant records and patterns. By combining structured financial data representation with AI-driven query generation, analysts could trace fund flows, identify shell companies, or uncover coordinated fraudulent activities that might be hidden in traditional analysis.
- Supply Chain Optimization - GraphRAG could represent the network of suppliers, manufacturers, and distributors. When optimizing processes, it retrieves relevant supplier information and market trends. This approach could quickly identify bottlenecks, optimize routes, or find alternative suppliers during disruptions. Integrating structured supply chain representation with flexible analysis could provide insights for more resilient and efficient operations in complex global markets.
The Limitations of the LLM centric GraphRAG Approaches
While GraphRAG can be incredibly useful, it introduced its own set of challenges:
- LLM-Dependent Graph Construction: GraphRAG typically relies on the LLM to construct the knowledge graph. This approach can lead to:
- Inconsistencies in the graph structure
- Propagation of LLM biases or errors in the knowledge representation
- Lack of control over the ontology used to organize information
- Scalability Issues: As the graph grows, the complexity of queries and the computational resources required can increase significantly.
- Lack of Grounding in Structured Data: The graph construction process may not fully leverage existing structured data (like ontologies or metadata). When we cede the graph construction task to the LLM, we risk exploding the number of possible node and edge types to the point where it becomes hard to do multi-hop reasoning effectively.
These limitations require a more comprehensive, controlled knowledge representation and retrieval approach.
A path towards agentic graph exploration
Reasoning over data may take various forms. While RAG and GraphRAG are more focused on retrieval, we wanted to explore how vector and graph databases can be used in conjunction to allow for structured - and eventually automated - data exploration. The basic premise is this: using semantic search, we can limit filter a sub-graph and then generate graph queries to ask and answer contextually relevant questions. This iterative exploration process could be done either manually or agentically.
This approach differs from GraphRAG in several key ways, which we'll explore in this post. One crucial distinction is that unlike GraphRAG—which relies on an LLM for graph construction—we use the metadata inherent in the dataset itself (as well as other more “stable” sources for entities and relations). This metadata essentially forms the underlying ontological structure of our data, which is then reflected in the graph.
As we’ll show, we were able to effectively generate queries on this graph that were both contextually relevant and likely to resolve a helpful answer. This was primarily due to the constrained way we constructed the graph.
When guided by a well-defined ontology, the number of effective queries an LLM can generate increases despite—and indeed because of—the constraints imposed on entity and relationship types. Here are the main advantages of this approach:
- Focused Relevance: By constraining entity and relationship types, the LLM concentrates on meaningful, domain-specific connections, reducing irrelevant combinations.
- Enhanced Coherence: A defined ontology ensures consistent, interconnected queries that align with domain-specific knowledge structures.
- Efficient Exploration: The narrowed search space allows for deeper analysis of nuances, faster processing, and a higher proportion of insightful queries.
Not all datasets provide such rich metadata. In those cases, alternative methods for constructing and applying an ontology would be necessary. We'll explore these challenges in future posts, but for now, we're focusing on these metadata-driven methods (among others) to guide our graph construction.
Key Components
At its core, our work brings together four key components:
- Document Database (DDB): Serves as the foundation, storing raw, unstructured data - the actual content of documents, articles, or any other text-based information.
- Vector Database (VDB): Creates high-dimensional vector representations of documents, enabling semantic searches and finding conceptually similar content (The vector database relies on the use of an embedding model, of course)
- Graph Database (GDB): This type of database represents entities (like people, places, or other concepts) as nodes and the relationships between them as edges, allowing for complex queries about interconnected information.
- LLM - the LLM performs summarization and graph query generation. More on this later.
Let’s take a look at the flow diagram of the system:
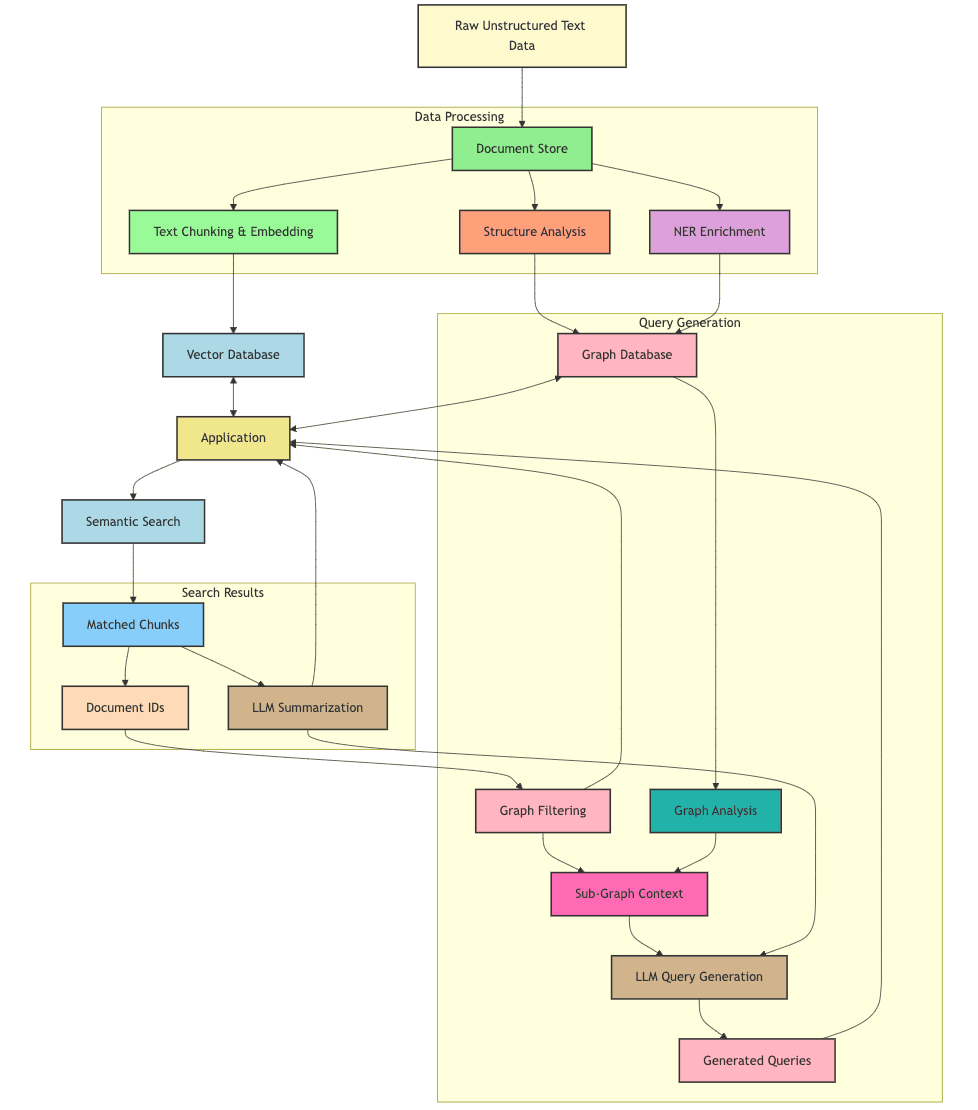
From Semantic Space to Graph Queries
Our workflow begins in semantic space, where raw, unstructured text data—documents, sentences, or paragraphs—exist in their natural form. The challenge is to transform this data into something structured and actionable, guided by domain-specific knowledge.
Our data takes two parallel routes, one that goes to the vector database, and the other goes to the graph database. Both begin in the document store, which contains both the raw semantic data as well as the metadata used to construct the graph.
- Structured Document to Graph: We begin by analyzing the documents' structure, inferring entities and relationships from them. This gives us the basic building blocks for the ontology for the dataset. We associate all the entities found in the document with a node representing the document itself.
- Graph enrichment with Named Entity Recognition (NER): In order to extract more structurally sound information from our raw data, we apply good-old-fashioned NER to extract the names of people, organizations, places etc from the text. As opposed to using an LLM for this task, the variety in the types of relationships created as part of this process is quite limited, which will come in handy later on.
- From Semantic Space to Embedding: In this step we’re transforming the raw text into high-dimensional vector representations, or embeddings. As with other RAG processes, we chunk our raw text data into smaller segments, and embed them. Each segment is then embedded, and saved in Pinecone with metadata that points back to its parent document. Crucially, the document ID used in this step matches the document ID used in the graph database.
- Semantic search for RAG: As done in other RAG applications, we use the retrieved matches as the context for the LLM to produce a summary that would relate to the initial query. This summarization process helps distill the key information from the retrieved chunks, providing a concise and relevant response to the user's query. The summary can also serve as a starting point for further exploration or more specific follow-up questions.
- Semantic search as Graph filtering: When users perform a query, we resolve chunks through similarity search. The system returns the document IDs associated with the matched chunks - and those correspond to the node IDs in our knowledge graph. Effectively, the semantic search filters the graphs to produce nodes and edges that would have some contextual relevance to the initial query.
- Looping Back with Graph Context: Armed with this structured graph context, the system loops back to the LLM. The LLM now uses this graph-informed perspective to generate more precise, contextually grounded queries. Rather than operating blindly, the LLM can craft queries that reflect the relationships and constraints defined by the graph, asking more nuanced and domain-relevant questions.
Demo use case: Exploring Supreme Court Cases
To demonstrate the practical application of our agentic graph exploration approach, we've developed an example centered around exploring Supreme Court cases. This demo showcases how our system can effectively navigate and extract insights from complex legal data, leveraging the power of semantic search, graph databases, and AI-driven query generation.
Our chosen domain of Supreme Court cases provides an ideal testing ground for several reasons:
- Rich interconnections between cases, justices, and legal concepts
- Structured metadata that naturally lends itself to graph representation
- Complex queries that benefit from both semantic understanding and graph traversal
In the following sections, we'll point out the specifics of how we processed this data and utilized our system to generate meaningful insights from it.
Data Processing Pipeline
Our pipeline begins by ingesting and processing the raw case data across three key components:
- Document Database (MongoDB): Serves as our primary archive for full text and metadata of each case.
- Vector Database (Pinecone): Enables semantic search capabilities through vector embeddings.
- Graph Database (Neo4j): Forms the foundation of our knowledge graph, capturing the complex relationships within the legal domain.
Here’s a detailed breakdown of the pipeline:
- The initial ingestion pipeline:
- Retrieves the raw data from the Oyez API
- Converts any retrieved HTML data into markdown
- Saves the data in the Document DB.
- We apply an ontology-driven approach, leveraging the metadata inherent in each
casein the document DB:- Key entities like
Case,Party,Justice, andAdvocateare defined (processing pipeline - cell 8) - Relationships such as
advocated_by,decided_by,won_byare derived from the data. (processing pipeline - cell 14)
- Key entities like
- To further enrich the data, we analyze each
opiniontext with “good-old-fashioned” NER usingflair(processing pipeline - cell 10). - All
entitiesandrelationsare saved asnodesandedgesin Neo4j. - Concurrently, we prepare for advanced semantic search:
- Breaking down the text of each opinion into manageable chunks.
- Transforming each chunk into a vector embedding to capture its semantic essence.
- Storing these embeddings in our vector database for future semantic queries.
(Document DB → Vector DB + GraphDB pipeline)
Query Generation Engine
With our knowledge graph and embeddings in place, we move to generating insightful queries from our data.
The process begins by gathering comprehensive context (see graphStatsQueries.ts) :
- Graph Statistics: Collecting detailed information about node counts, relationship types, and common properties to provide a macro view of the data landscape.
- Schema Information: Mapping out the graph structure, including node and relationship types.
Our query generator then leverages this context to generate Cypher queries (see cypherQuestionsPromptBuilder.ts):
- Natural Language Summary: Allowing input of specific areas of interest for targeted analysis.
- Zero shot learning examples: Providing the LLM with some concrete examples of how it should generate the queries. This helps the model prefer queries that leverage fuzzy matching, optional matches etc. Using this technique has improved the quality of queries significantly.
- Chain of thought prompt directions: We used the commonly used chain of thought prompts to focus the LLM on how to approach the problem, as a general way of improving the quality of the generated queries.
Demo
Summary
AI reasoning has undergone significant changes, each iteration grappling with the trade-offs between structure and flexibility. Our work on graph exploration represents a step towards reconciling these competing needs. By integrating semantic search, graph databases, and LLM-driven query generation, we've developed a system that can navigate complex datasets with both precision and contextual understanding.
Our Supreme Court case demonstration illustrates the potential of this approach in real-world applications, showing how metadata-driven ontologies can guide meaningful exploration of intricate domains. While challenges remain, this method opens up new avenues for AI-assisted knowledge discovery, potentially offering a bridge between the interpretability of structured systems and the adaptability of modern language models.
Was this article helpful?