Postgres to Pinecone Syncing
Introduction
A core part of many applications is a relational database - and in many AI applications it’s very common to use Pinecone alongside such a relational databases. PostgreSQL, commonly referred to as Postgres, is one of the most popular open-source relational databases. It is known for its robustness, scalability, and stability, making it a popular choice for many applications.
In order to facilitate the process of keeping a Postgres database in sync with your Pinecone index, we’ll make use of Airbyte’s Postgres source connector and the Pinecone destination connector. This integration streamlines the process of creating embeddings and simplifies the data pipeline, making it easier for you to focus on building you application.
The Pinecone Airbyte connector
The Pinecone Airbyte Connector is a data integration solution that allows you to easily connect multiple data sources. It leverages Airbyte's source connectors and Pinecone's capabilities to streamline the data integration process and enable seamless data flow across different systems. The connector is highly adaptable and flexible to various data needs, with no need for complex integration steps or on-premises deployment. The connector offers the ability to embed and upsert information, with specific column and metadata fields defined by the user. This enables greater flexibility and customization, making it easier to handle specific data integration needs.
Read about the basics of the Pinecone connector.
The scenario
For this example, consider an e-commerce website that allows users to search for products based on their description. To enable better results, the search functionality will leverage semantic search powered by Pinecone. The product data will be stored in a Postgres database. Our goal will be to enable this semantic search whenever a new product is created in the database - or when any of the products are updated.
We’re going to use a table with the following structure:
CREATE TABLE public.products (
id character varying(255) NOT NULL DEFAULT nextval('products_id_seq'::regclass),
name text NOT NULL, sku character varying(255) NULL,
description character varying(255) NULL,
price money NULL,
last_updated date NULL DEFAULT now()
);We load the table with a set of fictitious products found in this file. Here’s a sample:
| id | name | sku | description | price | last_update |
|---|---|---|---|---|---|
| 3d6ae001-ef80-4cbd-8e8e-5e296bbf80a6 | Pro System | SKU-fLRM-842 | This is a monetize user-centric markets product with Implemented local framework features. | $344.87 | 2023-09-20 22:51:32 |
| ee47e11c-e06b-4281-8531-4be90978549d | Lite Device | SKU-wxJp-879 | This is a iterate customized models product with User-centric zero-defect success features. | $845.00 | 2023-09-03 22:51:32 |
| 05d6f029-1ede-446d-ad07-855bdc55a02d | Ultra Controller | SKU-raQP-504 | This is a facilitate plug-and-play technologies product with Realigned regional product features. | $242.11 | 2023-09-09 22:51:32 |
We’ll set up a pipeline which will consume the data found in our products table in the Postgres database, and automatically generate and upsert embeddings for the description column. We’ll save the id of each product as metadata, so that we can reference the information once we retrieve the semantically relevant entries from Pinecone:
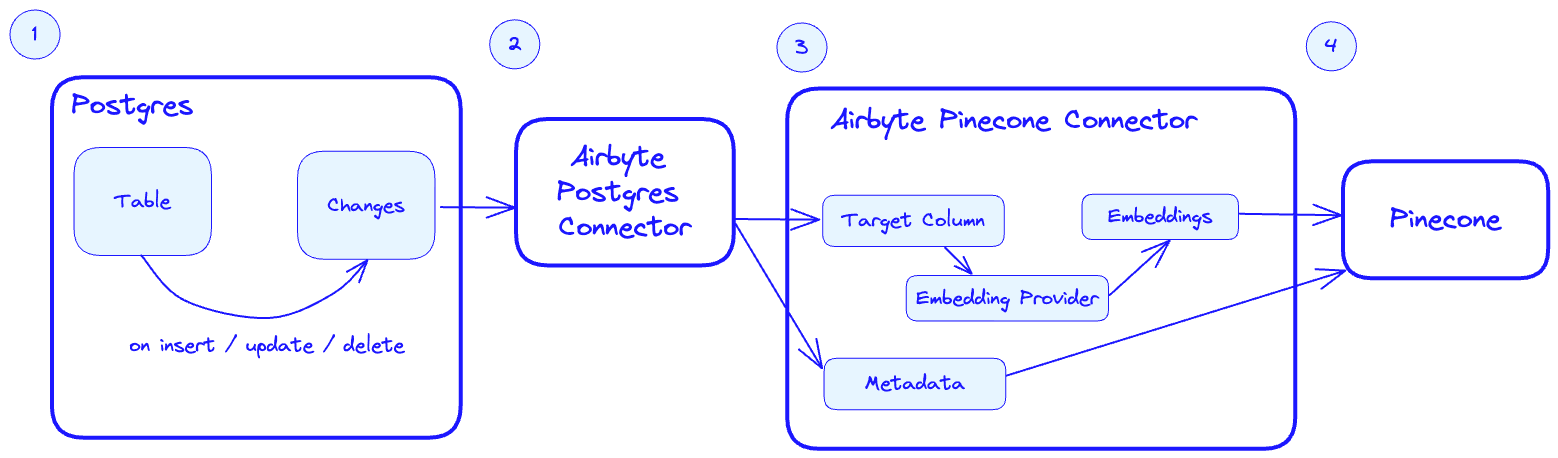
- Postgres tracks changes in the
productstable for any insert / update / delete event. - The Airbtye Postgres connector picks up the changes when it is triggered.
- When the Airbyte Pinecone connector is triggered, it takes the target column (on our case
descriptionand sends them to the configured embedding provider to produce embeddings. The metadata is also passed to the connector based on it’s configuration (more on configuring the connector later). - The embeddings and metadata are upserted into Pinecone.
Postgres Integration with Pinecone
In this portion of the guide, we’ll walk through the set up and replication options of using Postgres with Pinecone.
Setting up Postgres Integration with Pinecone
- Install and configure the Postgres Airbyte connector
- Connect to the Postgres database by providing the necessary details such as the host, port, database name, username, and password
- Configure the data replication settings, such as the tables to be synced, the frequency of syncing, and the data mapping
- Verify and test the data replication process to ensure that data is being synced accurately and efficiently
Postgres Connector Configuration
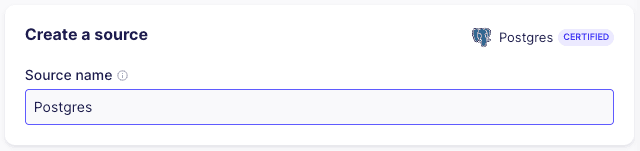
To set up the Postgres connector, start by adding a new Postgres “Source”.

Name the source Postgres - one connector may serve many connections.
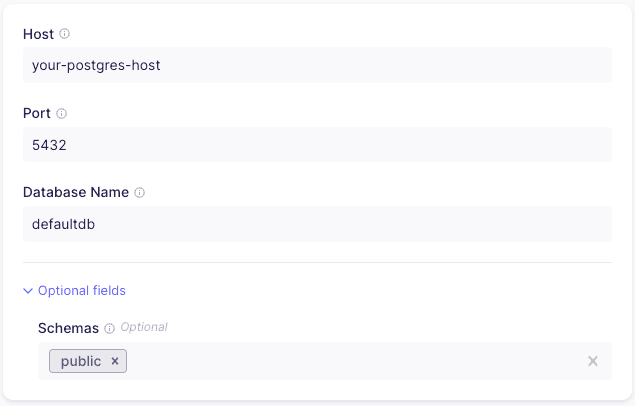
Next, provide the host, port and the database name for your Postgres instance. You may optionally provide a specific schema - although by default public should suffice.
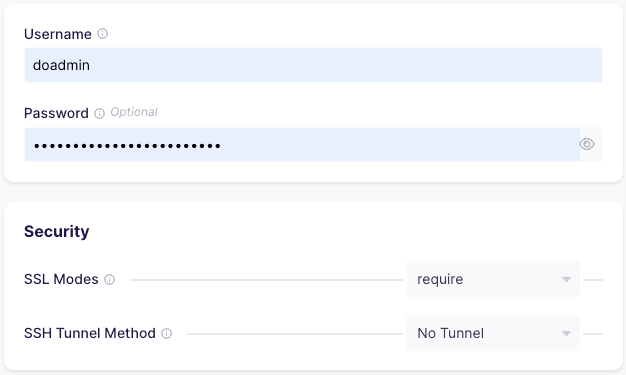
Provide the user name and password for your database. It’s advisable to create a user specific to the Airbyte connector. By default, the SSL mode is set to require - you should modify this if your database configuration differs. You can read more about connecting with SSL in the Postgres Airbyte Connector page.
As of the time of this writing, the Pinecone connector doesn’t support the CDC update method, so we’ll choose the second option, which will leverage the Xmin System Column.
Xmin replication is a cursor-less replication method for Postgres. Cursorless syncs enable syncing new or updated rows without explicitly choosing a cursor field. The xmin system column (available in all Postgres databases) is used to track inserts and updates to your source data.
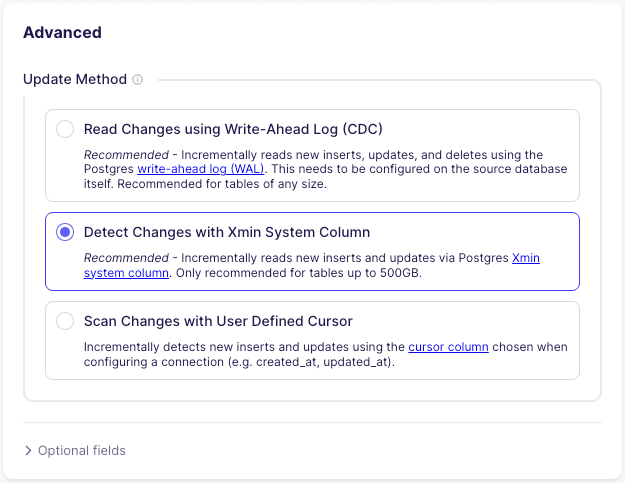
Finally, you’ll have to allow ingress to your Postgres database. You’ll find the list of IPs that must be whitelisted for the connector to work properly in the last section of the connector setup.

Pinecone Connector Configuration
We covered the basics of how the Pinecone connector works in the previous chapter, so we’ll just highlight the changes that are relevant for our setup. Since the Pinecone connector targets specific text fields for embeddings and metadata, we’ll have to create a separate connector that will handle the connection for our Postgres source.
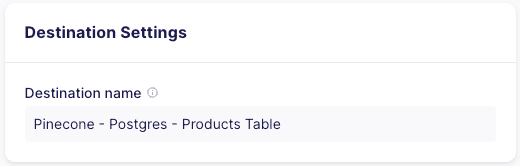
In the “Processing” section, set the metadata field to be stored to id and the text field to embed to description.
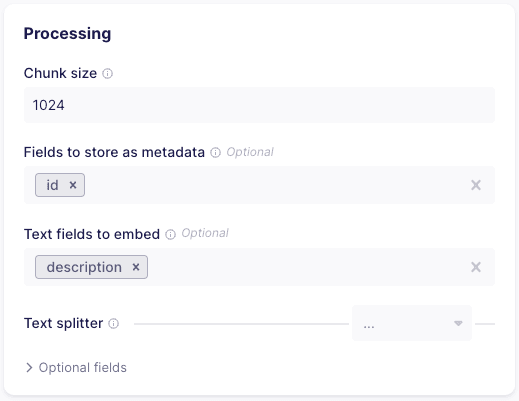
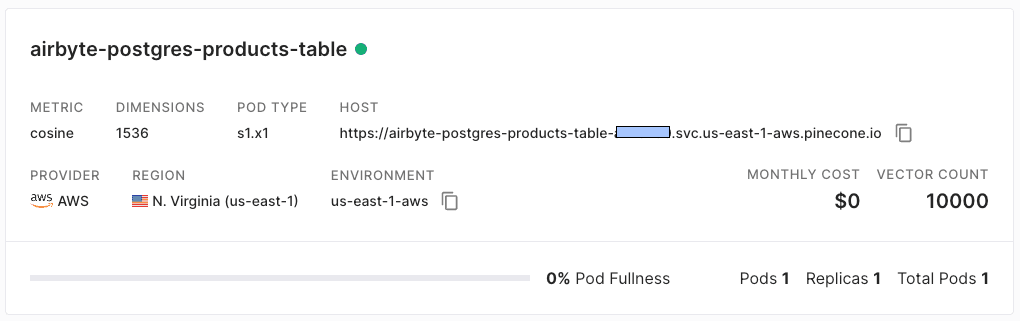
Point the connector to a 1536 dimensions index called airbyte-postgres-products-table , then provide the Pinecone environment and API key.
Create a connection
We’ll start creating a new connection by selecting the Postgres source:
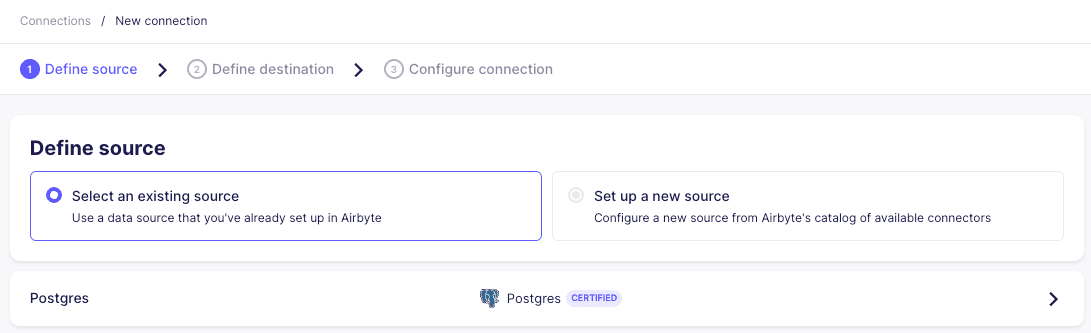
Then select the newly crated Pinecone - Postgres - Products Table destination:
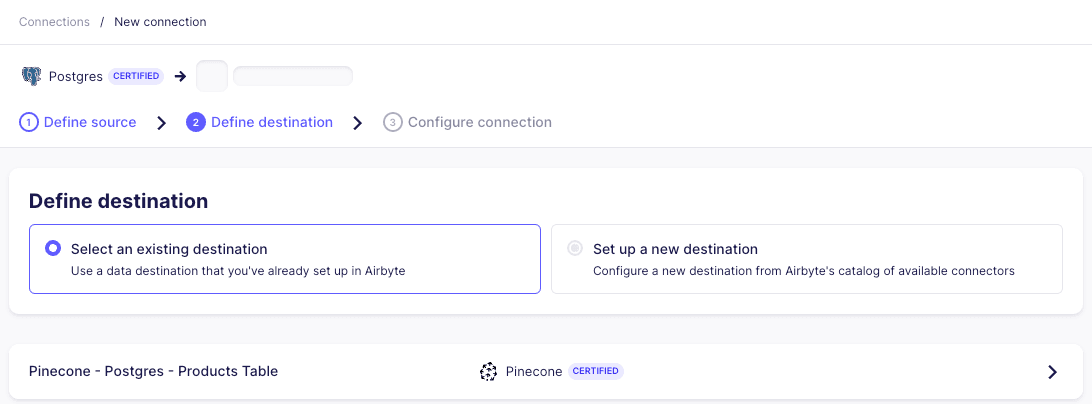
In the next screen, we can set up the desired frequency in which the target table will be synchronized. We’ll also select the specific table in Postgres that we’d like to sync:
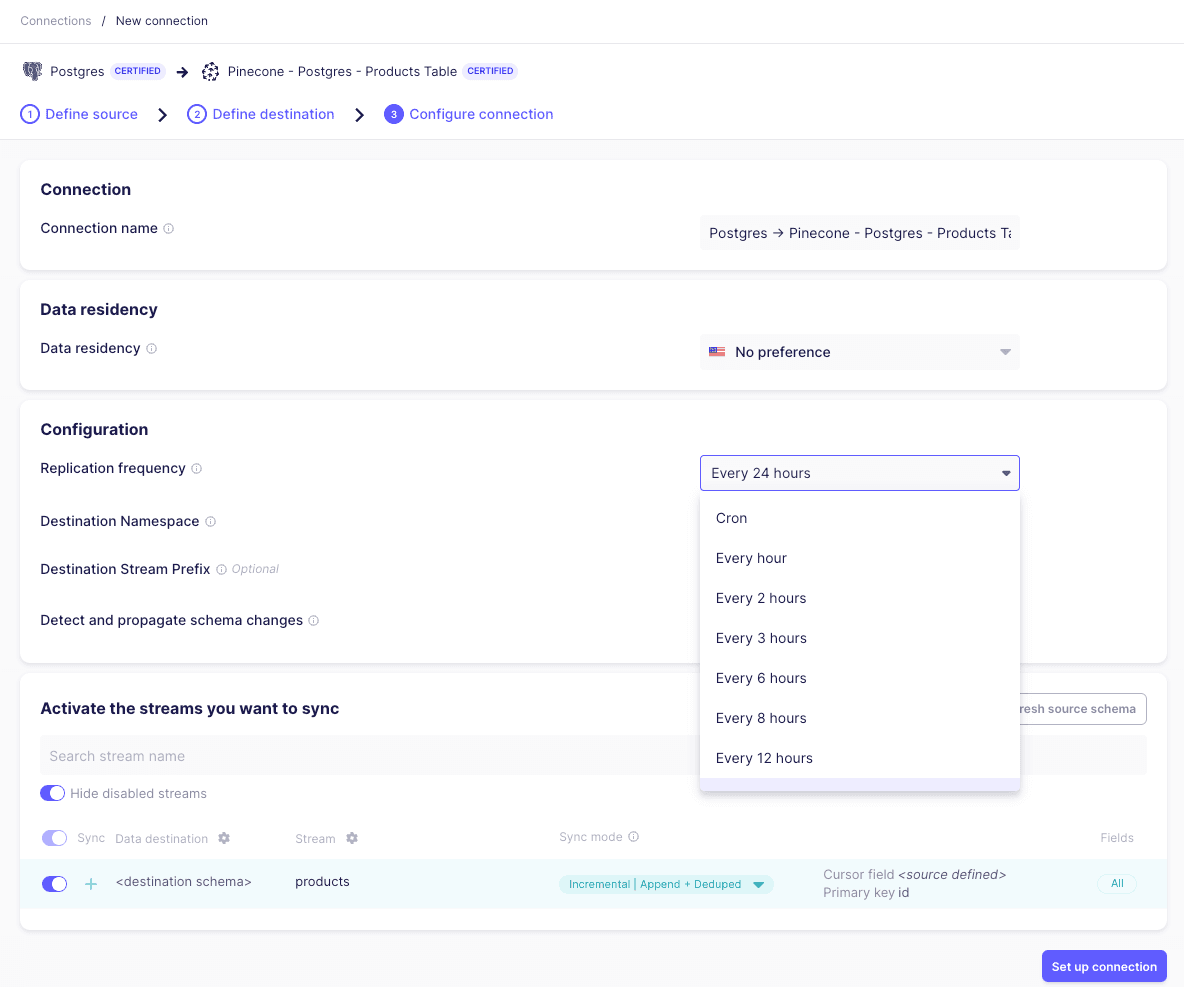
Once our connection is created, we can trigger a manual sync by clicking “Sync now”:
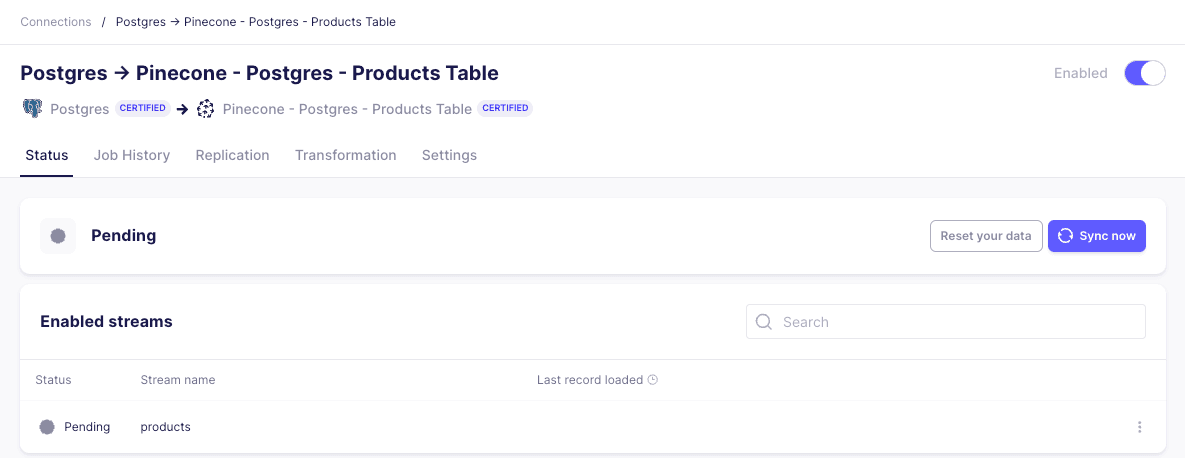
As the connector finishes upserting embeddings into Pinecone, we’ll see the updated vector count in the console:
Testing
To test the integration, we built a semantic search application that searches through the descriptions of each product. We’ll start with a simple search for the term without friction:

Since we’re performing a semantic search (and not just searching for keywords), our results will include entries with the word frictionless - which is semantically equivalent to without friction
Next, we’ll edit the first three entries, and remove the word “frictionless” from the description.

When we query again, the Postgres database has not yet been synchronized - and so the same 3 products still appear for the without friction query - even though the word frictionless doesn’t appear in them. Let’s synchronize the database with Pinecone again.

Once the synchronization has completed, we’ll check out application once again:

This time, as expected, the first 3 original products don’t show up, and instead we get only those which include the term “frictionless”. The Airbyte Postgres connector picked up the changes, and then the Airbyte Pinecone connector re-embedded the changed entries - which eventually resulted in the updated query result.
Conclusion
With Airbyte's connectors, you can easily create embeddings and simplify your data pipeline - without writing a single line of code. Still, this integration will work for both modest and very large datasets, and efficiently keep the your Postgres database and Pinecone index in sync. In the next chapter, we’ll dive into how to use Airbyte with one the most popular document stores: MongoDB.
Was this article helpful?